The article frames realistic mobile environments as the next bottleneck for Mobile Agents.
文章称,Mobile Agent 的下一道瓶颈,可能不是模型本身,而是缺少足够真实又可控的手机环境。
Real apps are realistic, but their state and verification are hard to control.
真实 App 虽然接近目标场景,却很难重置状态,也很难自动验证一次任务到底有没有完成。
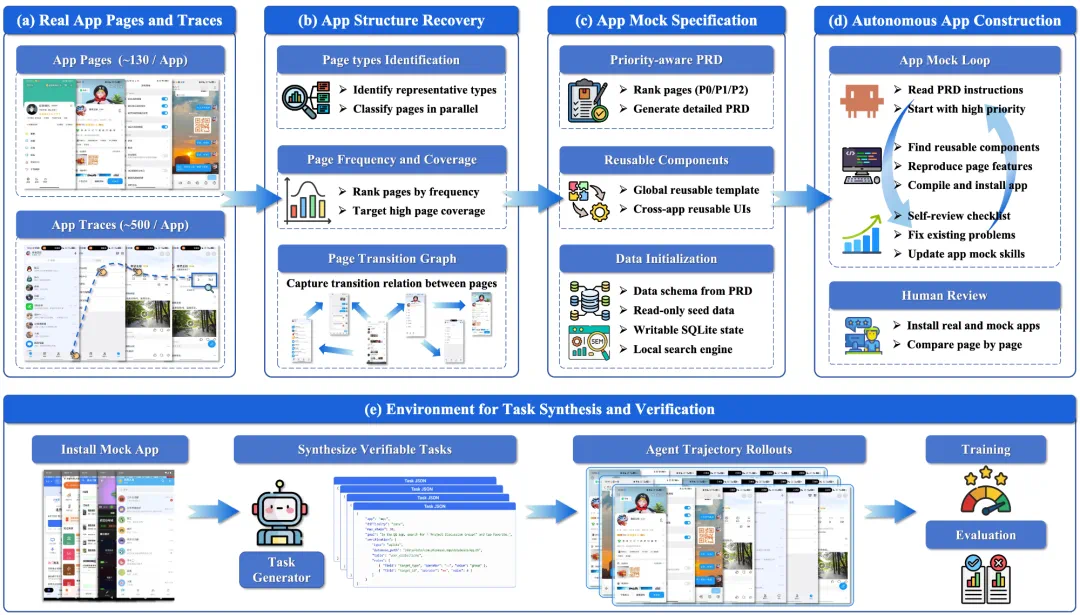
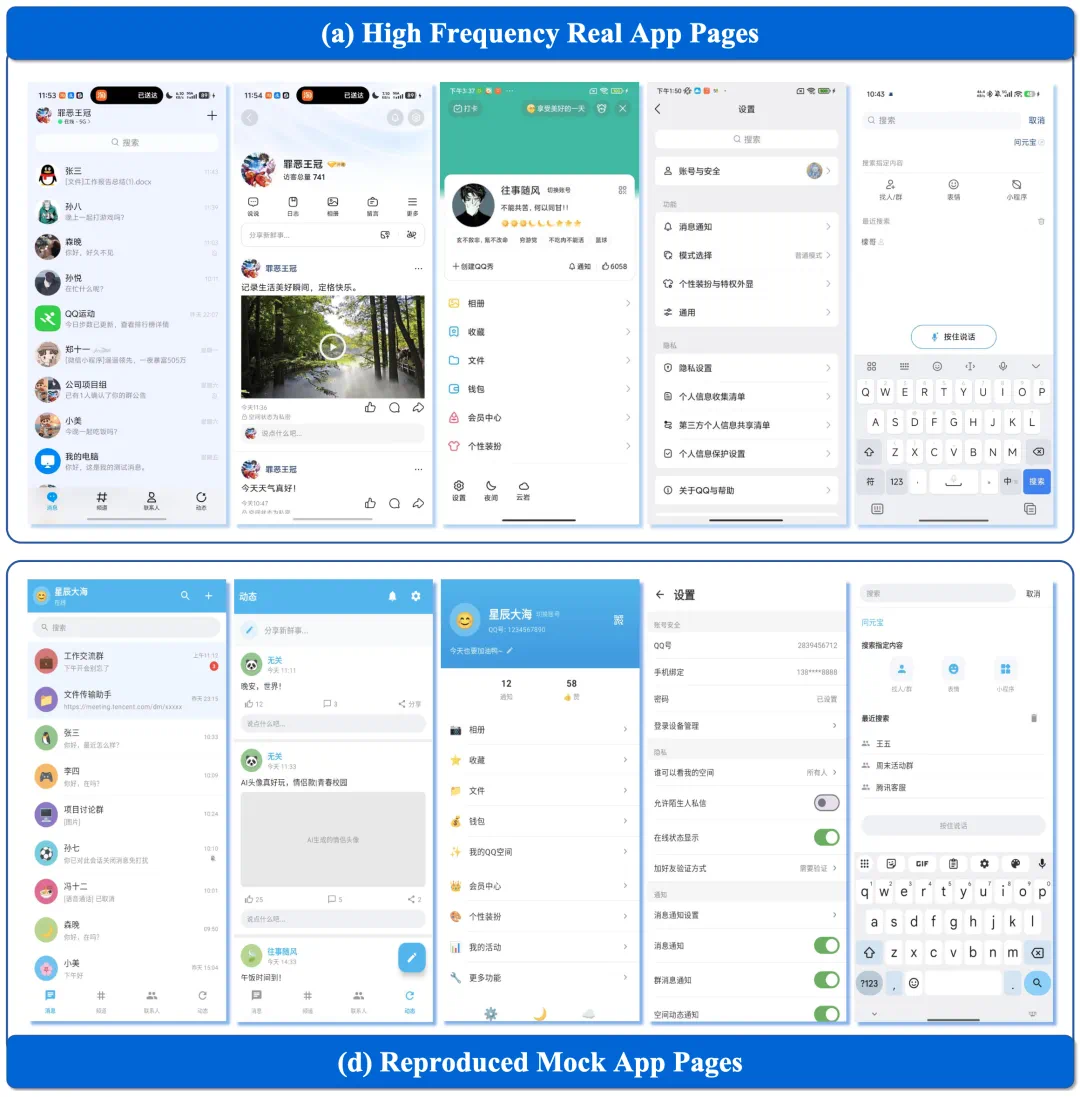
PhoneWorld recovers page structure, navigation, and state changes from real app traces.
PhoneWorld 的做法,是从真实截图和操作轨迹中恢复页面结构、导航路径和状态变化。
Those structures become PRDs, schemas, and components for coding agents to implement.
