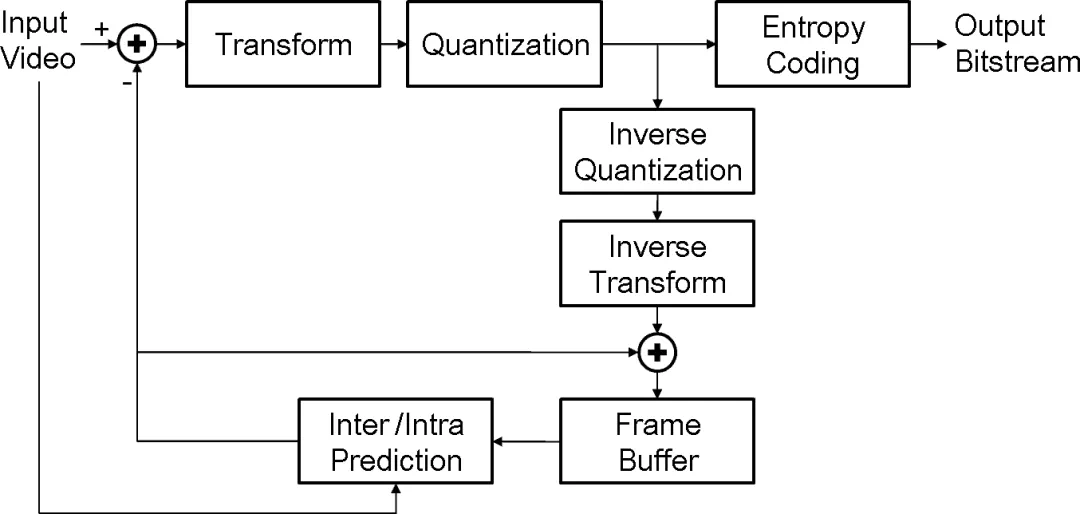
OpenAI is putting ChatGPT and Codex into one work entry point.
OpenAI 这次把 ChatGPT 和 Codex 放到同一个入口里,文章称这是一次面向知识工作的产品合并。
The shift is from conversation alone toward task execution inside ChatGPT.
它的含义不是少开一个应用,而是 ChatGPT 负责对话入口,Codex 负责把任务真正执行出来。
The article says Codex has passed 5 million weekly active users.
文章称 Codex 每周活跃用户已经超过 500 万,桌面版上线以来增长超过 6 倍。
Knowledge workers are becoming a larger part of the Codex user base.
更关键的是,知识工作者正在快速涌入,目前已经约占全部用户的五分之一。
OpenAI also introduced six role plugins for work-specific tasks.
所以 OpenAI 同时推出了六个角色插件,覆盖数据分析、创意制作、销售、产品设计、股权投资和投资银行。
The data workflow reads data, makes charts, and turns results into a report.
数据分析插件的演示里,用户提出业务问题后,系统会读取数据、生成图表,并把结果组织成报告。
The creative plugin links product assets, copy, and pages for marketing work.
创意制作插件则把产品素材、文案和页面组织在一起,面向的是营销和设计团队的日常产出。
Sites turns project outputs into shareable pages instead of only chat logs.
Sites 是另一条线,它让项目结果可以变成可分享的网页,而不只是停留在对话记录里。
Annotations brings structured data, documents, and comments into the execution loop.
Annotations 则把结构化数据、文档和批注拉进同一个执行闭环,让模型可以围绕具体内容继续工作。
Together, these features point to ChatGPT as an enterprise task interface.
这些更新合在一起,指向的是 ChatGPT 从问答产品变成企业任务界面。
For developers Codex remains the execution layer, while plugins package it for other roles.
对开发者来说,Codex 仍然是执行层;对更多岗位来说,它会被包装成更接近业务语言的插件。
OpenAI is bringing the entry point back to ChatGPT because business users already live there.
这也解释了为什么 OpenAI 要把入口放回 ChatGPT:企业用户更熟悉聊天入口,也更容易从那里发起多步骤任务。
The caveat is rollout, permissions, auditability, data isolation, and recovery from failed execution.
但报道里的能力仍要看实际开放节奏,尤其是权限、审计、数据隔离和执行失败时的恢复机制。
Qualcomm is framing the agent era as an infrastructure problem.
高通这次把智能体时代的重点放在基础设施,而不是某一个终端功能。
The article says future agents will run continuously and coordinate services.
文章称,未来的智能体会持续运行、保留上下文,还会在后台规划和调用多个服务。
Devices need to distribute work across phones, PCs, cars, robots, and the edge.
这就要求设备不只是响应人的点击,而是能在手机、PC、汽车、机器人和边缘之间分配任务。
Qualcomm's keyword is compute continuum across tiers of compute.
高通给出的关键词是计算连续体,把不同层级的计算节点连成一套调度网络。
Real-time and privacy-sensitive tasks are better suited to on-device compute.
实时交互和隐私敏感任务更适合留在端侧,因为延迟和数据边界都更可控。
Edge devices handle local tasks while data centers handle heavier inference.
现场化任务可以交给边缘设备,复杂的大规模推理再交给数据中心。
That matters for Qualcomm because chips, connectivity, software, and ecosystem become one story.
这种叙事对高通很重要,因为它把芯片、连接、系统软件和生态能力放在同一条主线上。
For agent apps, the bottleneck may be context movement and low-power execution.
对智能体应用来说,真正的门槛可能不只是模型多强,而是上下文怎样跨设备迁移、任务怎样低功耗执行。
The caveat is whether the strategy becomes visible user experience.
不过这仍是厂商战略,是否能变成用户可感知的体验,还要看开发工具、终端成本和真实应用密度。
This OpenClaw story is about bringing agent runtime support to Windows.
这条 OpenClaw 新闻讲的是 Agent 运行时终于补上了 Windows 这块拼图。
The article says OpenClaw Gateway and Node can now run natively on Windows.
文章称,OpenClaw 的 Gateway 和 Node 现在可以原生跑在 Windows 上。
It also integrates Microsoft's MXC security framework for isolation, identity, and policy.
更重要的是,它集成了微软 MXC 安全框架,让 Agent 有进程隔离、身份标识和策略管控。
Windows is not only running agents, it is adding production safety boundaries.
这说明 Windows 不只是能运行 Agent,而是开始给 Agent 提供生产环境里的安全边界。
The report says Microsoft's always-on Scout agent is built on OpenClaw.
报道还提到,微软 Scout 这类永远在线的 Agent,正是构建在 OpenClaw 框架之上。
MindGo's Mano-CUAskill connects GUI automation into OpenClaw.
明略科技的 Mano-CUAskill 则把 GUI 自动化接进 OpenClaw,让 Agent 可以看屏幕、动鼠标、跨应用执行任务。
Octo is framed as a collaboration network for communication among agents.
而 Octo 被写成 Agent 协作网络,解决的是越来越多 Agent 之间怎样沟通和协作的问题。
The signal is agent competition moving into operating systems, runtimes, and collaboration networks.
