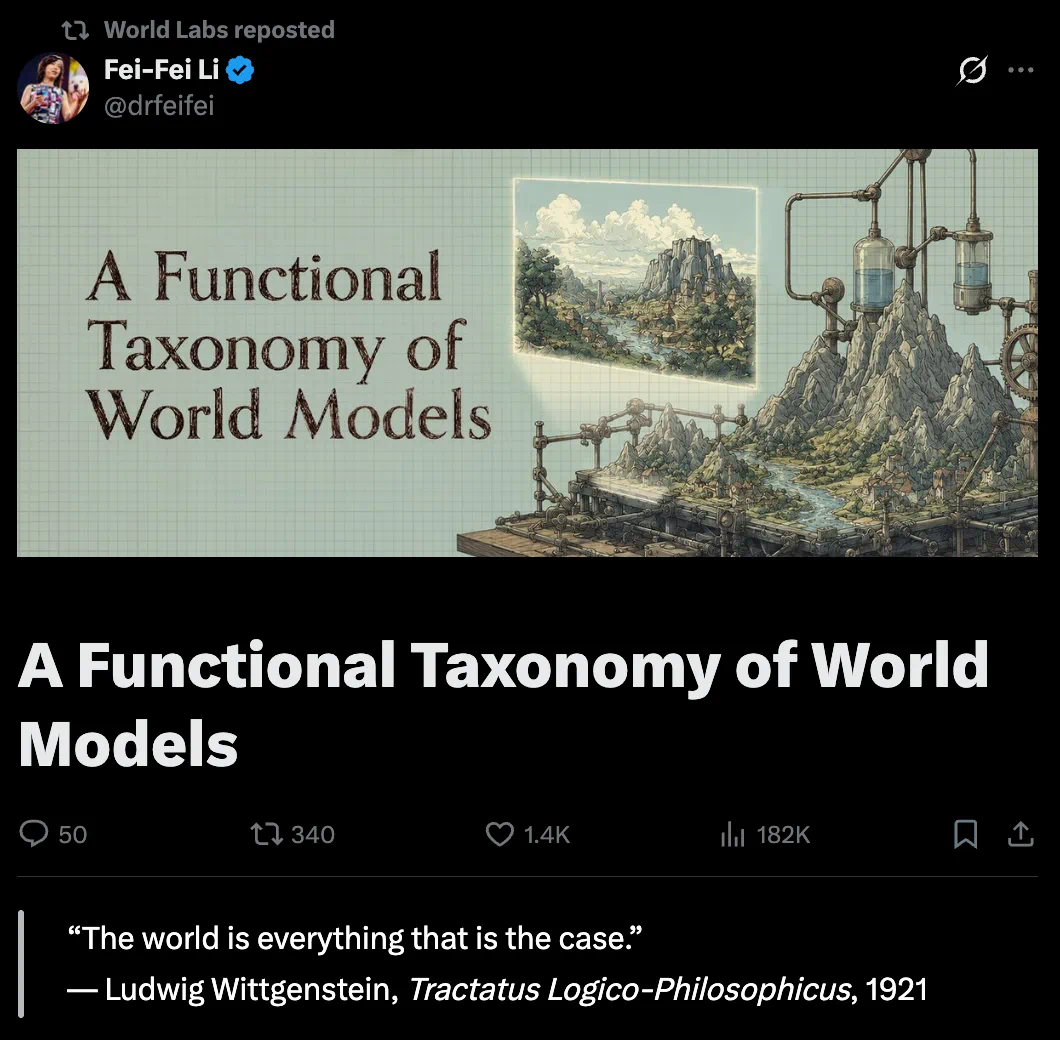
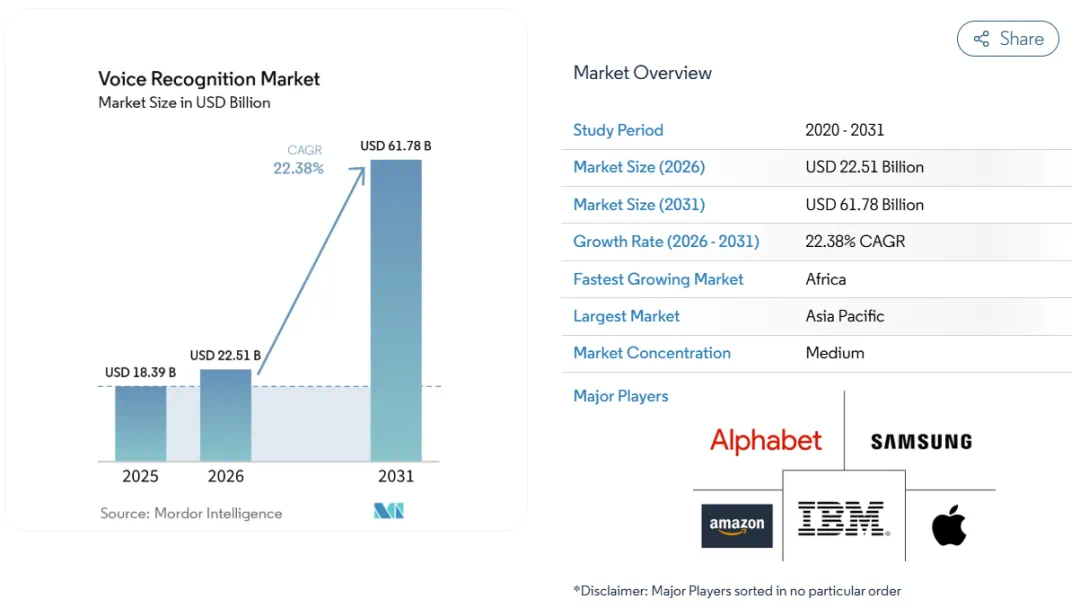
This story asks what the term world model really means.
李飞飞这篇整理想解决的,是世界模型这个词到底在说什么。
The article says video generation, robotics, reinforcement learning, and simulation use the same term differently.
文章指出,现在视频生成、机器人、强化学习和物理仿真都在使用同一个词,但含义并不相同。
A model that generates realistic fire may not understand the physics of fire.
一个能生成漂亮火焰的视频模型,未必理解火焰的物理过程。
Robots need to know how the environment changes and what actions cause.
而机器人真正需要的,是知道环境状态如何变化,以及行动会带来什么后果。
The key is separating visual realism, physical consistency, interactivity, and planning.
所以报道里的重点,是把视觉逼真、物理一致、可交互和可规划这几件事分开。
For embodied AI, evaluation cannot stop at visuals; it must test action support.
这对具身智能很关键,因为机器人评测不能只看画面,也要看模型是否支持真实行动。
The signal is a shift from realistic video to usable world representations.
文章的信号是,世界模型竞争会从谁的视频更像,走向谁的世界表示更能用。
The caveat is that definitions need validation in interactive and robotic tasks.
但这仍是定义层面的澄清,最终还要靠可交互任务和机器人控制结果来验证。
Google I/O launched Gemini Omni Flash, but the article argues the biggest winner may not be Google.
谷歌 I/O 发布了 Gemini Omni Flash,但文章的标题说,最大赢家可能不是谷歌。
Gemini Omni Flash supports multimodal inputs for video generation and continuous editing.
Gemini Omni Flash 支持视频、图像、音频、文本和草图输入,用自然语言生成和连续编辑视频。
A medical sample puts a knee model and doctor explanation into one generated scene.
医疗样例里,模型把膝盖结构和医生讲解放进同一个生成视频场景。
The article stresses real-world understanding beyond stitching images together.