随后,系统把这些结构转成页面级 PRD、数据 schema 和组件,再交给 coding agent 自动实现 mock Android App。
The goal is not just visual imitation, but reusable functional app skeletons.
这批 App 的重点不是只复刻外观,而是保留真实用户最常经过的页面和可执行交互路径。
Resettable and verifiable tasks make training failures reproducible.
对训练来说,可重置和可验证意味着同一任务可以反复执行,失败也可以被稳定复现。
The core claim is that Mobile Agents need more reliable worlds, not only larger models.
文章的核心判断是,Mobile Agent 要继续 scaling,需要从更大的模型,走向更可靠的世界。
Its importance is moving mobile-agent evaluation toward reproducible infrastructure.
这件事真正重要的地方,是它把手机智能体评测从临时演示,推向可复现的工程基础设施。
The article says AI video generation is moving toward five-minute long audiovisual clips.
文章称,AI 视频生成正在从二十秒以内的样片,卷向五分钟级的长音视频生成。
The old failure mode was identity and voice drift across long clips.
过去的难点是,一拉长到分钟级,同一角色容易跨镜头变脸,声音也可能漂移。
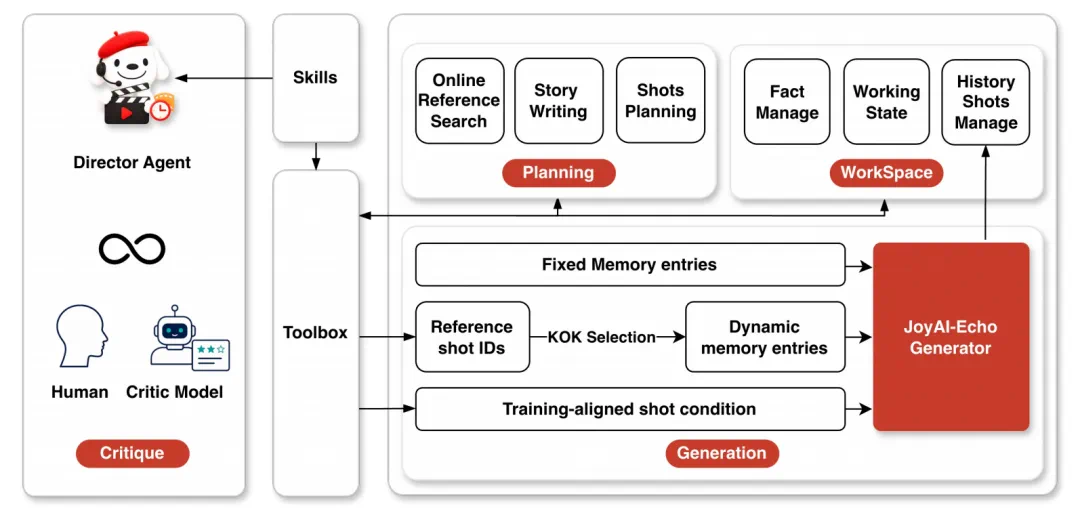
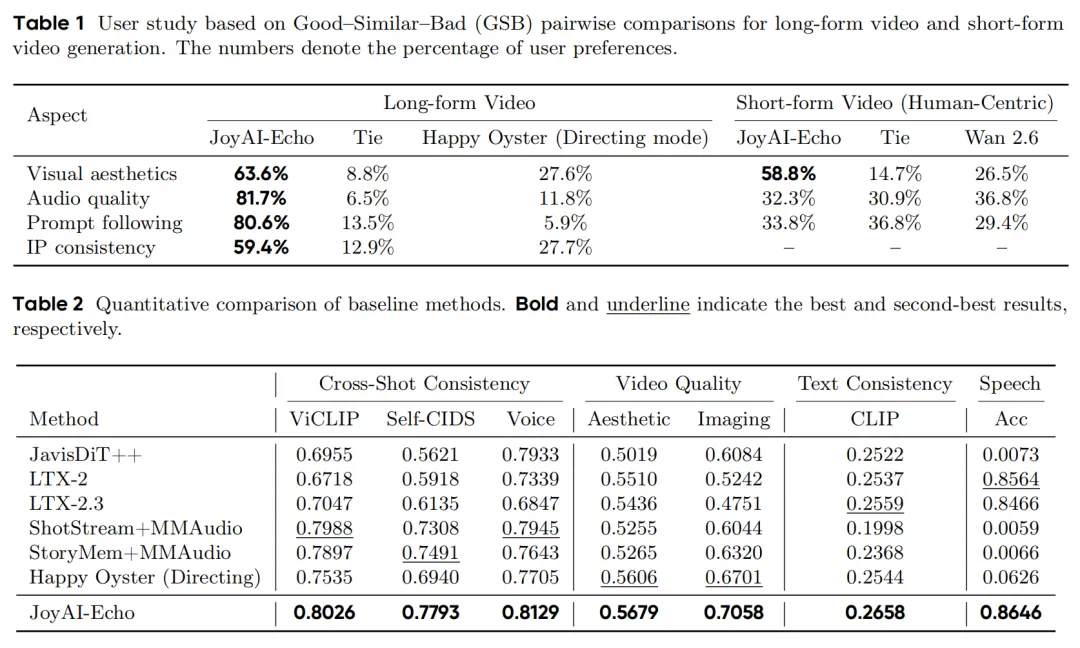
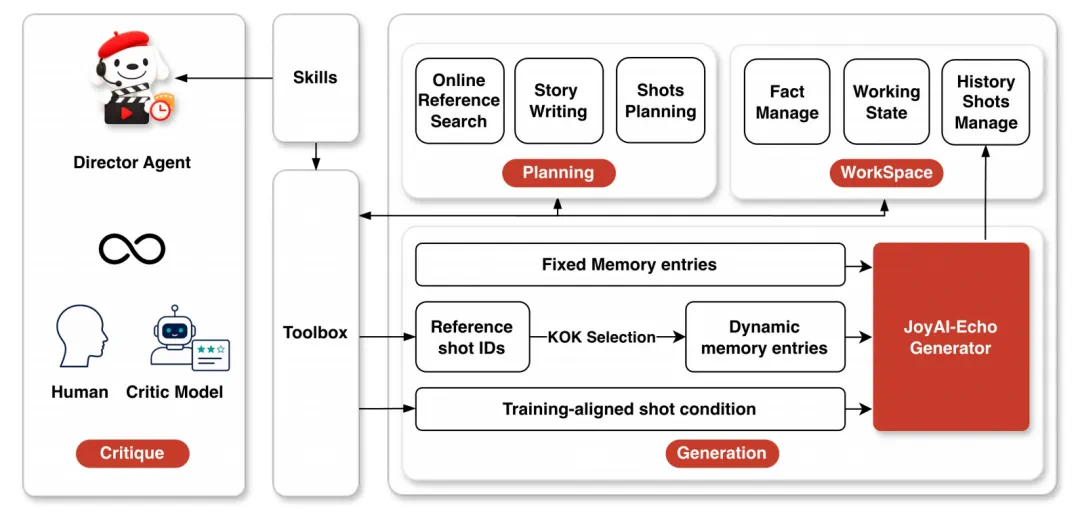
JoyAI-Echo claims one-pass generation up to five minutes with stable identity and voice.