这条新闻的信号是,Agent 竞争正在从模型和工具,扩展到操作系统、运行时和协作网络。
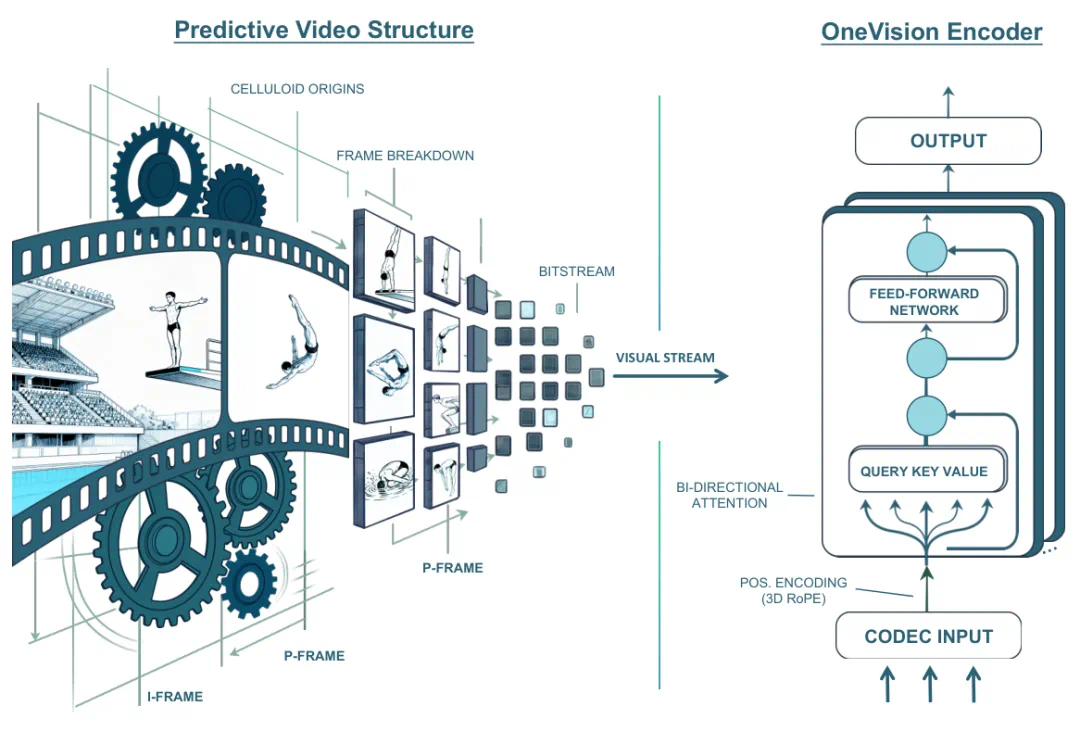
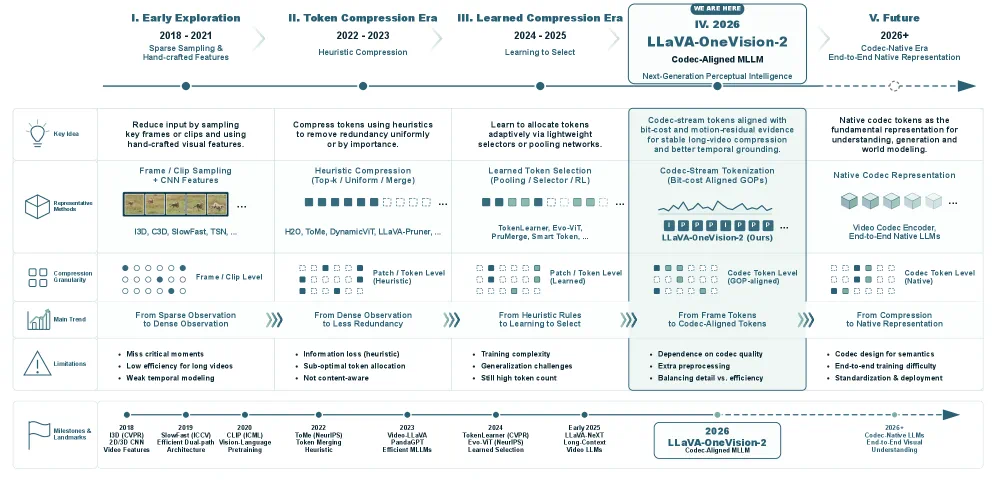
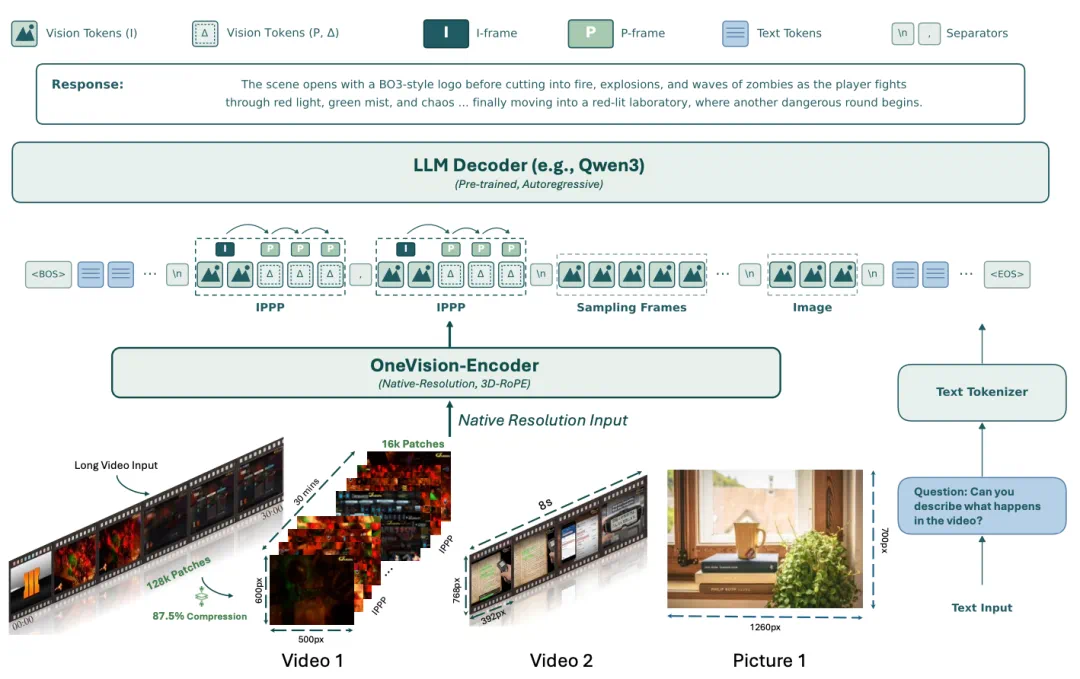
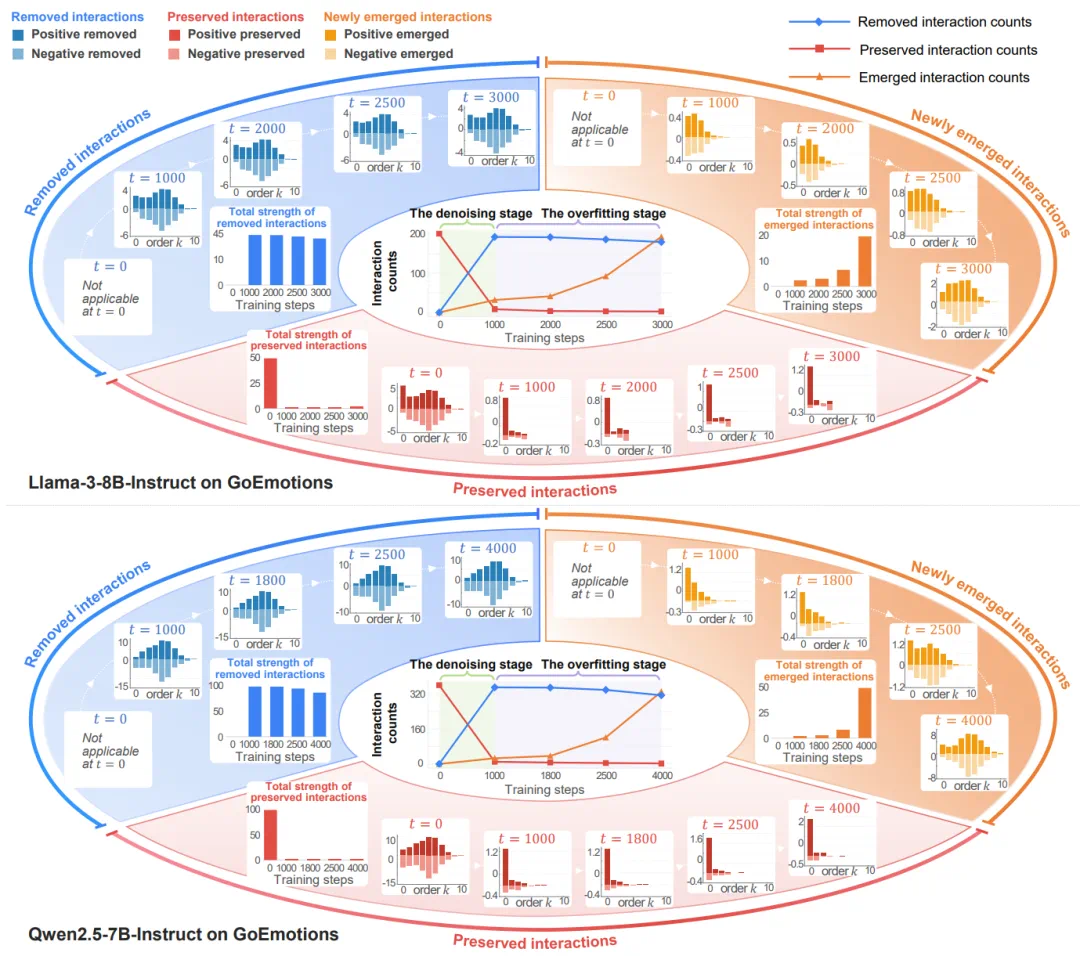
LLaVA-OneVision-2.0 asks whether multimodal models can watch video without sparse frame sampling.
