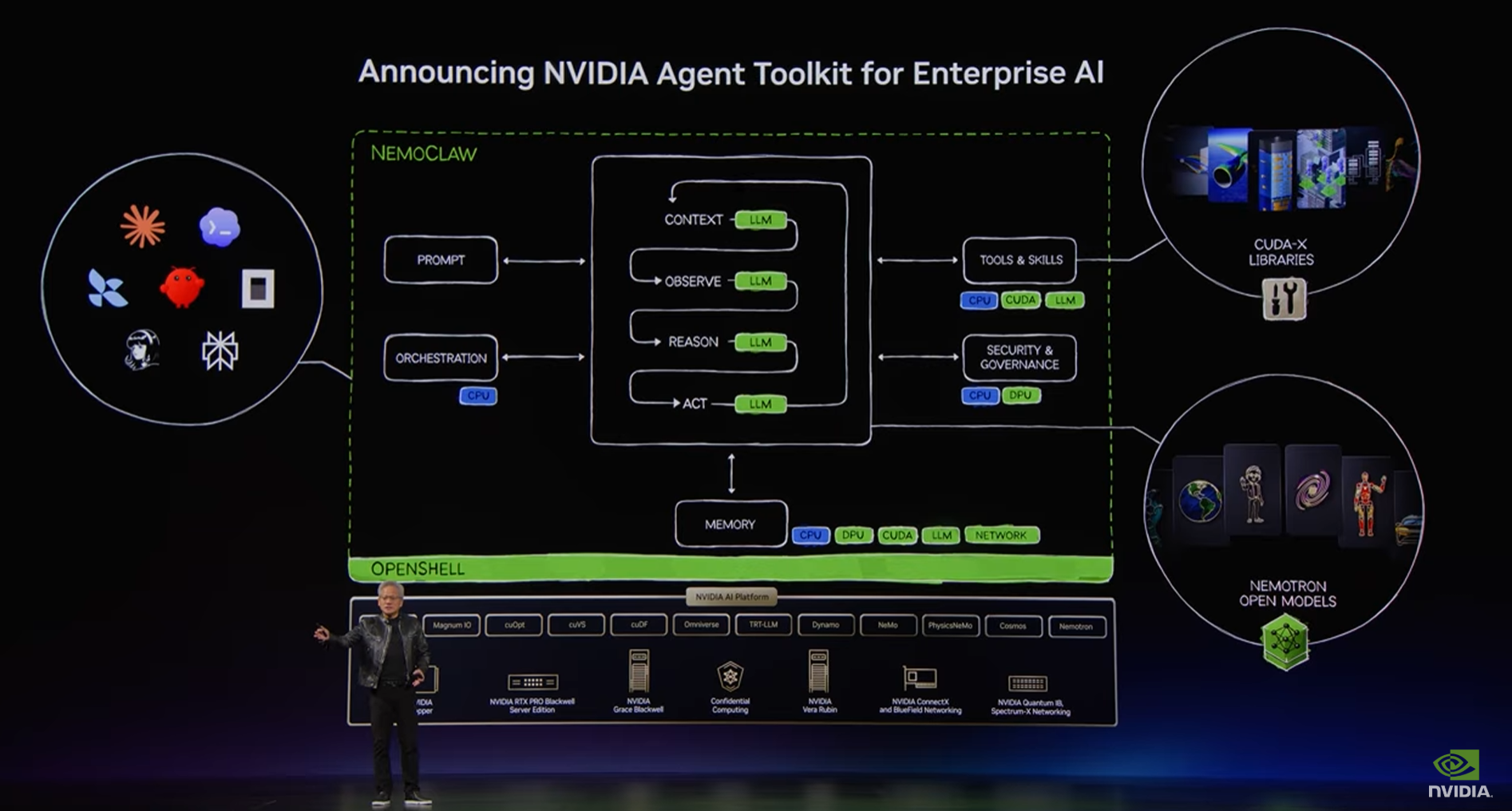
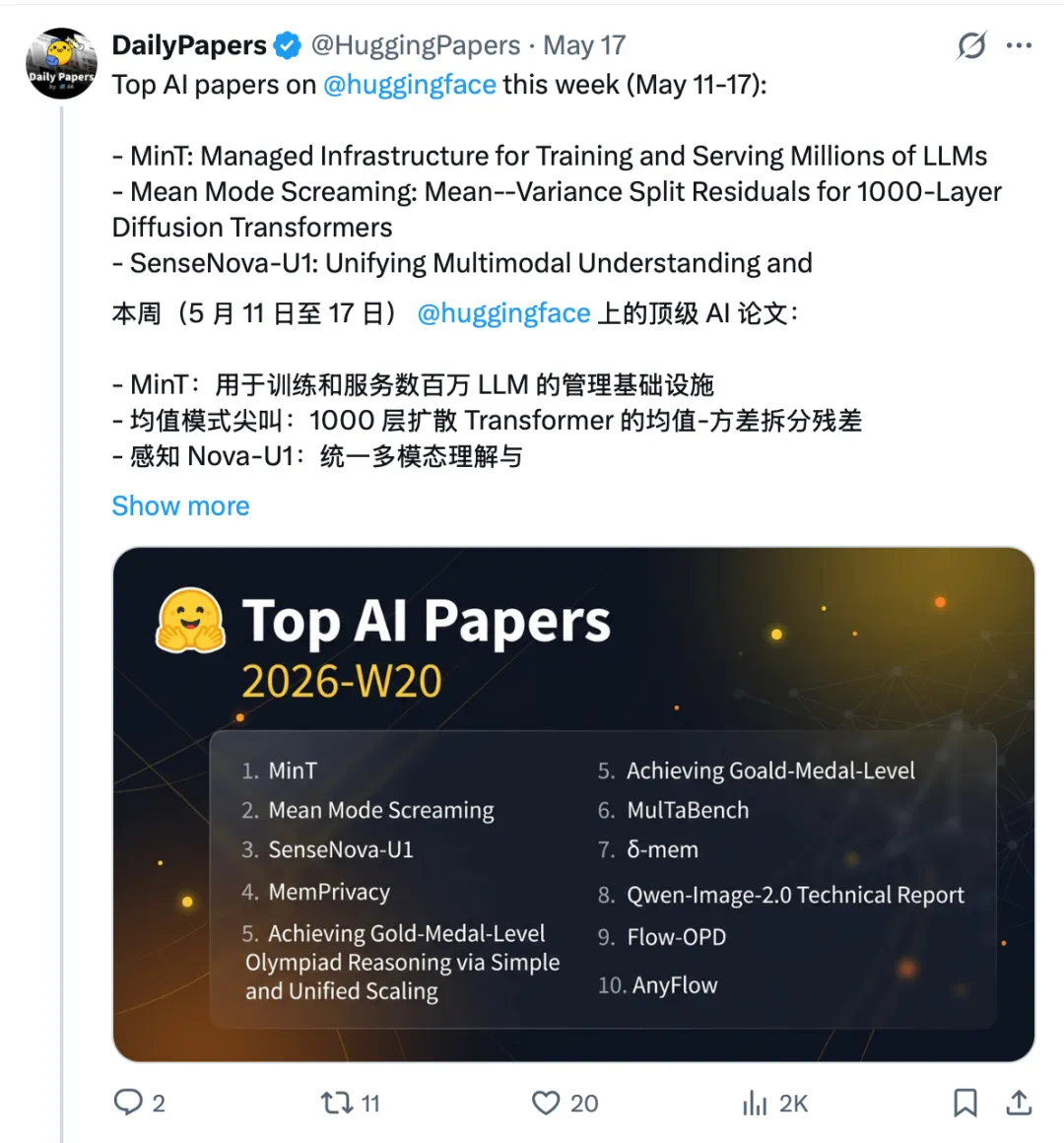
NVIDIA frames physical AI as an agent infrastructure stack, not only a robot model.