JoyAI-Echo 的核心卖点,是一次生成最长五分钟,并保持角色外观和说话音色稳定。
A dark action sample keeps costume, atmosphere, and rainy texture consistent.
文章展示的黑暗动作片段里,角色服装、城市氛围和雨夜质感在频繁切换中保持统一。
Natural-language local editing reduces the need to rerun an entire video.
另一个关键变化,是用户可以用自然语言做局部修改,不必改一个镜头就重跑整条视频。
The vlog sample stresses natural handheld motion, street scenes, and facial continuity.
vlog 示例强调的是真实感:手持自拍、走路晃动、街景和人物表情需要一起自然过渡。
Talking-head generation must keep face, lip motion, voice, and lighting aligned.
在人物口播场景中,模型还要同时维持面部、口型、语音和室内光照的一致性。
The article also reports real-time super-resolution up to 1472 by 2560 output.
文章还提到两档实时超分,最高可输出 1472×2560 分辨率的视频和精细化音频。
Open code and weights make the system testable beyond a demo page.
代码和权重已经公开,这让 JoyAI-Echo 不只是展示页面,而是可下载验证的开源框架。
If the claims generalize, long-video generation moves closer to professional workflows.
如果这些能力在更多场景中成立,长视频生成就会更接近专业工作流,而不是靠反复抽卡挑结果。
Commercial use still depends on rights, cost, multi-character control, and editing constraints.
不过,文章展示的是研究测评样例,真实商业制作还要看版权、成本、多角色和复杂剪辑约束。
The key point is combining duration, consistency, and editability in one engineering target.
这条新闻的重点,是长视频模型开始把时长、一致性和可编辑性放在同一张工程清单上。
The article says AI math is shifting from proof scarcity to verification scarcity.
文章称,AI 数学正在从证明稀缺,走向证明过剩,真正的瓶颈变成验证和理解。
Princeton researchers present Goedel-Architect, powered by DeepSeek-V4-Flash for Lean proofs.
普林斯顿团队提出 Goedel-Architect,用 DeepSeek-V4-Flash 驱动 Lean 形式化证明流程。
On 672 PutnamBench problems, the article reports a 75.6 percent pass rate.
在 PutnamBench 的 672 道题上,文章称 Goedel-Architect 的通过率达到 75.6%。
The sharper contrast is cost: about 170 thousand dollars versus 294 dollars.
更刺眼的是成本:Hilbert 跑完约需 17 万美元,而 Goedel-Architect 报道成本约为 294 美元。
Lean turns proof steps into machine-checkable logic that a compiler can reject.
Lean 的作用,是把每一步逻辑写成机器可检查的形式,让编译器拒绝有漏洞的证明。
The value is connecting math AI to verifiable and reviewable workflows.
这类系统的价值不只是生成答案,而是把数学 AI 接到可验证、可复核的工作流里。
The reported metrics still depend on versions, budgets, and benchmark coverage.
但通过率和成本还要看模型版本、预算和题目分布,不能直接等同于完全解决数学验证。
The competition is shifting toward low-cost verifiable proof generation.
这条新闻真正指向的是,数学智能体竞争开始从会不会证明,转向能不能低成本地被验证。
The article says Physical AI needs 3D assets that can be simulated and interacted with.