LLaVA-OneVision-2.0 的核心问题是,多模态模型能不能不用抽帧的方式看视频。
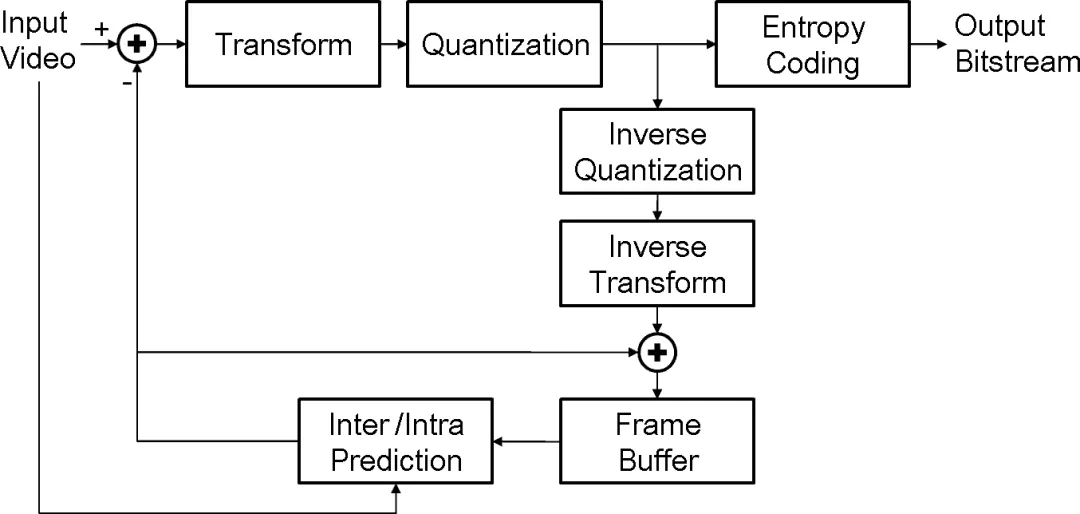
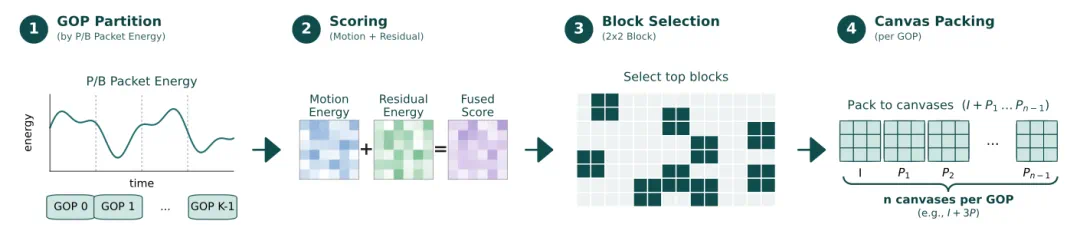
The article's answer is Codec-Stream using references, motion vectors, and residuals as evidence.
文章给出的答案是 Codec-Stream,把视频编码里的参考帧、运动向量和残差当成连续证据流。
The model can focus attention on where and when the video actually changes.
这样模型不必平均观看每一帧,而是把注意力放到真正发生变化的位置和时刻。
The report says OV2-8B is built on Qwen3-8B and a custom OneVision-Encoder.
报道称,OV2-8B 基于 Qwen3-8B 语言模型和自研 OneVision-Encoder。
The training pipeline, data, and weights are open sourced.
它的训练流程、数据和权重都开源,文章同时给出技术报告、GitHub、模型和数据地址。
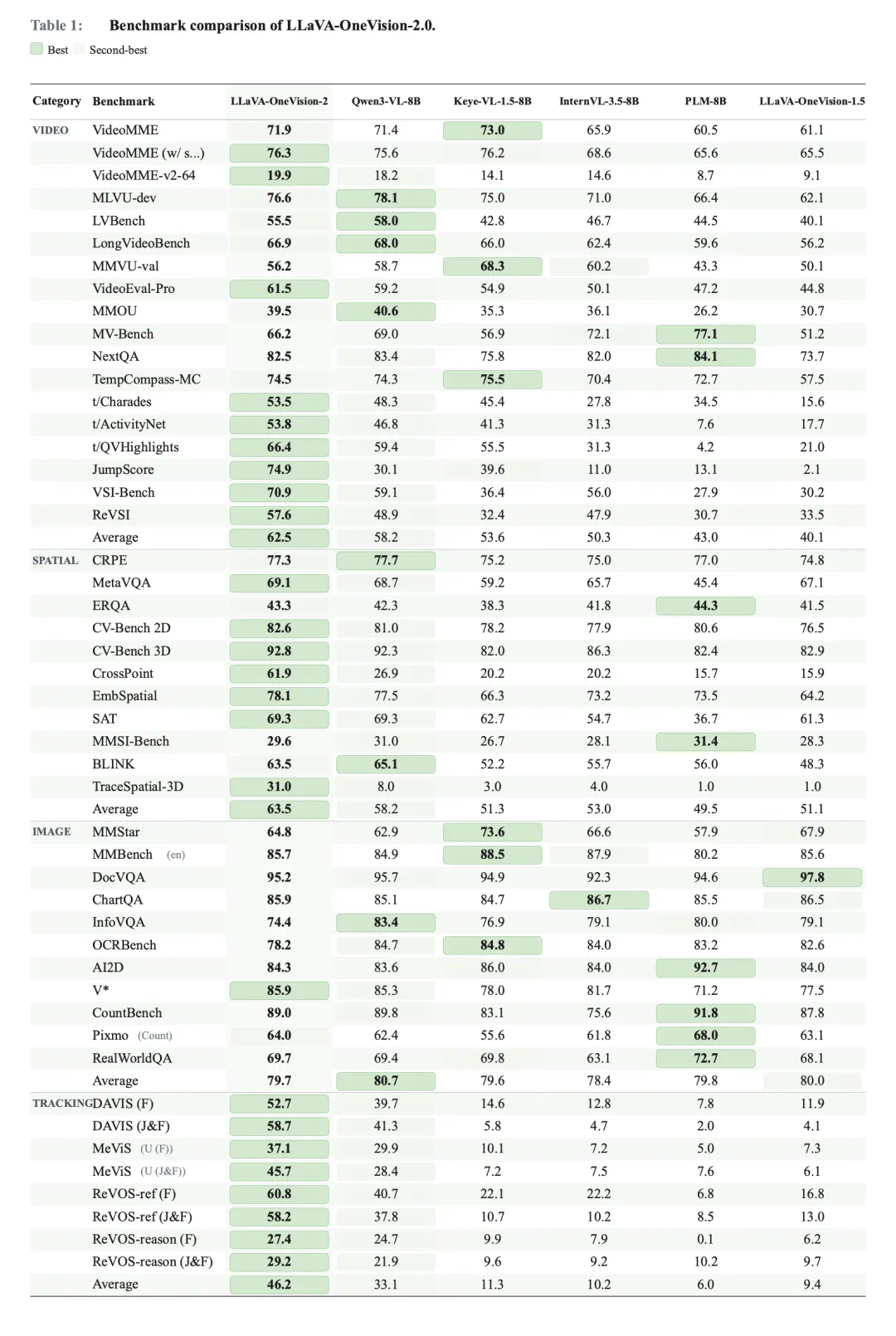
The evaluation spans video tasks, spatial reasoning tasks, and tracking tasks.