英伟达这次把物理 AI 讲成了一整套智能体基础设施,而不是某一个机器人模型。
The report links Cosmos, Omniverse, Isaac, Metropolis, and Jetson across perception, simulation, reasoning, and edge deployment.
报道说,Cosmos、Omniverse、Isaac、Metropolis 和 Jetson 被串到同一条链路里,覆盖感知、仿真、推理和边缘部署。
Cosmos 3 is described as an open world foundation model spanning visual reasoning and multiple generation modes.
Cosmos 3 被描述为全开放的世界基础模型,既做视觉推理,也支持文本、图像、视频、环境音和动作生成。
The model story moves from recognizing images toward deciding actions in real environments.
这让物理 AI 的模型不只是看图识别,还要理解真实环境中下一步该如何行动。
Agent Toolkit packages tools such as NemoClaw, Nemotron, OpenShell, and CUDA-X into callable tasks.
Agent Toolkit 则把 NemoClaw、Nemotron、OpenShell 和 CUDA-X 这类工具包装成可调用任务。
For autonomous driving, Alpamayo 2 Super is framed as a 32B open reasoning VLA.
自动驾驶侧,Alpamayo 2 Super 被写成一个 32B 开放推理 VLA,目标是把视觉、语言和行动结合起来。
On robotics, Isaac GR00T and Sharpa Wave point to linking simulation with real machine debugging.