文章称,Physical AI 的关键基础设施,不只是 3D 模型好不好看,而是能不能被仿真和交互。
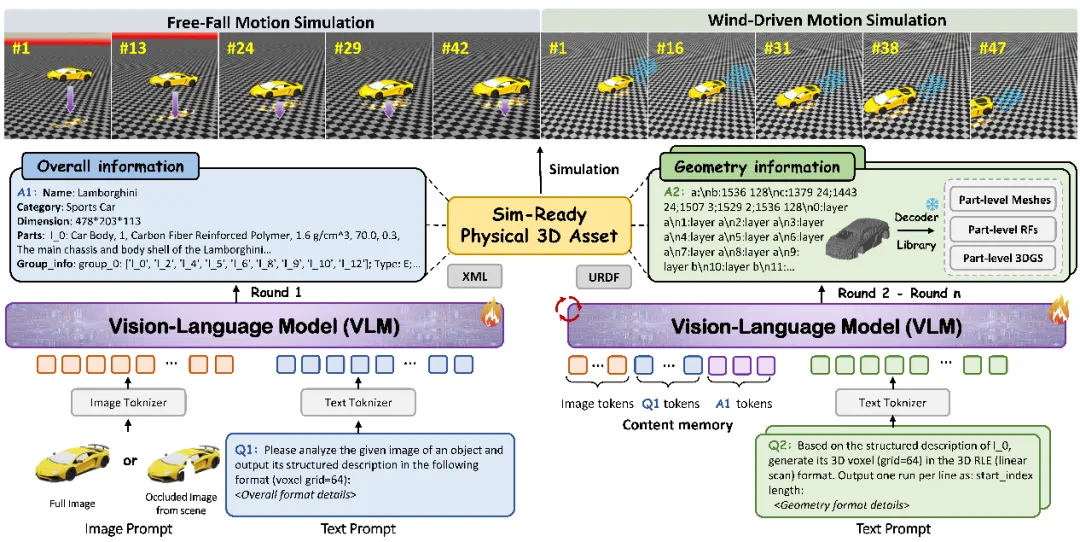
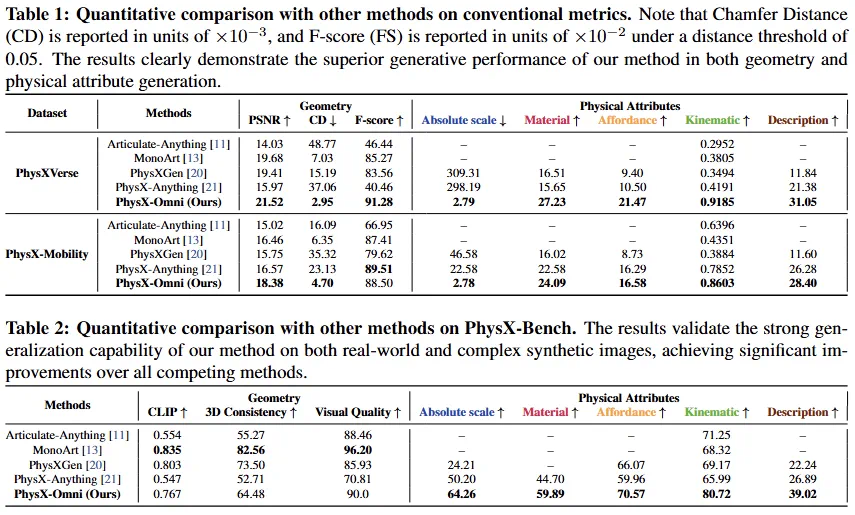
PhysX-Omni unifies rigid, deformable, and articulated object generation.
PhysX-Omni 面向刚体、可形变物体和关节物体,试图把三类物理对象放到统一生成框架里。
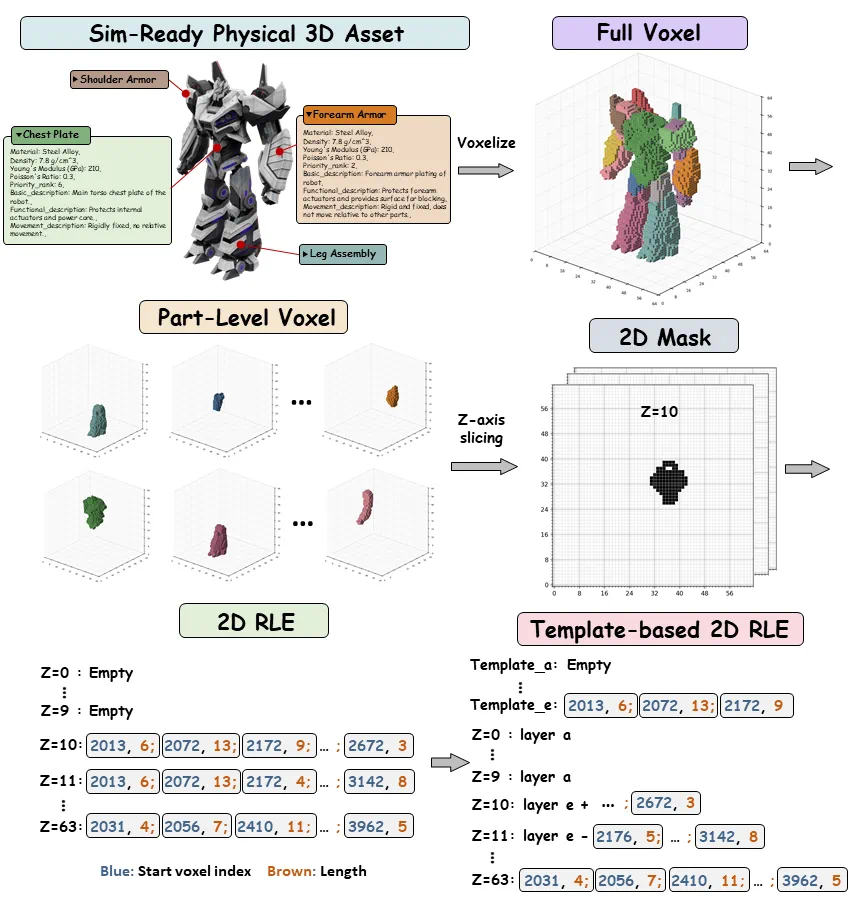
It models scale, material, kinematics, affordance, and semantic descriptions.