在评测上,文章称模型覆盖 18 项视频任务、11 项空间推理任务和 4 项跟踪任务。
JumpScore tests whether the model remembers key repetitions in repeated actions.
自研 JumpScore 关注重复动作里的关键次数,比如模型是否记住第几次事件发生。
That differs from frame sampling, which can miss short-lived events.
这和传统抽帧路线不同,因为抽帧很容易错过稍纵即逝的事件。
Codec is treated as an engineering prior: inherited state plus meaningful differences.
文章还把 Codec 解释成一种工程先验:可继承的部分写成状态,无法忽略的变化写成差分。
In modeling terms, the video becomes context plus incremental evidence.
放到模型里,这就把视频拆成上下文和增量证据,而残差往往正是世界变化的位置。
If the route works, long-video understanding can use less redundant observation and more event modeling.
如果这条路线成立,长视频理解可以少一些冗余观察,多一些事件级建模。
The caveat is robustness across codecs, frame rates, and real video noise.
不过它仍需要在不同编码质量、不同帧率和真实视频噪声下验证稳定性。
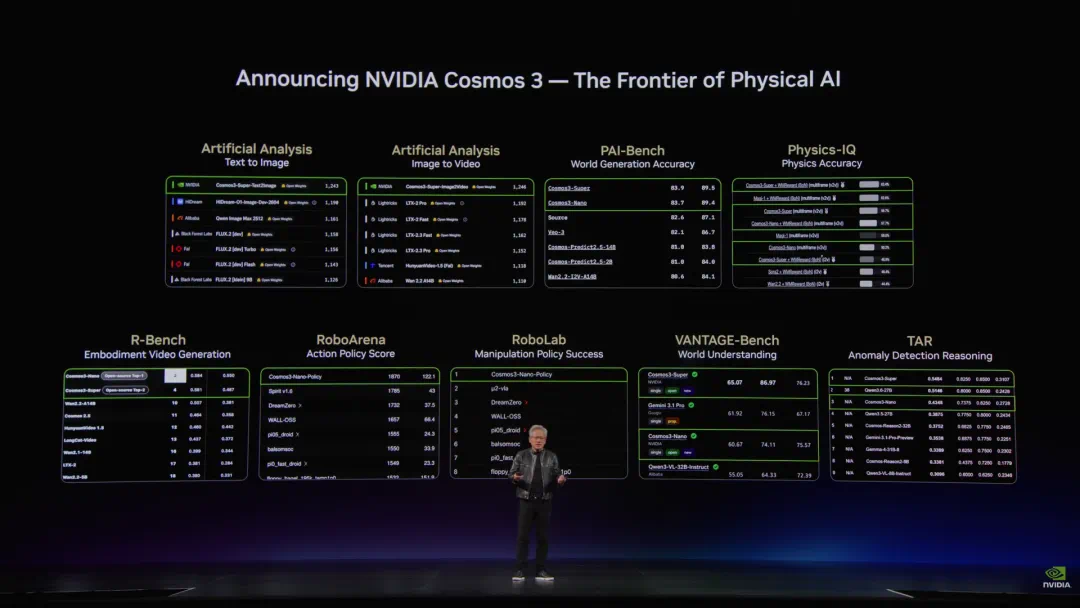
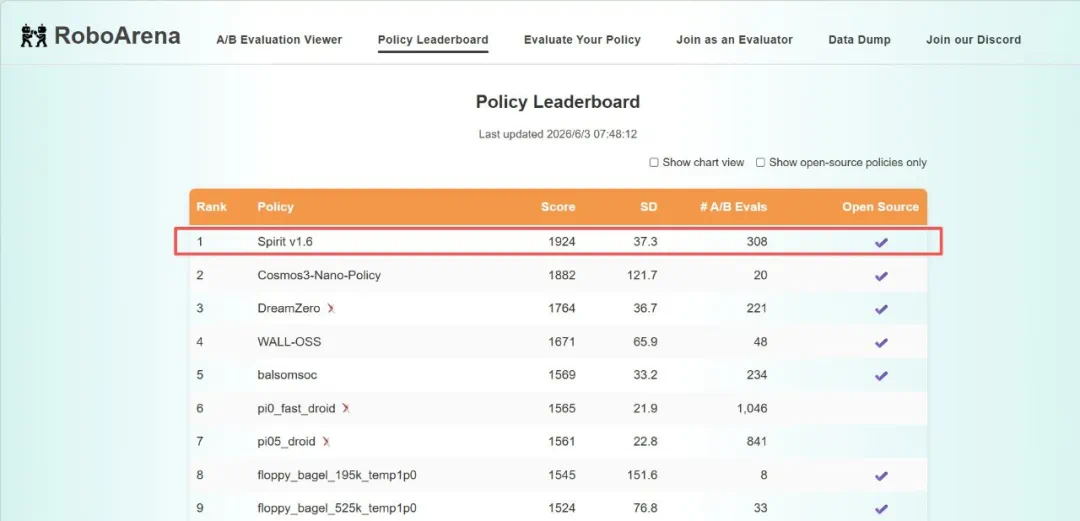
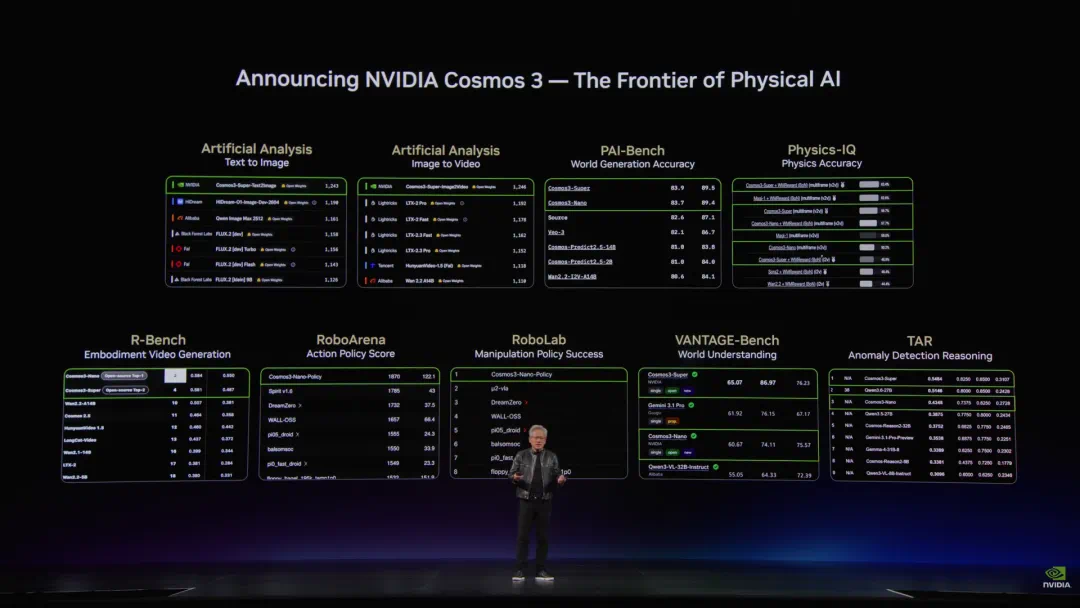
One day after Cosmos 3, Spirit v1.6 reportedly overtook it on RoboArena.