文章还强调模型要理解现实世界,不只是拼接画面,也要给出背景、物理和文化语境。
Another sample places a presenter into a realistic street scene.
另一类样例是人物和地点的真实感生成,把讲解者放到街景中。
Digital avatar and character consistency are also central capabilities.
数字分身和角色一致性也是重点,视频里同一角色短时间内保持外观和表情连贯。
A longer editing sample keeps a person across climbing, street, detective, and pet scenes.
更长的连续编辑样例展示同一个人物跨攀岩、街头、侦探和宠物场景切换。
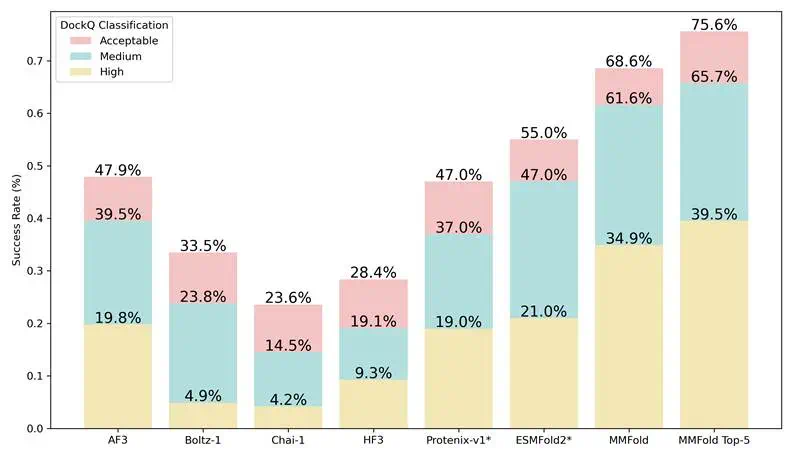
The article's main comparison is Seedance 2.0 versus Google Omni Flash.
但文章真正想比较的是 Seedance 2.0 和 Google Omni Flash 的公开样例。
The comparison video puts action, cars, airports, and close-ups side by side.
对比视频里,动作、汽车、机场和人物近景都被放到上下两路画面里直接比较。
The anime sample shows the competition spans styles and camera language, not only realism.
动漫风格样例说明,竞争不只在真实感,也在不同视觉风格和镜头语言。
Action scenes test body motion, contact, and camera stability.
动作场景则考验身体运动、接触关系和镜头稳定性。
A crowd event sample tests multiple subjects, occlusion, and continuous motion.
还有一段人群和活动场景,重点是多主体、遮挡和连续运动是否稳定。
Google's counterweight is SynthID watermarking for provenance checks.
谷歌的防线之一是 SynthID 水印,文章称生成视频内嵌不可见水印,方便验证来源。
A short clip shows action generation.
短片展示了动作生成能力。
The caveat is that these samples are not a strict benchmark.
不过这些样例还不是严格基准,真实能力仍要看统一提示、成本、时长和版权治理。
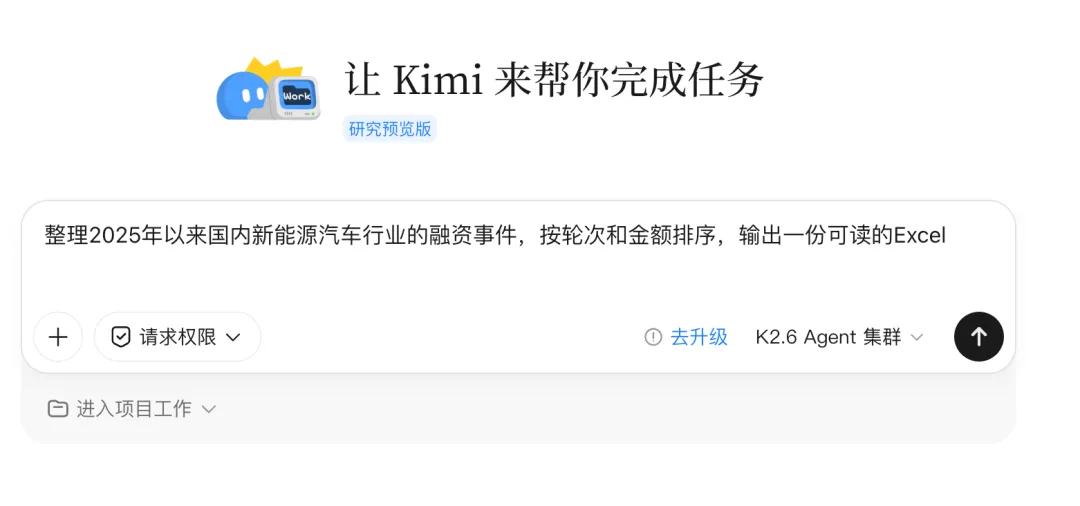
After Vibe Coding, the next term may be Vibe Working.
Vibe Coding 之后,文章说下一个词可能是 Vibe Working。
The background is Codex moving into ChatGPT and knowledge workers entering agent platforms.
背景是 Codex 将并入 ChatGPT,知识工作者正以很快速度进入 Agent 平台。
The fastest-growing group is not only programmers but office workers doing reports and slides.
文章称,增长最快的不是程序员,而是做报告、数据和 PPT 的普通白领。
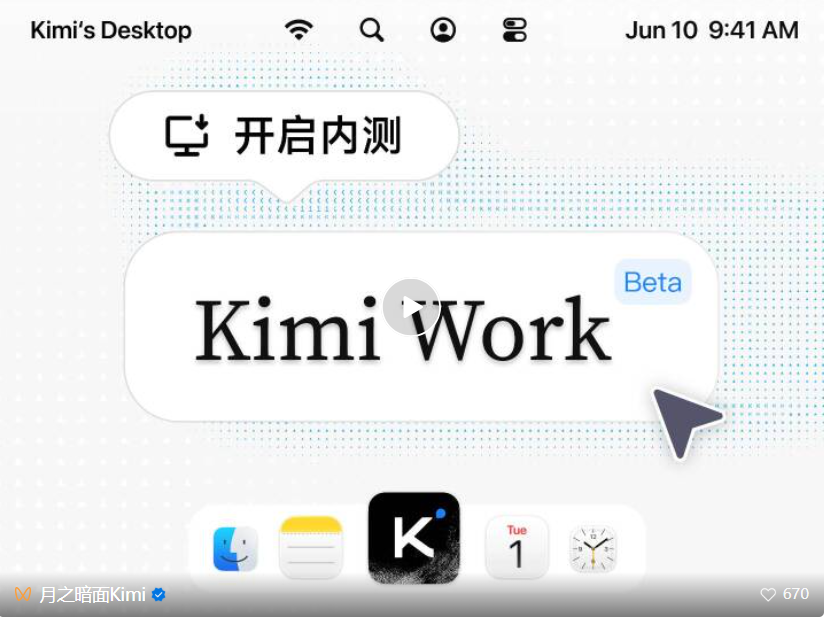
Moonshot's Kimi Work is positioned as a local general agent mode for this trend.
月之暗面推出的 Kimi Work,就是这条趋势下的本地通用 Agent 模式。
It targets files, analysis, workflow automation, and deliverables beyond code.
它面向的不是写代码本身,而是整理文件、分析材料、自动化工作流和生成交付物。
The GIF makes the mode look more like a desktop work assistant than a chat box.
动图里可以看到,Agent 模式更像桌面工作助手,而不是传统聊天窗口。
That explains why enterprise agents are competing for the office-worker entry point.
这也解释了为什么企业 Agent 不只来自 OpenAI,Anthropic、Kimi 这类产品也在抢白领入口。
The caveat is permissions, file safety, recovery, and real task success rate.