它建模的不是单纯外观,还包括绝对尺度、材料、运动学、可供性和语义描述。
The system uses a template-based RLE representation for high-resolution 3D geometry.
文章说,系统采用新的几何表征,用 template-based RLE 高效表示高分辨率三维结构。
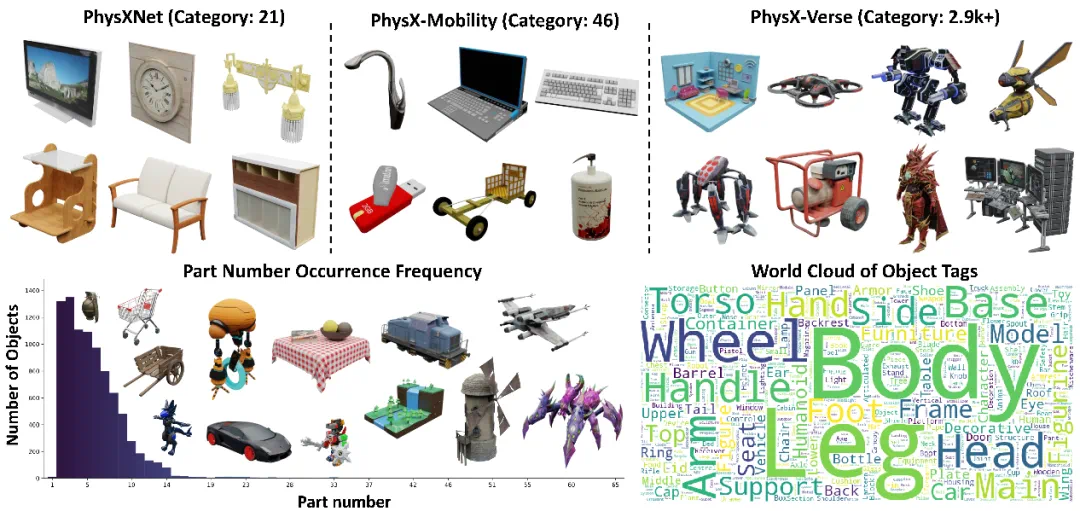
The team also builds PhysXVerse with more than eight thousand physical 3D assets.
为了解决数据稀缺,团队还构建了 PhysXVerse,覆盖超过 8K 个物理 3D 资产。
PhysX-Bench evaluates geometry, scale, material, affordance, kinematics, and semantics.
PhysX-Bench 则从几何、尺度、材料、可供性、运动学和语义描述等维度评估生成结果。
Robotics benefits when assets have physical properties close enough for simulation.
这对机器人很重要,因为可用资产越接近真实物理,仿真训练和世界模型才越有基础。
Real deployment still depends on sim-to-real gaps and complex task support.
不过,真正落地还要看仿真到现实的差距,以及这些资产能否支撑复杂机器人任务。
CVPR 2026 announced awards, submissions data, and test-of-time recognitions.
CVPR 2026 公布获奖论文,文章把奖项、投稿数据和时间检验奖放在一起做了现场报道。
The conference received 16,092 submissions and accepted 4,071 papers.
今年大会收到 16092 篇投稿,接收 4071 篇,接收率为 25.3%。
The article reports a 23.71 percent increase in paper count from last year.