机器人侧,Isaac GR00T 和 Sharpa Wave 这类参考流程,指向的是更快地把仿真和真机调试接起来。
The real signal is NVIDIA extending agent platform competition into physical-world tasks.
所以这条新闻真正的信号,是英伟达想把物理世界任务也纳入 agent 平台竞争。
The caveat is whether open tools can actually reduce deployment cost and safety risk in real projects.
但开放工具能否降低部署门槛,还要看真实项目里的数据、硬件、调试成本和安全边界。
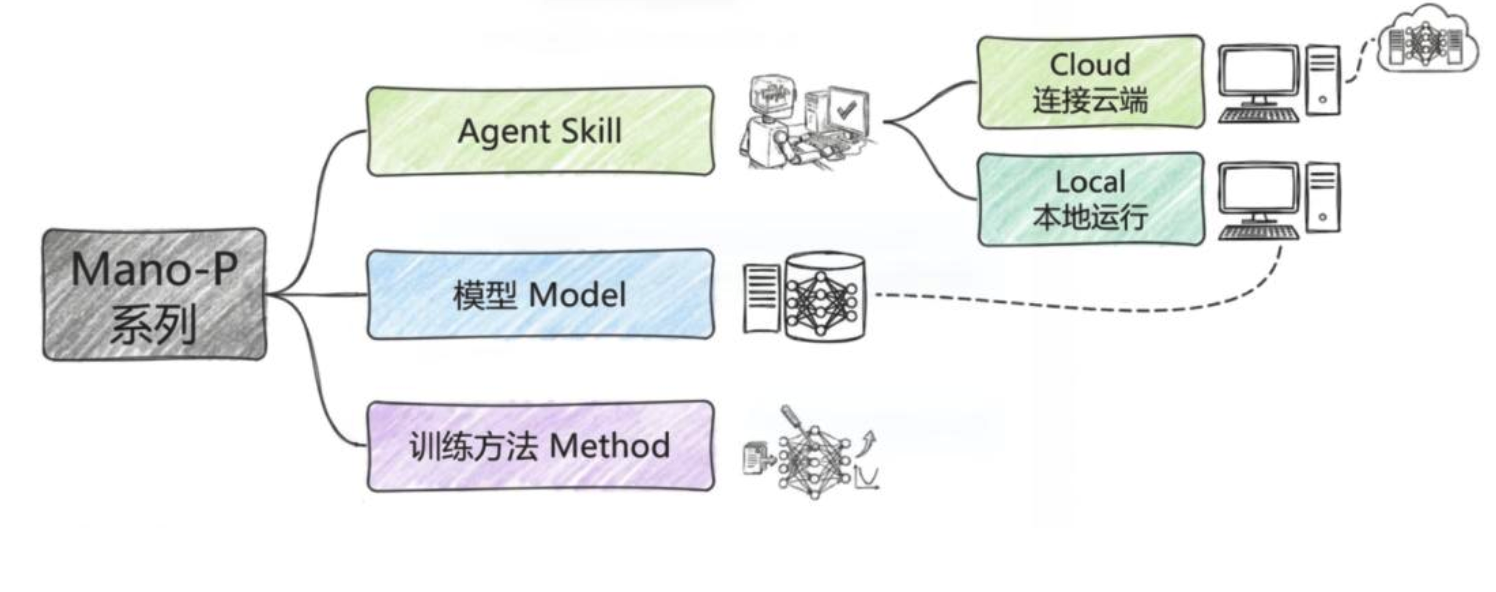
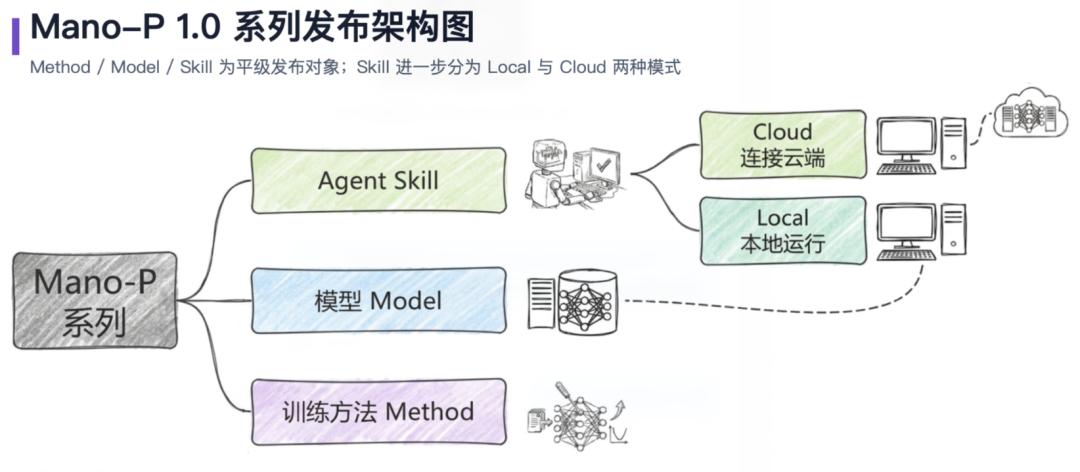
Minglue open-sourced two pieces: the Cider edge inference framework and the Mano-P edge GUI agent.
明略科技这次是双线开源:一个是端侧推理加速框架 Cider,一个是端侧 GUI 智能体 Mano-P。
Mano-P is a 4B GUI-VLA model that sees the screen, understands the interface, and acts locally.
Mano-P 是 4B GUI-VLA 模型,重点是直接看屏幕、理解界面,再在本地执行操作。
This differs from cloud API agents by moving privacy, latency, and cost back to the user's device.
这种路线和只调用云端 API 不同,它把隐私、延迟和成本问题一起拉回到用户设备上。
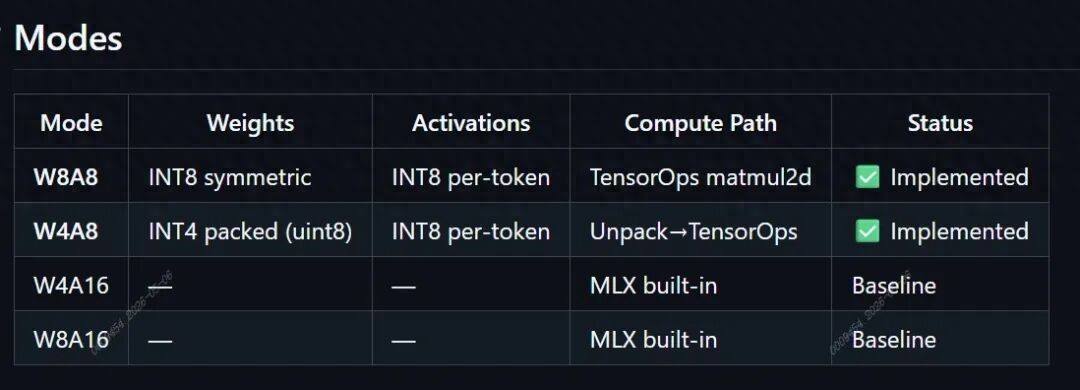
Cider handles the other side: running multimodal models faster and with less memory on Apple Silicon and MLX.