但真正落地还要看权限、文件安全、任务恢复和实际成功率。
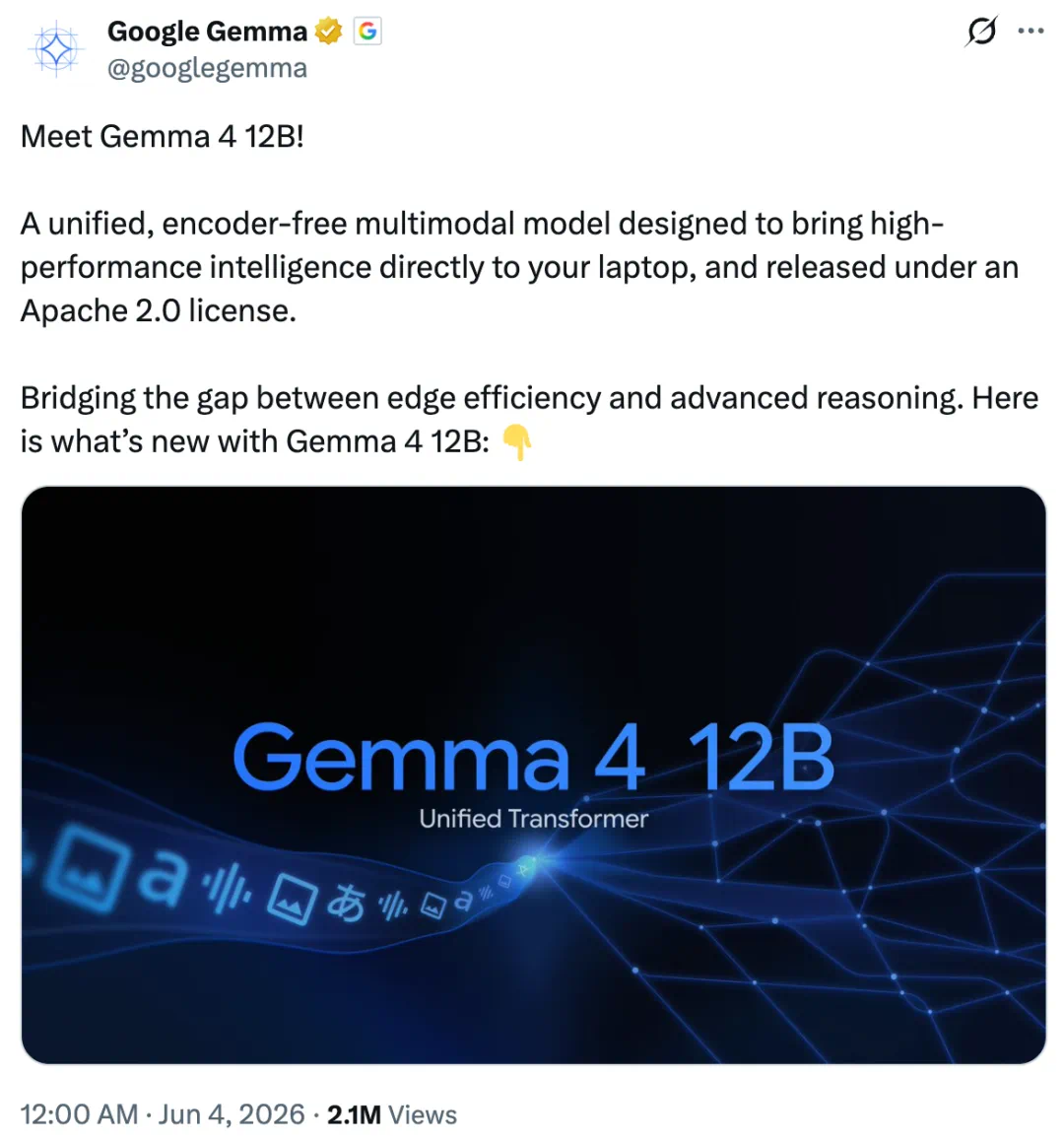
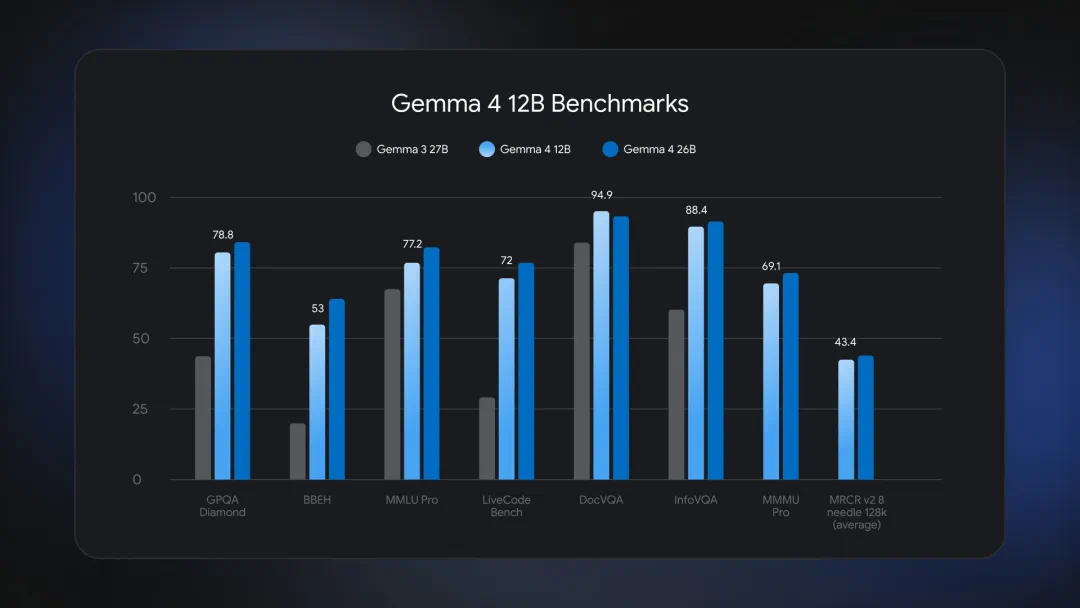
Gemma 4 12B aims to bring multimodal agent capability to laptops.
Gemma 4 12B 的卖点,是把多模态智能体能力带到普通笔记本上。
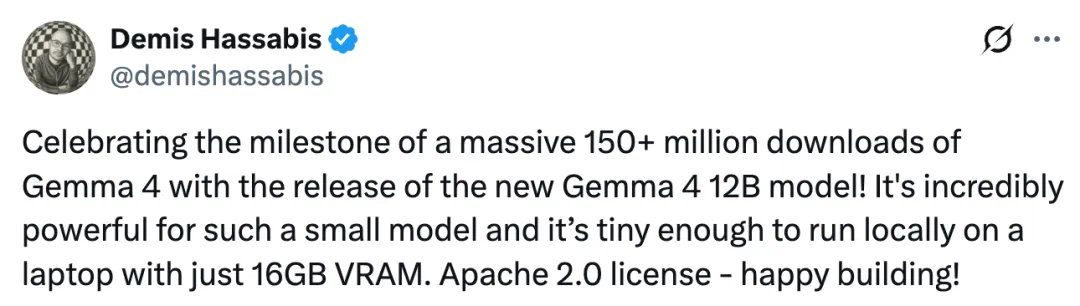
The article says Gemma passed 150 million downloads and added a 12B model.