文章还提到,今年论文数量比去年增长 23.71%,视觉研究规模继续扩大。
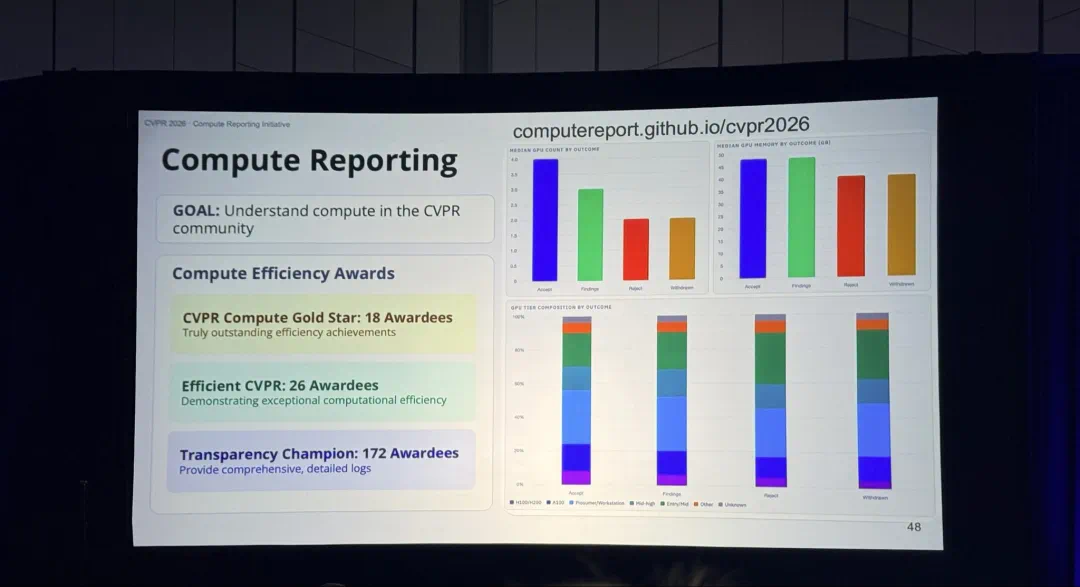
Compute statistics show heavy GPU use, especially in industry.
算力统计也被单独展示,文章说如今视觉研究已经是人均多块 GPU、工业界消耗更高。
The best paper selection came from 74 nominees and 15 finalists.
最佳论文奖最终从 74 篇入围、15 篇决赛论文中产生,获奖方向包括动态场景重建。
ResNet receives a test-of-time award, underscoring its lasting role in deep vision.
更有历史感的是,何恺明参与的 ResNet 获得时间检验奖,说明残差网络仍是深度视觉的底层建筑。
YOLO also receives recognition for its long-term impact on real-time detection.
YOLO 也获得时间检验奖,代表目标检测从研究原型走向实时系统的长期影响。
New awards show the frontier, while test-of-time awards show what changed vision AI.
这条新闻的重点是,新奖项看前沿,时间检验奖则告诉我们哪些基础技术真正改变了视觉 AI。
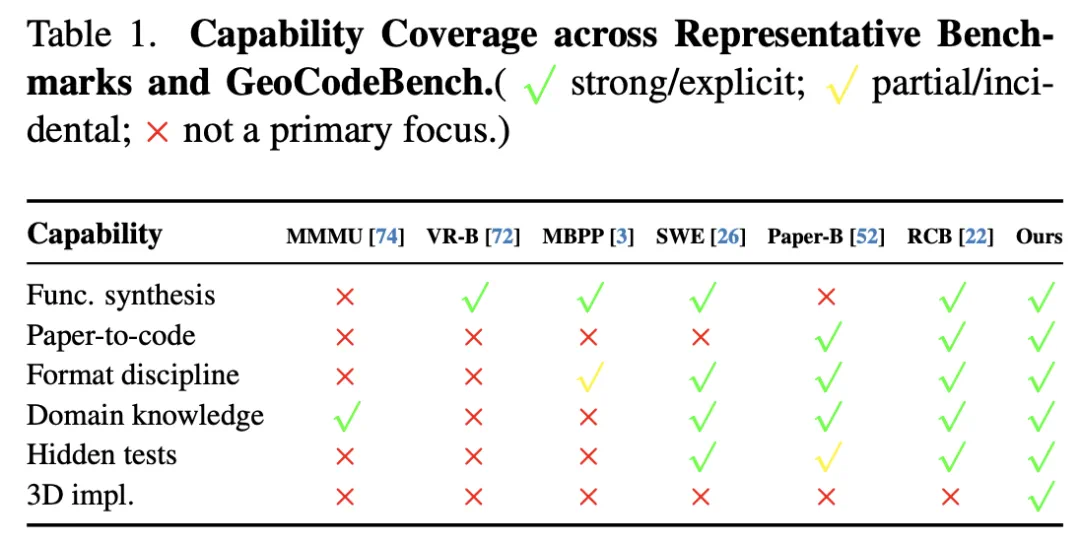
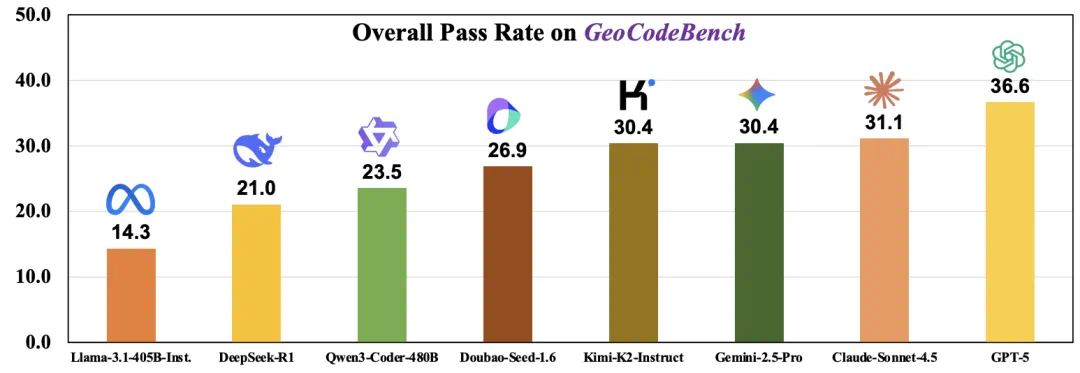
GeoCodeBench asks whether LLMs can turn 3D vision papers into executable code.