Cider 解决的是另一侧问题:Apple Silicon 上,多模态模型怎样在 MLX 里更快、更省内存地跑起来。
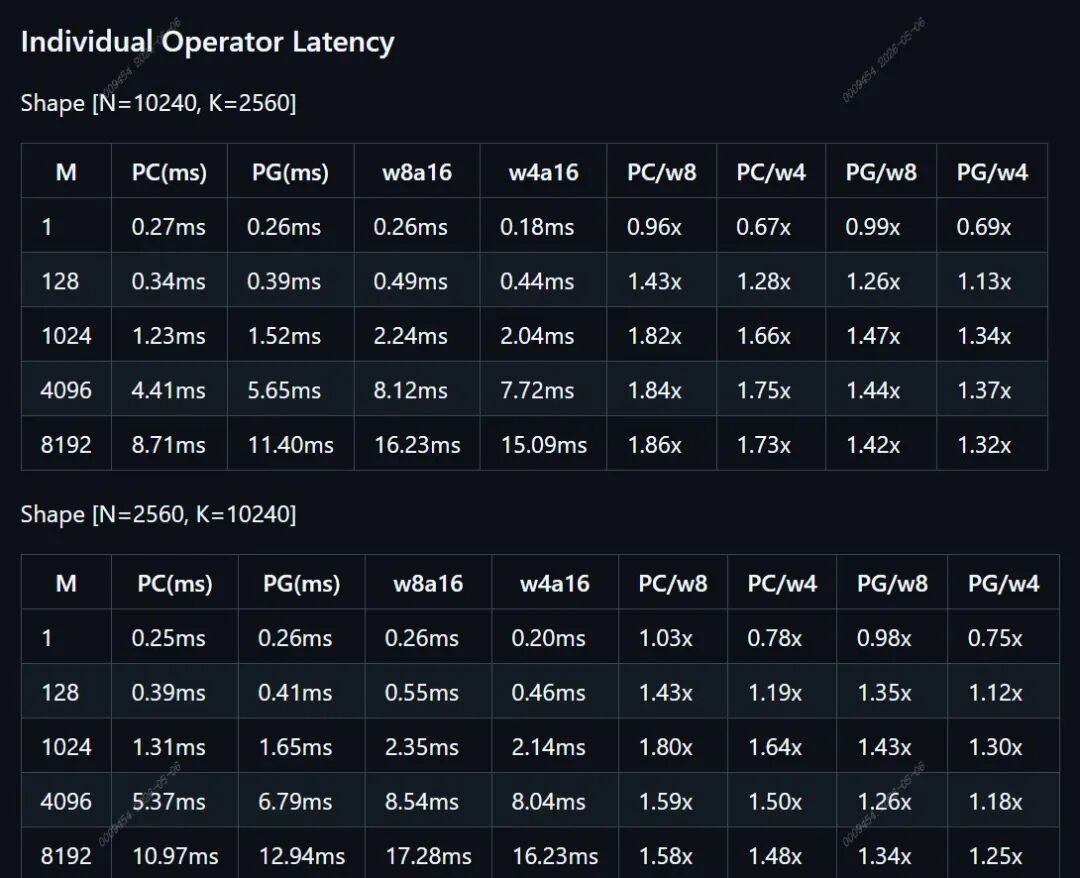
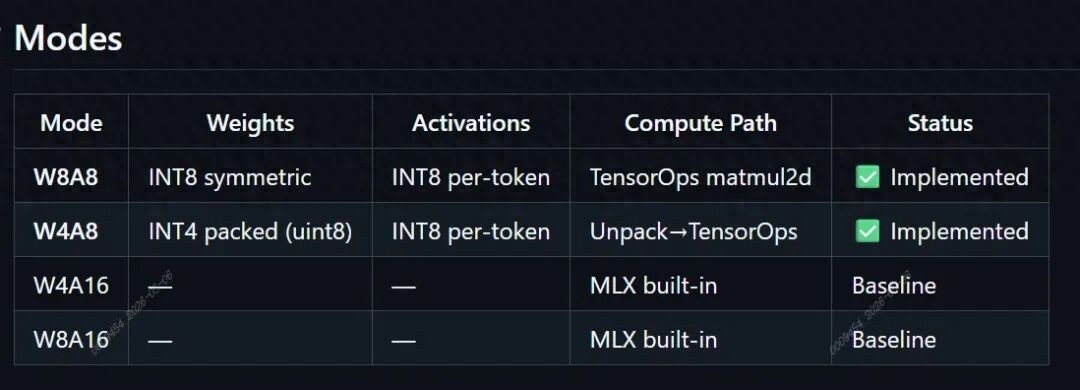
The reported path includes W8A8, W4A8, online activation quantization, and INT8 TensorOps.
报道给出的路径包括 W8A8、W4A8、在线激活量化,以及 INT8 TensorOps。
The report claims W8A8 operators are 1.4 to 1.9 times faster than native MLX, while W4A8 halves weight memory.