文章称,Gemma 系列下载量突破 1.5 亿次,谷歌借这个节点推出新的 12B 成员。
It sits between edge E4B and 26B MoE models with a smaller memory target.
它介于边缘 E4B 和 26B MoE 之间,目标是在较小内存里提供更强能力。
The article emphasizes native audio input for a mid-sized Gemma model.
文章特别强调,这是谷歌首个支持原生音频输入的中等规模模型。
The UI demo shows local tasks, transcription, summarization, and editing.
视频里的界面展示了本地任务、转写、摘要和编辑,不只是静态问答。
It uses a unified architecture where vision and audio feed the LLM backbone.
它还采用统一架构,让视觉和音频输入可以进入 LLM 主干,而不是依赖传统多模态编码器。
If 16GB local running works well, desktop agents can rely less on cloud services.
如果 16GB 本地运行成立,桌面 Agent 可以更少依赖云端,也更容易处理隐私敏感任务。
The caveat is quantization, hardware, latency, and task complexity.
但真实体验还要看量化、硬件和延迟,12B 不会自动解决所有复杂任务。
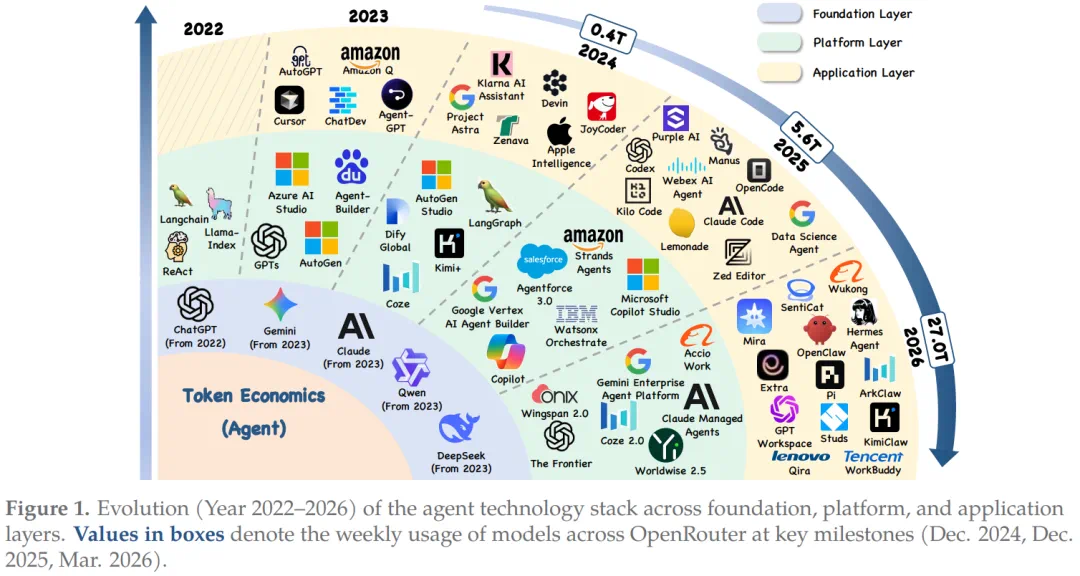
Token Economics reframes agent cost from engineering to economics.
Token 经济学这篇综述,把 Agent 的成本问题从工程层面推到经济层面。
Modern agents spend many tokens on memory, planning, tools, and self-correction.
文章说,现代 Agent 的记忆、规划、工具调用和自我修正,会让一次任务消耗大量 Token。
The article cites weekly token volume rising from 0.4 trillion to 27.0 trillion.
OpenRouter 数据被报道为,周 Token 处理量 15 个月内从 0.4 万亿涨到 27.0 万亿。
The paper defines tokens as production factor, exchange medium, and accounting unit.
论文把 Token 重新定义为生产要素、交换媒介和记账单位。
Inference optimization also becomes pricing, budgeting, and governance.
这意味着推理加速不只是快不快,还要回答谁付费、怎样分配预算、怎样治理滥用。
Multi-agent systems add communication, coordination, and security costs.
在多 Agent 系统里,协作会带来额外通信和协调成本,安全防御也会消耗隐藏预算。
The value is a shared language for pricing, scaling, and governing agentic AI.
文章的价值,是给 Agentic AI 提供一套可定价、可扩展、可治理的共同语言。
The caveat is that token value and risk differ across platforms.
但它仍是综述框架,不同平台上一个 Token 的价值和风险还需要重新标定。
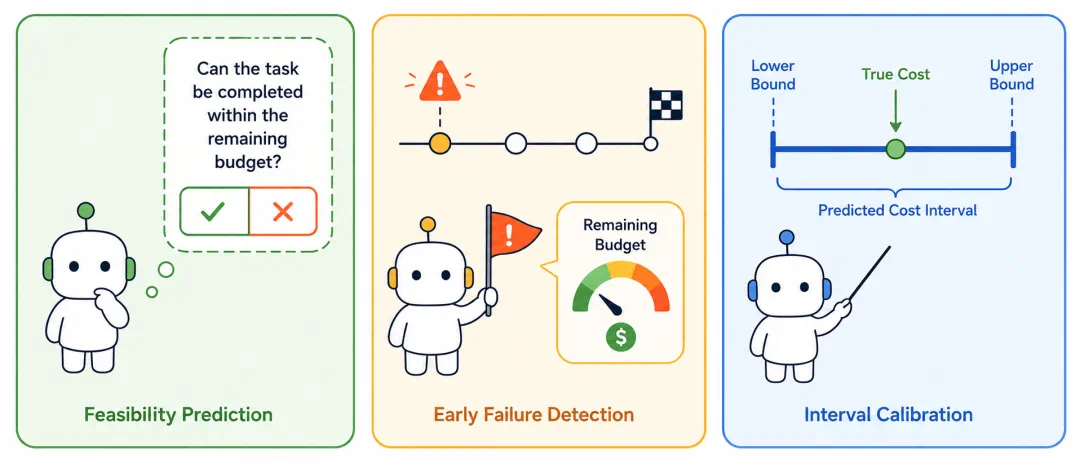
BAGEN asks whether agents know how much they will spend.
BAGEN 研究问的是,Agent 会做任务,是否也知道自己要花多少钱。
The article splits cost into internal model budget and external action budget.
文章把预算分成两类:模型生成消耗的内部预算,以及环境行动承诺的外部预算。
The study uses rollout-replay across four environments and five frontier models.
研究用 rollout-replay 协议,在四个环境和五个前沿模型上评估预算意识。
The core finding is that task ability and cost awareness are not the same thing.
结论方向是,任务能力和成本感知并不是同一件事。
For companies, cost limits and ROI management need agents that understand cost.