GeoCodeBench 问的是一个更难的问题:大模型能不能把 3D 视觉论文真正写成可执行代码。
The benchmark includes 47 repositories and 100 problem instances.
这个基准来自清华 AIR、北京智源、北大、南大等团队,包含 47 个仓库和 100 个问题实例。
In the original evaluation, GPT-5 reaches only a 36.6 percent overall pass rate.
论文原始评测里,即便是当时最强的 GPT-5,整体通过率也只有 36.6%。
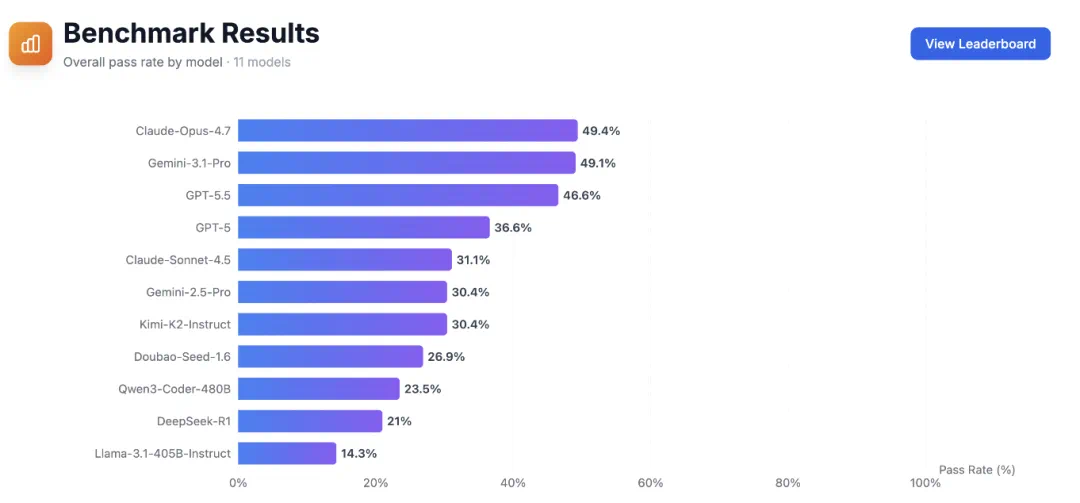
The latest leaderboard reports Claude Opus 4.7 leading at 49.4 percent.
最新 leaderboard 中,文章称 Claude Opus 4.7 以 49.4% 通过率排在第一。
The takeaway is that research-grade geometry coding still requires deep paper understanding.
这说明研究级几何代码仍然很硬,模型不仅要会写程序,还要读懂论文里的公式、约束和边界条件。
A student-led ChordEdit paper is accepted as a CVPR Oral and nominated for best student paper.
一篇本科生主导的 ChordEdit 论文,中稿 CVPR Oral,并拿到最佳学生论文提名。
ChordEdit claims model-agnostic, training-free, inversion-free one-step image editing.
文章称,ChordEdit 提出模型无关、无需训练、无需反演的一步式高保真图像编辑方法。
The striking contrast is that experiments reportedly ran on an older NVIDIA Titan 24GB GPU.
更有反差的是,作者说实验主要跑在一块 2018 年发布的 NVIDIA Titan 24GB GPU 上。
Against rising CVPR compute use, the paper stands out.
在 CVPR 算力消耗不断上涨的背景下,这篇论文显得很不一样。
The story is low-cost method design, a young lead author, and top-conference recognition.
这条新闻的看点,是低成本方法、年轻作者和视觉编辑效果,一起拿到了顶会认可。