NVIDIA 刚发布 Cosmos 3 一天后,文章称千寻智能 Spirit v1.6 就在 RoboArena 上反超。
The important part is RoboArena as real robot blind comparison, not a static benchmark.
这件事真正有意思的地方,是 RoboArena 不是普通静态跑分,而是真实机器人双盲对决。
The article compares it to an embodied-robot version of LMArena.
文章把它类比成具身机器人版本的 LMArena,只是这里比的是现实任务完成能力。
The first video shows a notebook-opening task requiring perception and coordinated control.
第一组视频是打开笔记本,机器人要识别位置、判断接触点,再控制手和机械臂配合。
A small perception or control error can fail the notebook task.
这类任务难在任何一个环节出错,笔记本都可能打不开,模型也很难只靠仿真跑分掩盖问题。
The second video compares object manipulation against pi 0.5.
第二组视频展示物体操作,对比对象变成 pi 0.5,任务更像真实桌面上的精细控制。
The article attributes Spirit v1.6's edge to multitask execution, adaptation, and generalization.
文章认为,Spirit v1.6 的优势来自多任务执行、真实环境适应和泛化能力。
RoboArena uses distributed collaboration, blind comparisons, Elo ranking, and an open evaluation network.
RoboArena 的机制包括分布式协作、双盲对决、Elo 动态排名和开放评测网络。
That pushes embodied models toward real task pressure instead of fixed-dataset scores.
这让具身模型更接近真实任务压力,而不是只在固定数据集上展示漂亮数字。
If the leaderboard keeps updating, robot foundation models face continuous tests.
如果这样的榜单持续更新,机器人基础模型的竞争会更像体育赛事,模型要不断接受新任务检验。
The caveat is that ranking first does not mean winning every environment.
但排名领先不等于所有场景领先,真实机器人还要面对硬件差异、环境扰动和长期可靠性。
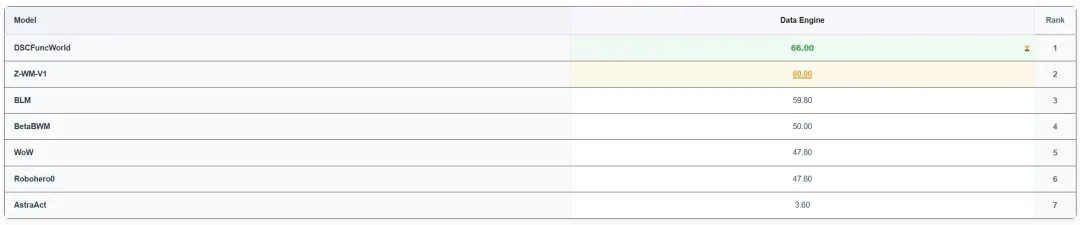
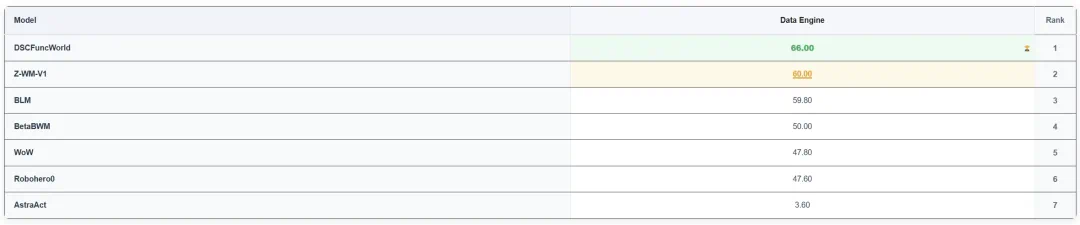
This story is about a new leader on WorldArena Track 2.
跨维智能这条新闻讲的是 WorldArena Track 2 榜首易主。
The article says DSCFuncWorld topped the Data Engine track.
文章称,DSCFuncWorld 在最终榜单中登顶数据引擎赛道,并拉开了和第二名的差距。
The track focuses less on pretty visuals and more on usable robot training data.
这个赛道不主要看画面漂不漂亮,而是看模型能否生成可用于机器人任务的数据和策略线索。