这对企业很直接:没有成本感知,Token 上限和 ROI 管理很难真正自动化。
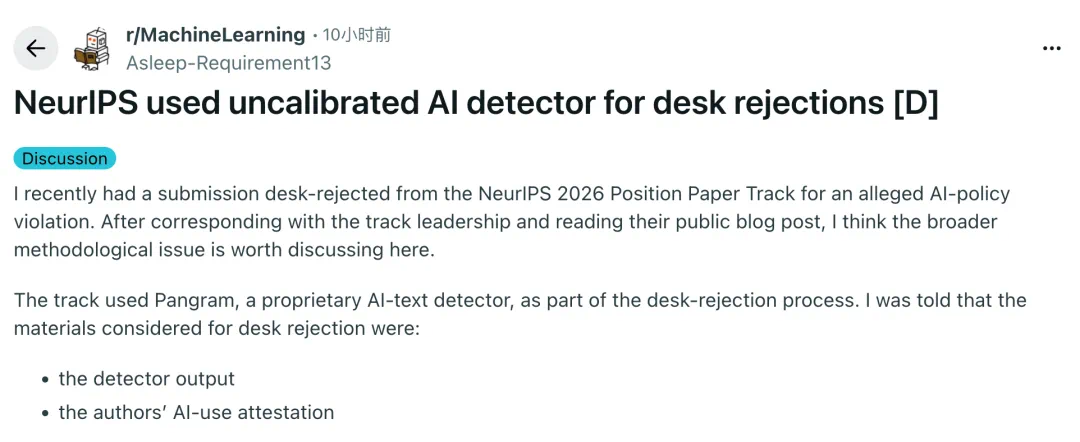
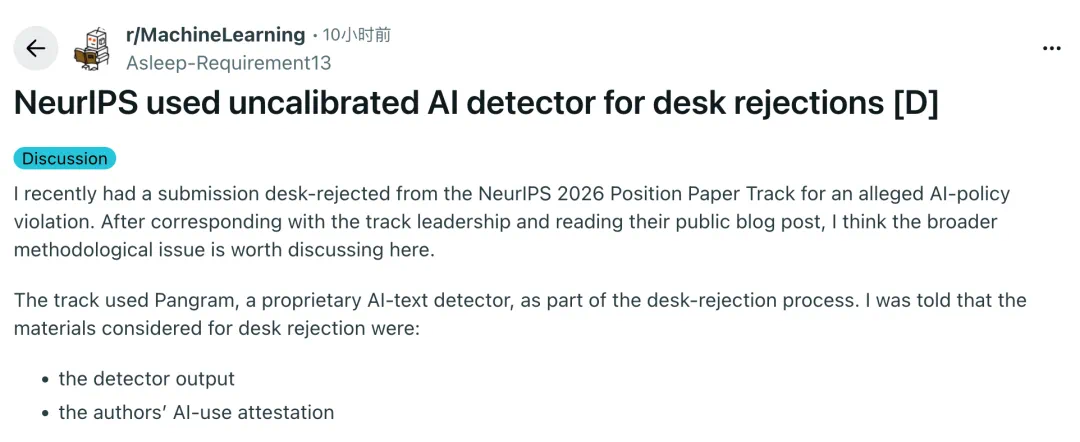
The NeurIPS controversy is about AI detectors entering the rejection process.
NeurIPS 这条新闻的争议点,是 AI 检测器进入了拒稿流程。
The poster says their position paper was desk rejected for alleged AI-use policy violations.
发帖人称,自己的 Position Paper 投稿因为所谓违反 AI 使用政策被直接拒稿。
The article says the process used Pangram, a closed AI text detector.
文章称,这个流程使用了 Pangram,一个闭源 AI 文本检测器。
If detector scores judge inconsistency and inconsistency justifies rejection, the logic can become circular.
问题在于,如果高检测分数被用来判断声明不一致,再用声明不一致证明拒稿,就可能形成循环论证。
The blog mentions audits, but real submissions lack writing-process ground truth.
NeurIPS 博客提到做过审计和测试,但投稿真实写作过程本身并没有 ground truth。
The key question is whether the closed detector is a signal or a de facto judge.
这让闭源检测器的角色变得敏感:它到底是辅助信号,还是事实上的裁决者。
For conferences, transparent process matters more than one detector score.
对学术会议来说,AI 辅助写作已经很难完全禁止,透明流程比单一检测分数更重要。
The caveat is that the specific case needs official clarification.
但具体个案仍要等官方说明,报道目前更多呈现的是制度风险。
This paper asks whether PDFs still make sense if AI writes and reads research.
这篇文章抛出的问题很激进:如果论文主要由 AI 写、由 AI 读,还需要 PDF 吗。
The author team includes 37 researchers from Stanford, Michigan, CMU, MIT, and others.
作者团队有 37 人,来自 Stanford、Michigan、CMU、MIT 等机构。
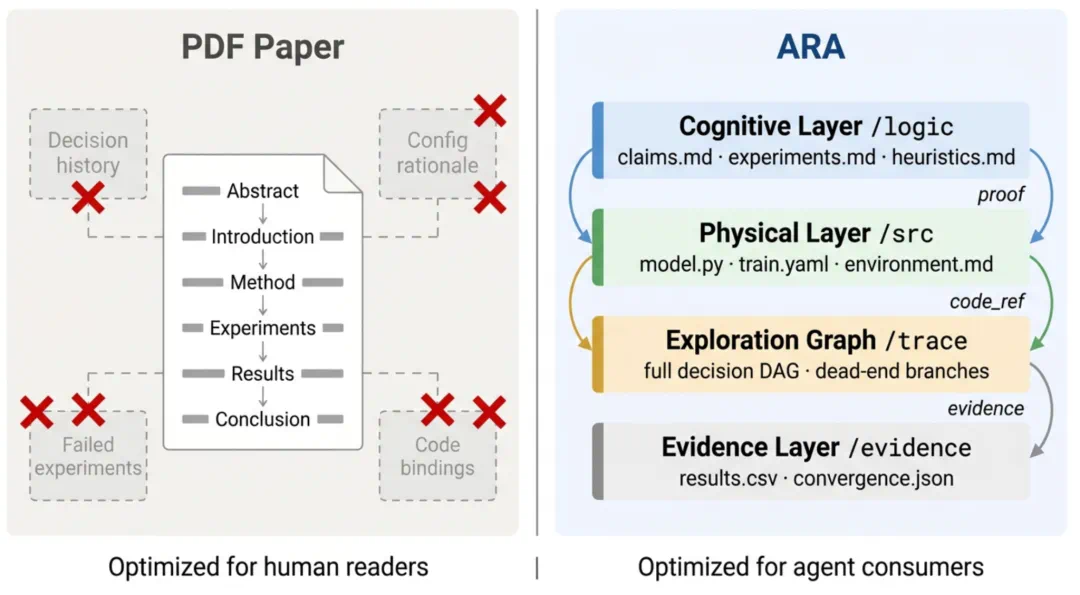
They argue PDFs are designed for human cognition, while AI scientists need executable objects.
他们认为,PDF 是为人类认知带宽设计的,但 AI 科学家需要可执行、可检查的研究对象。
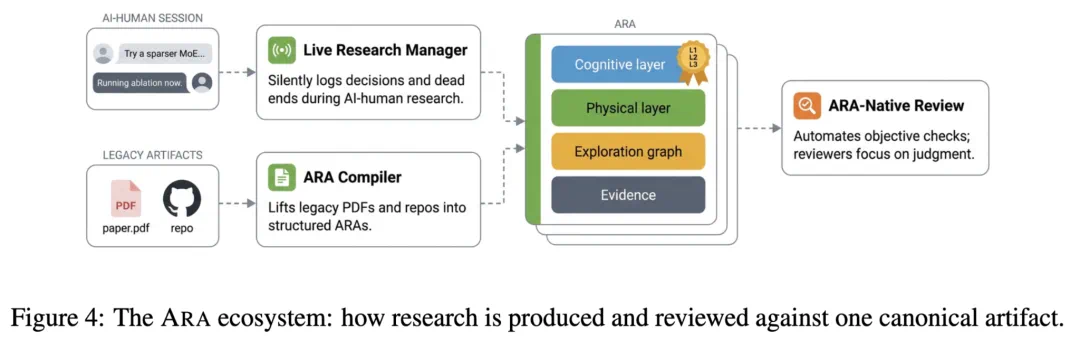
Agent-native artifacts package questions, code, data, experiments, and review signals.