The source video shows robot task snippets tied to world-model outputs.
源视频里可以看到机器人任务片段,重点是把世界模型输出接到真实操作流程。
Another clip shows online data streaming across data synthesis, training, and evaluation.
另一段视频展示在线数据流式流程,说明数据合成、策略训练和任务评估被放在同一条链路里。
The article says WorldArena includes 16 metrics and three real application tasks.
文章强调 WorldArena 包含 16 项细分指标和 3 大真实应用任务。
The signal is world models moving from demos toward embodied data and training loops.
所以这里的信号是,世界模型正在从生成演示走向具身数据和训练闭环。
The caveat is cost, sim-to-real transfer, and independent task validation.
但榜单第一还不是商业落地,仍要看数据成本、虚实迁移和更多第三方任务验证。
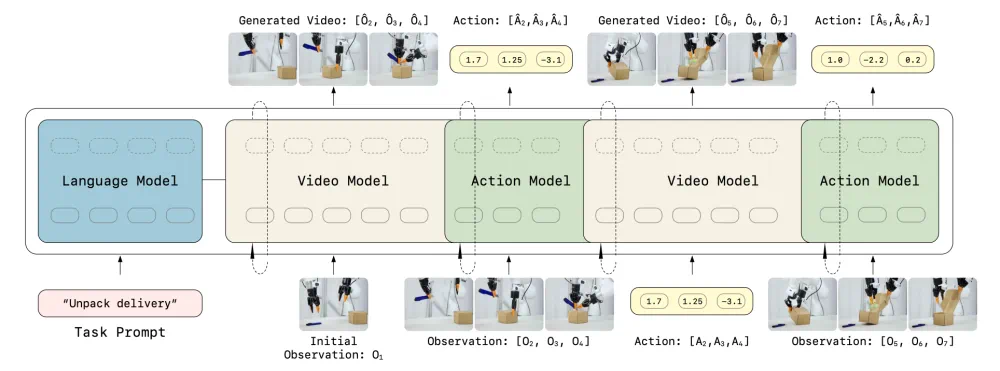
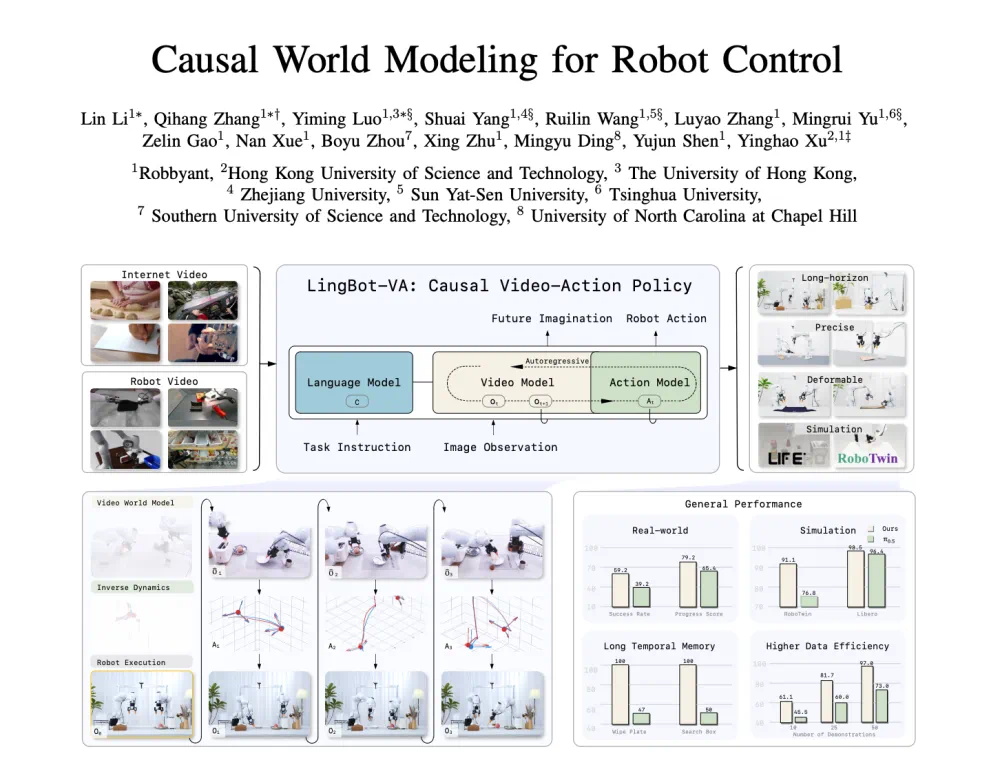
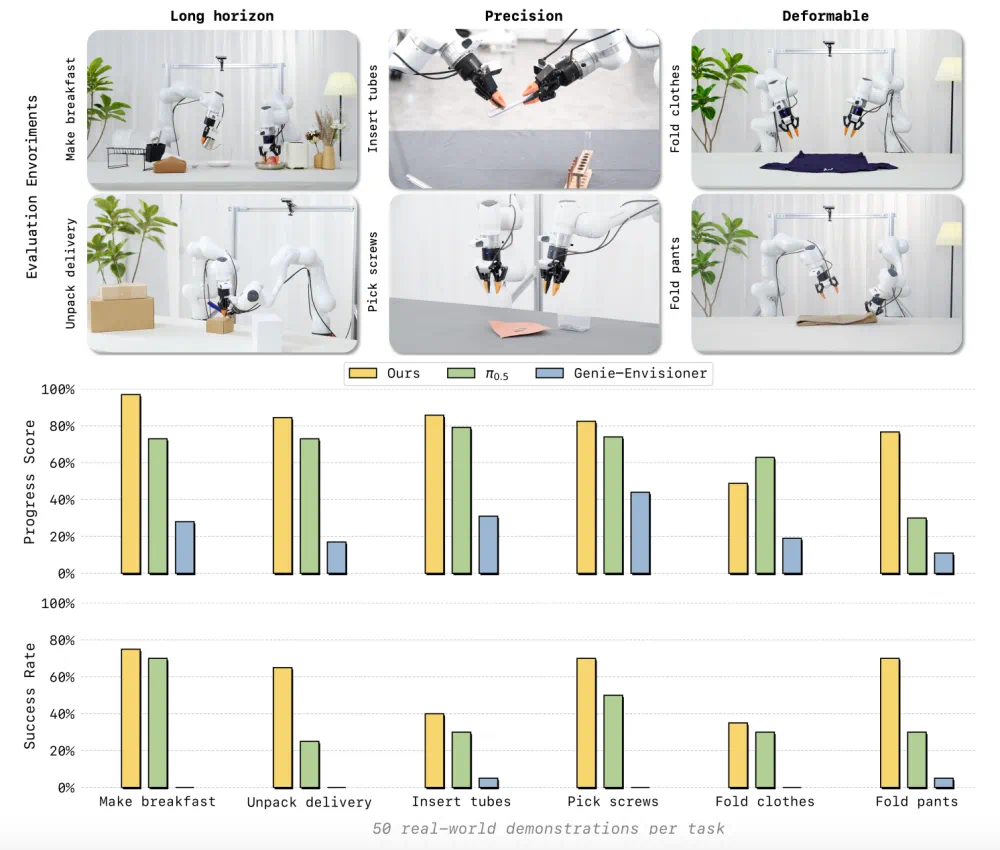
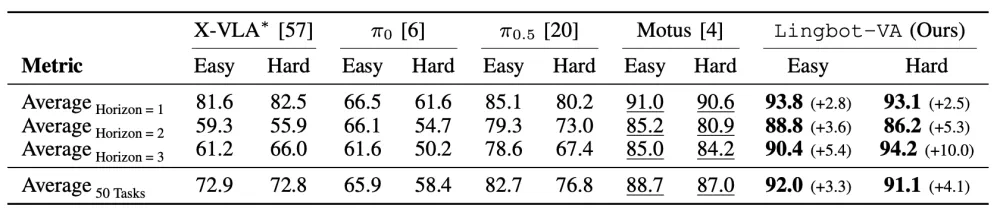
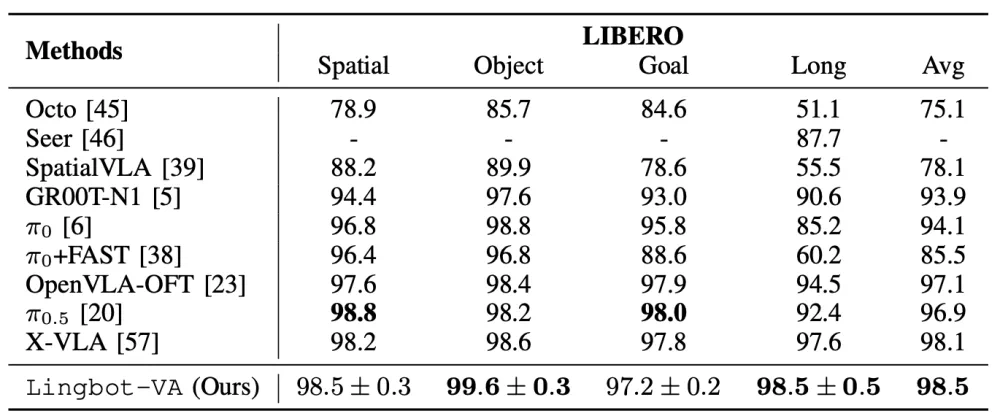
LingBot-VA tries to predict future video and infer robot actions together.
LingBot-VA 这条研究新闻,试图让机器人一边预测未来画面,一边推断该怎么动作。
The difficulty is not only seeing now, but understanding how actions change the world.
文章说,通用操作的难点不是只看懂当前画面,而是理解动作会怎样改变物理世界。
LingBot-VA interleaves video tokens and action tokens in one causal sequence.
LingBot-VA 把视频 token 和动作 token 交错成同一个因果序列。
It predicts how the visual world evolves, then infers actions from those predictions.
它不是直接学动作分布,而是先预测视觉世界如何演变,再从这些预测里推断动作。
The architecture uses video experts for scene transitions and lighter action experts for control.
架构上,文章提到一种混合 Transformer:高容量视频专家看场景变化,轻量动作专家负责解码动作。
KV cache helps the model keep long observation-action histories.
为了处理长程任务,模型还利用 KV 缓存保留过去观察和动作历史。
The report says it learns physical priors from video, then transfers them with few robot demos.
文章称,它通过大规模视频学物理先验,再用少量机器人演示把先验转成动作能力。
The real test is transfer across robot bodies, camera views, and complex tasks.
真正要验证的是,这种视频先验能否跨机器人本体、摄像头视角和复杂任务稳定迁移。
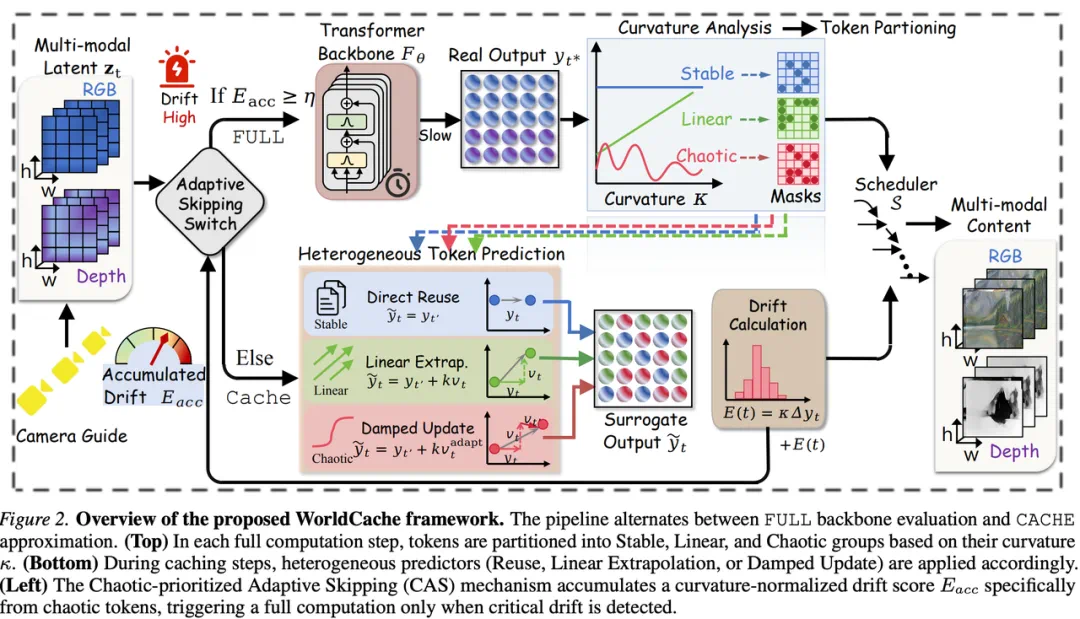
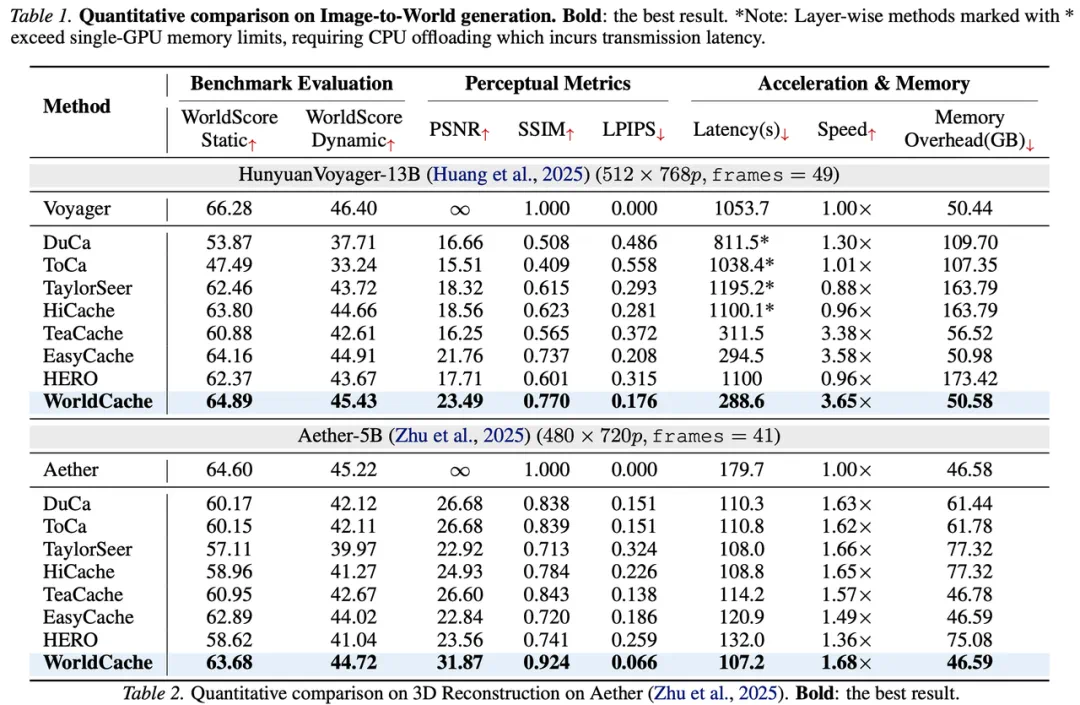
WorldCache targets expensive inference in diffusion world models.
WorldCache 要解决的是扩散世界模型推理太贵的问题。
It does not retrain the model, but decides which tokens can be cached and when to recompute.
文章称,它不重新训练模型,而是判断哪些 Token 可以缓存,哪些时刻必须重算。
It groups tokens into stable, linear, and chaotic categories for different cache updates.
方法用曲率把 Token 分成 Stable、Linear 和 Chaotic 三类,分别复用、外推或阻尼更新。
Recomputation is triggered by the hardest chaotic tokens, not a global average.
重算触发也不看全局平均,而是优先盯住最容易失稳的 Chaotic Token。
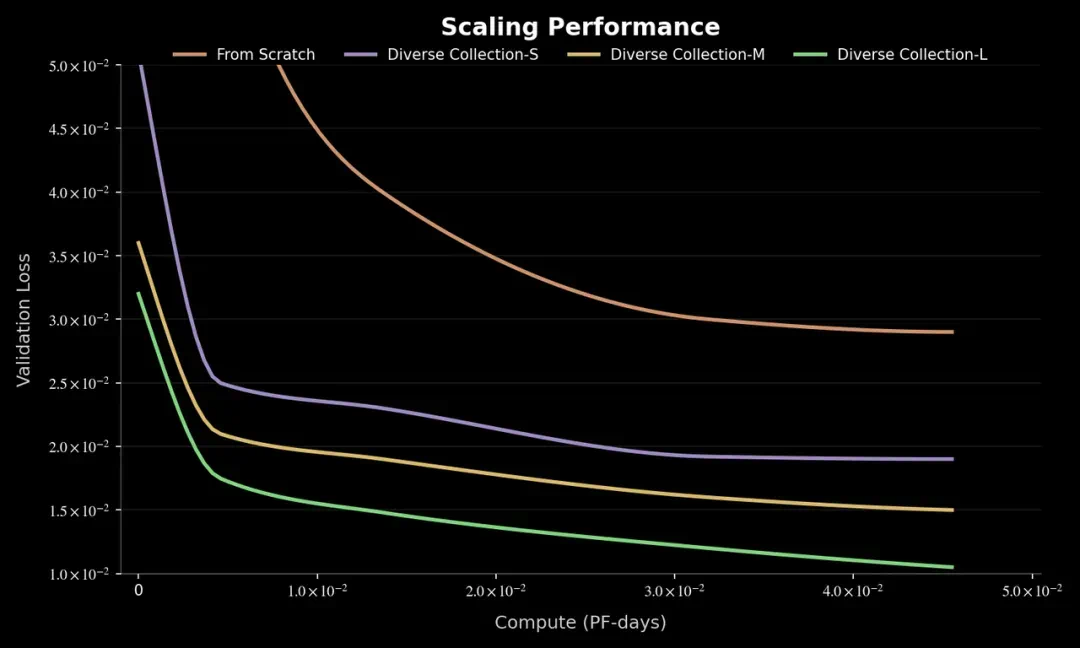
The reported result is 3.7x near-lossless acceleration with almost no extra memory.
文章报告的结果是,视频世界模型近似无损提速 3.7 倍,且几乎不增加显存。
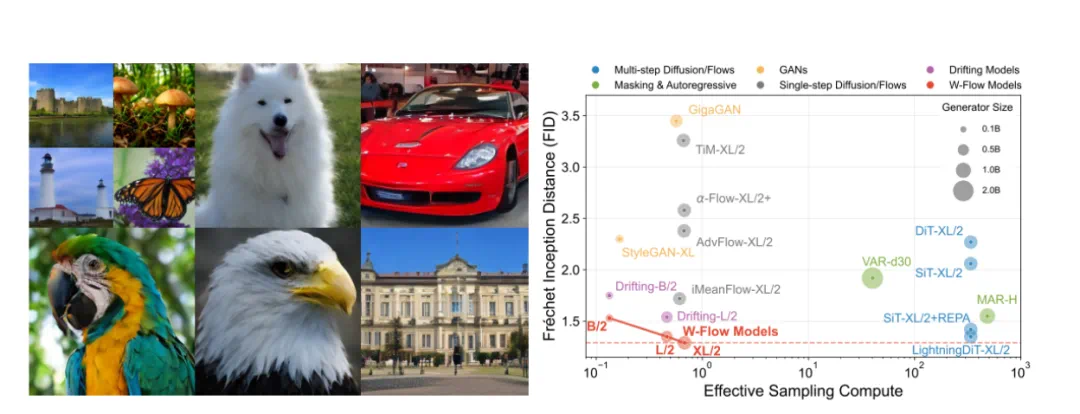
W-Flow aims for one-step generation with principled distribution evolution.