Agent-Native Research Artifacts 想把问题、代码、数据、实验和评审线索组织成研究包。
Then AI can run experiments, check dependencies, and trace results, not just read abstracts.
这样 AI 不只是读摘要,而是可以直接运行实验、检查依赖、追踪结果。
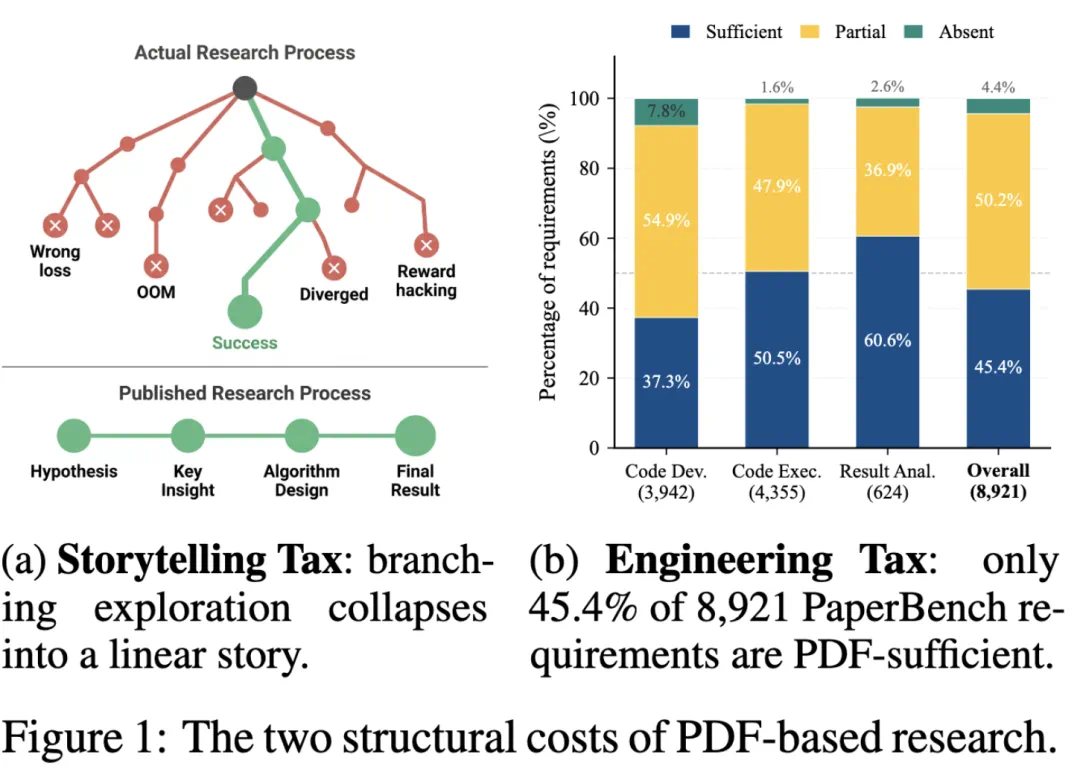
For review, reproduction could become a more automated verification process.
对评审来说,这可能让复现从人工阅读变成更自动化的验证过程。
The caveat is standards, versioning, safe execution, and audit responsibility.
但这也带来新问题:格式标准、版本控制、安全执行环境和审计责任都要重新设计。
It is more of a research-infrastructure manifesto than an immediate end to PDFs.
所以它更像一份科研基础设施宣言,而不是说 PDF 明天就会消失。
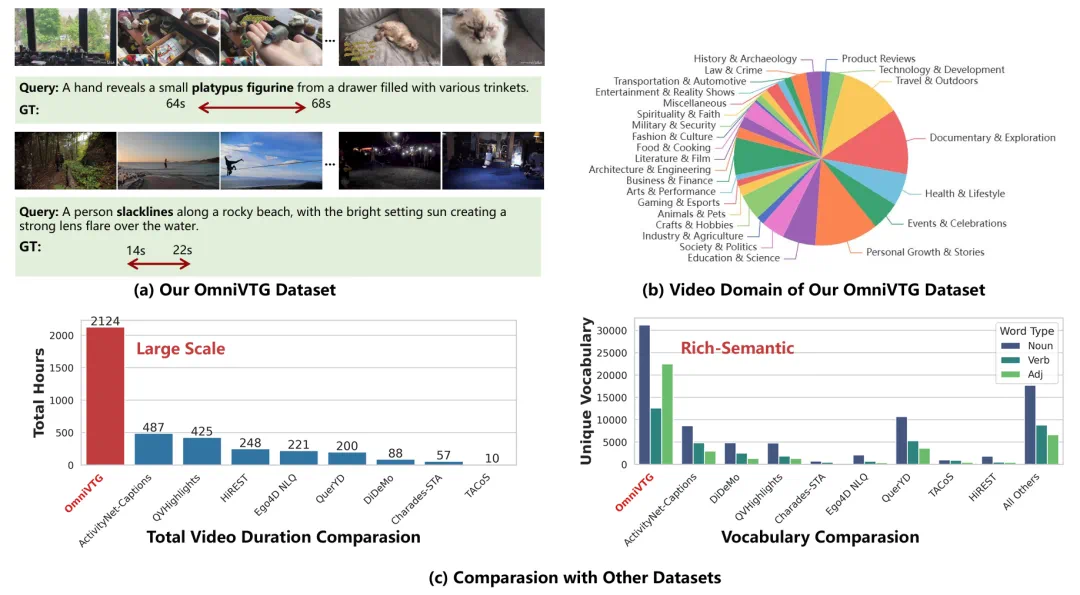
OmniVTG targets semantic blind spots in open-world video temporal grounding.
OmniVTG 关注的是开放世界视频时序定位里的语义盲区。
The task locates event start and end times in untrimmed video from language queries.
任务本身是根据自然语言查询,在未剪辑视频里定位事件起止时间。
The article says narrow datasets cause failures on rare concepts.
文章说,现有数据集词汇覆盖窄,面对罕见概念时模型容易失效。
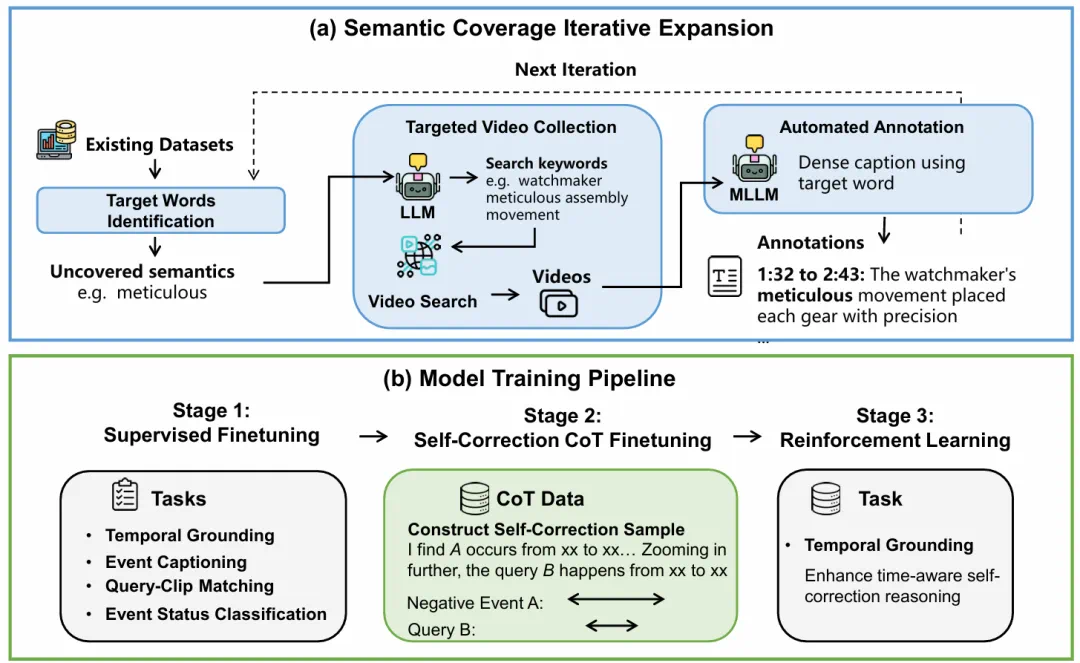
The team proposes the OmniVTG dataset and Self-Correction CoT training.