W-Flow 这篇论文想做的是,一步出图,但训练逻辑仍然像有原则的分布演化。
The article says it trains a static generator from scratch rather than distilling diffusion.
文章称,它不是把扩散模型蒸馏成一步,而是从头训练静态生成器。
The core tools are Sinkhorn divergence and Wasserstein gradient flow.
核心工具是 Sinkhorn 散度和 Wasserstein 梯度流,让生成分布沿最优传输的下山方向移动。
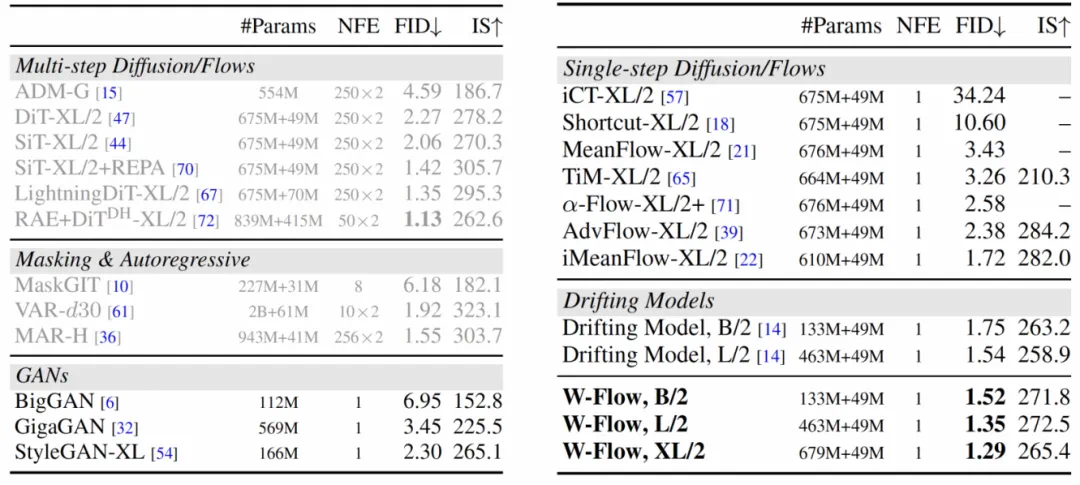
The headline number is 1.29 FID on ImageNet 256x256.
报道最醒目的数字是,W-Flow-XL/2 在 ImageNet 256x256 上达到 1.29 FID。
The caveat is mode coverage, training stability, and independent replication.
但一步生成能否兼顾小众模式覆盖和训练稳定性,还需要更多数据集和独立复现。
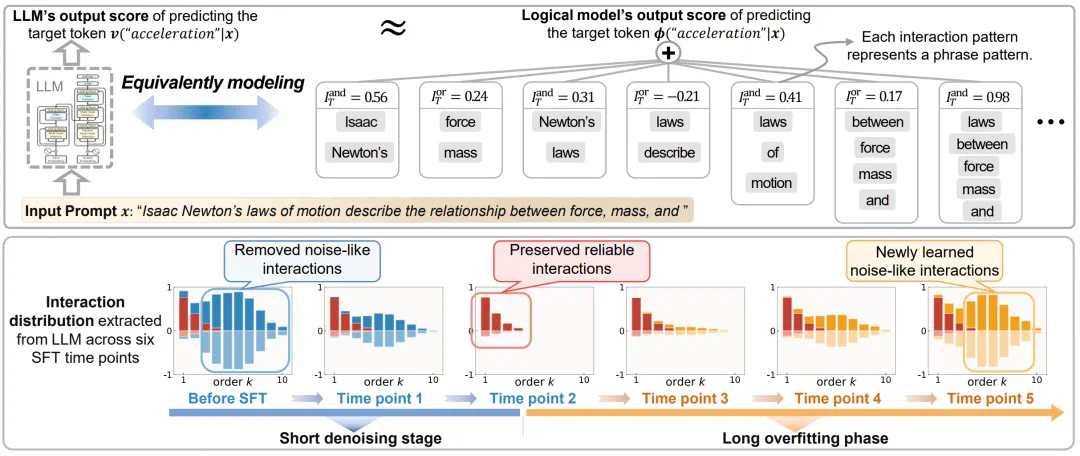
This SFT paper addresses whether supervised fine-tuning helps or hurts generalization.
这篇 SFT 文章要解决一个长期争议:监督微调到底是在增强模型,还是在伤害泛化。
The authors narrow the question to SFT on highly homogeneous data.
作者把问题限定得很清楚:讨论的是高度同源、同质化数据上的 SFT。
Under those conditions, SFT may help briefly and then quickly overfit.
在这种条件下,SFT 可能短时间有效,但继续训练很快会滑向过拟合。
The paper asks which models fit SFT, how long to train, and how many samples to use.
文章提出要从交互机理看三个问题:哪些模型适用,训练窗口多长,最多能用多少样本。
Post-training should not rely only on fixed epochs or a fixed loss threshold.
这意味着后训练不应该只靠固定 epoch 或固定 loss 阈值来决定停止。
The key claim is that each LLM needs its own verifiable SFT window.
报道的关键判断是,不同 LLM 的最适宜窗口不同,需要一个可验证指标逐个模型判断。
More diverse data can dilute one data type's pressure and lengthen the window.
如果数据更多样,单一数据类型上的训练速度会被稀释,窗口也可能相应拉长。
On homogeneous data, more samples and compute may hurt base-model ability.
但在同质化数据上,继续堆样本和算力不一定带来收益,反而可能削弱基座能力。
For engineering teams, SFT should have planned stopping conditions.
这对工程团队很直接:SFT 不是默认越久越好,而是应该有提前设定的退出条件。
The article separates base-model SFT from general supervised continued training.
文章还提醒,基座模型上 SFT 和一般继续监督训练不能混为一谈。
Its value is turning a practical dispute into a measurable model-specific question.
所以它的价值,是把实践争议转成可以监控、可以验证的模型特定问题。
The caveat is that diverse instruction data and RLHF need separate validation.
但这些结论主要针对同质化数据,面对高多样性指令数据和 RLHF 流程还需要单独验证。
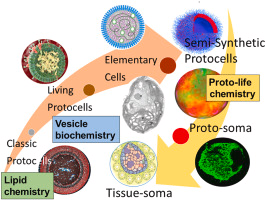
SynCell Asia is publishing a ten-year roadmap, not claiming a finished artificial cell.
SynCell Asia 这条新闻不是说人工细胞已经做成,而是公布了一条十年路线图。
The article says more than 100 Asian research groups are involved.
文章称,中科院牵头,亚洲 100 多个课题组参与,目标是从头构建合成细胞。
The roadmap breaks the problem into energy, ribosomes, membrane coupling, and cell-cycle timing.
路线图把难题拆成代谢能量、核糖体组装、膜和体积耦合,以及细胞周期同步。
The missing piece is coordination across modules, not just individual molecules.
这说明从一堆分子到一个可持续生长和分裂的系统,中间缺的是多模块协同。
It is an engineering plan whose real test is synchronized energy, expression, membrane growth, and division.
因此它更像一份工程组织方案,真正突破还要看后续能否把能量、表达、膜生长和分裂同步起来。