团队提出大规模 OmniVTG 数据集,以及 Self-Correction CoT 训练范式。
The article reports a smaller rare-common concept gap and better zero-shot performance.
文章称,这缩小了罕见与常见概念差距,并提升多个基准上的零样本性能。
This XPeng story is about deploying foundation models into autonomous driving.
小鹏这条新闻讲的是自动驾驶基座模型怎样真正部署到车上。
The article says CVPR 2026 created a workshop on embodied foundation-model deployment.
文章称,CVPR 2026 首次设立具身智能基座模型部署研讨会。
Tesla, Waymo, NVIDIA, and XPeng appearing together points to deployment as the new focus.
现场代表包括特斯拉、Waymo、英伟达和小鹏,说明自动驾驶已进入基座模型落地讨论。
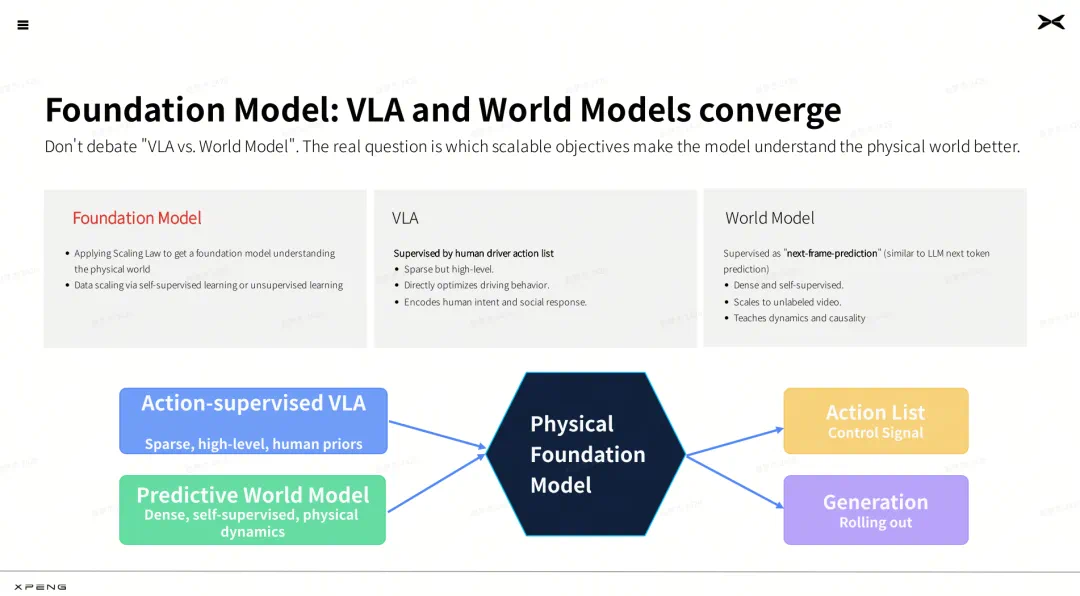
The next step is not choosing VLA or world models, but combining them in road systems.
文章强调下一步不是 VLA 和世界模型二选一,而是把两者放进同一套真实道路系统。
VLA connects vision, language, and action, while world models help predict scenes and test policies.
VLA 负责把视觉、语言和行动连起来,世界模型则帮助预测未来场景和验证策略。
This follows XPeng's path from BEV perception to VLA control to foundation-model deployment.
这也呼应小鹏过去几年的演进:从 BEV 感知,到 VLA 控车,再到基座模型部署。
The hard part remains stability, verification, and long-term safety on complex roads.
真正难点仍是复杂道路里的稳定性、可验证性和长期安全表现。
It is a roadmap signal; production-fleet data must prove it.
所以这条新闻更像是路线信号,最终还要看量产车队数据来证明。
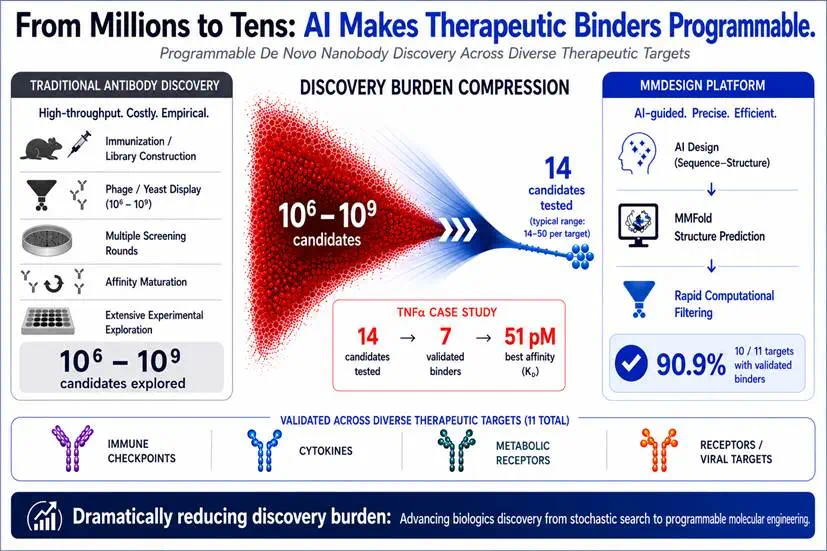
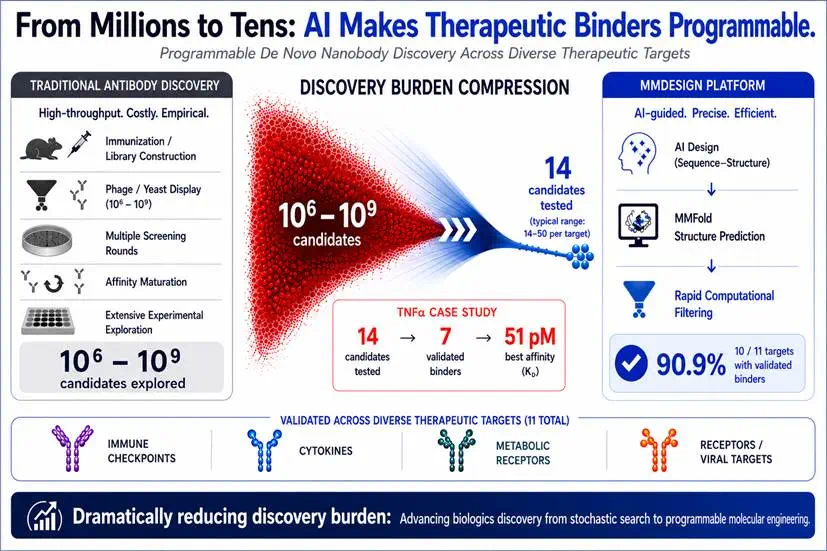
MMDesign asks whether antibody discovery can move from blind screening to programmable design.
MMDesign 这条新闻讲的是,抗体发现能否从盲盒筛选走向可编程设计。
Traditional antibody discovery can screen millions or billions of candidates.
文章称,传统抗体发现要筛数百万到数十亿候选分子,成本和不确定性都很高。
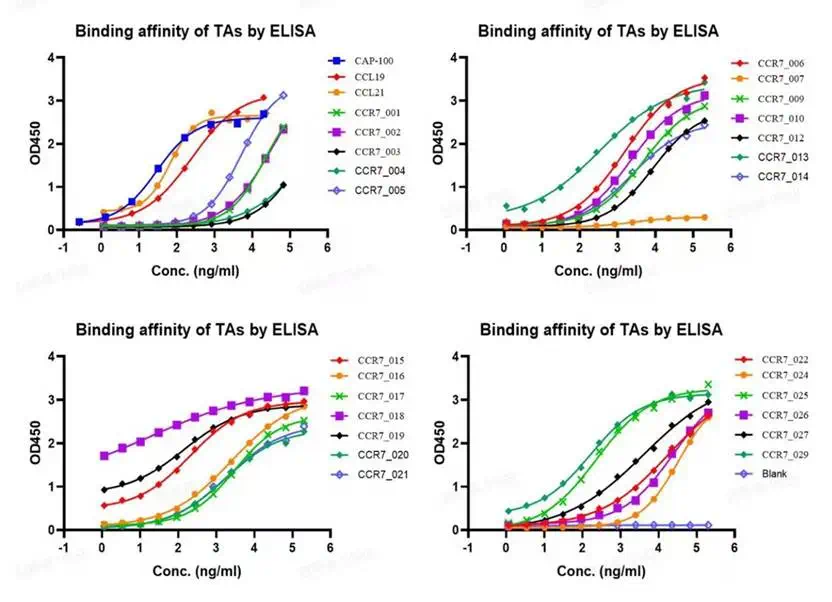
MMDesign generates many candidates, then filters by structure, sequence, and interface evaluation.
MMDesign 采用生成-过滤策略,先生成大量候选,再用结构可靠性、序列自然性和界面评估压缩候选池。
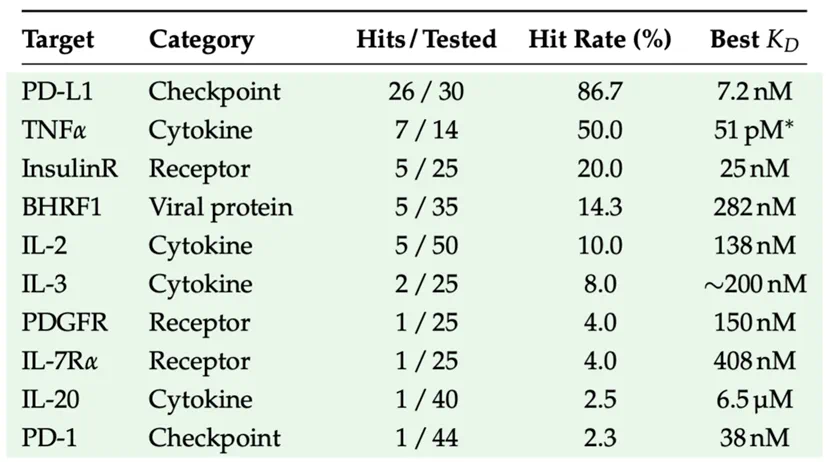
The article says only 14 to 50 molecules per target entered wet-lab validation.
文章称,每个靶点只让 14 到 50 个分子进入湿实验验证。
In 12 high-value targets, 11 had confirmed specific binding, above 90 percent target success.
在 12 个高价值靶点中,11 个确认特异性结合,靶点成功率超过 90%。
That suggests AI protein design is moving toward industrial dry-wet loops.
这说明 AI 蛋白设计开始接近产业化干湿闭环,而不只是计算机上的漂亮结构。
The caveat is that binding success is not drug success.
但结合成功率还不是成药成功,稳定性、免疫原性、递送和生产工艺仍要继续验证。
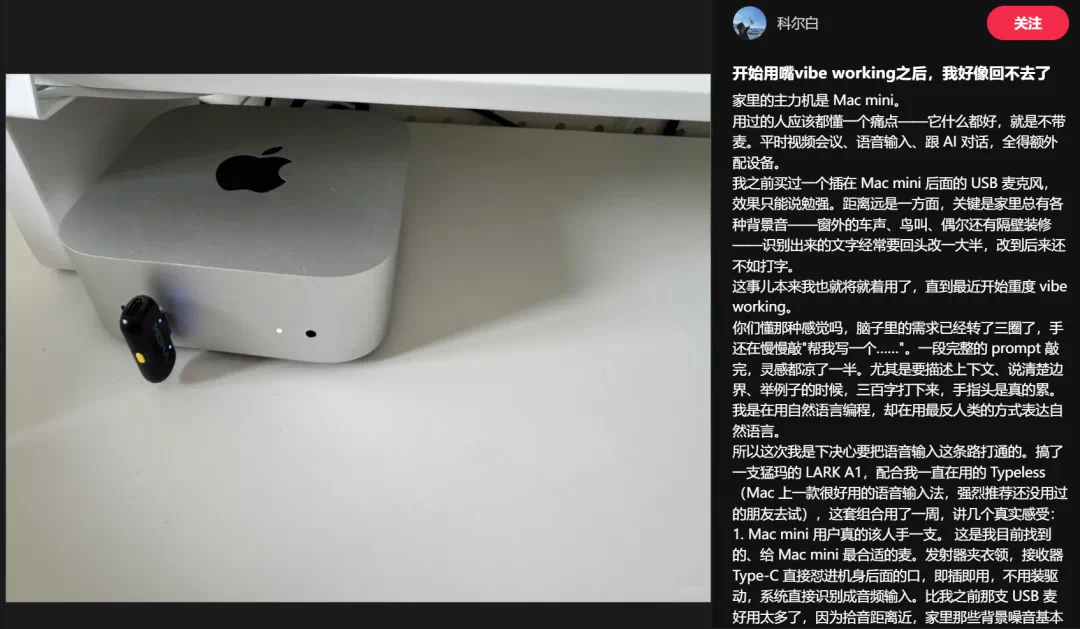
The article says typing may be becoming an older craft in knowledge work.
这篇文章说,键盘可能正在从知识工作的默认入口,变成一种古老技艺。
Vibe Coding and Vibe Working turn natural language into code, documents, and tasks.
原因是 Vibe Coding 和 Vibe Working 都在把自然语言变成代码、文档和任务执行。
Once AI handles generation and execution, input speed depends on how fast people express ideas.
当 AI 接手生成和执行,输入速度就开始受限于人能多快表达想法。
The source video shows phone voice input turning speech into editable text and revisions.
源视频里,手机端语音输入把口语指令转成可编辑文本,再继续修改消息。
That explains why Mac Mini lacking a microphone became a real pain point for Vibe Coding users.
这也解释了为什么 Mac Mini 没有内置麦克风,会突然变成 Vibe Coding 用户的真实痛点。
In offices, voice input is not only dictation but also a way to start agent tasks.
办公场景里,语音输入不仅是听写,还会成为 Agent 的任务启动方式。
Voice has limits: noise, privacy, accent, editing precision, and office etiquette.
不过语音也有边界:噪声、隐私、口音、编辑精度和办公礼仪都会影响使用。
Typing will not disappear, but it may become an editing and control tool.
所以键盘不会消失,但它可能从主要创作入口,变成精修和控制工具。