性能上,W8A8 算子相对原生 MLX 加速 1.4 到 1.9 倍,W4A8 则把权重内存减半。
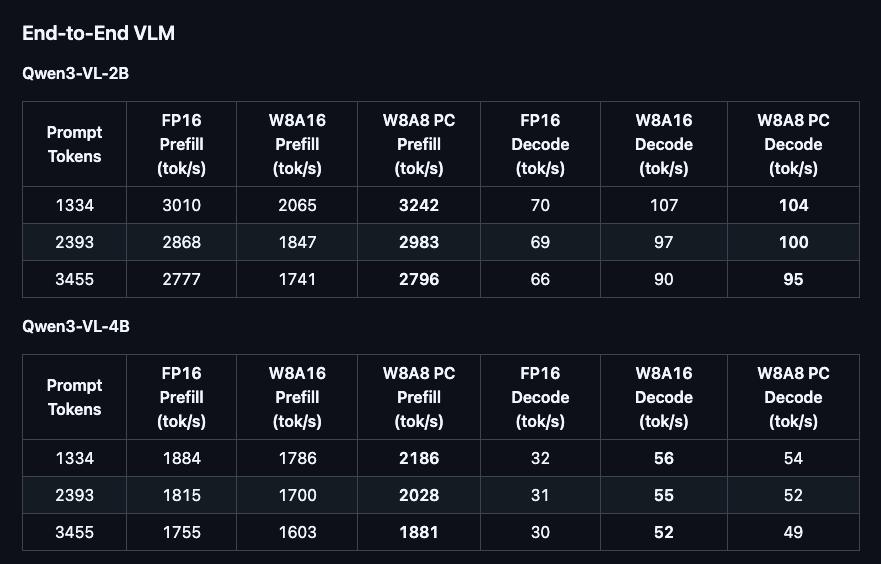
On Qwen3-VL, prefill speed reportedly rises 17 to 22 percent for 4B and 34 to 40 percent for 8B.
在 Qwen3-VL 上,4B 模型 prefill 提升 17% 到 22%,8B 模型提升 34% 到 40%。
Together, Cider and Mano-P frame a full edge-agent plan from model capability to engineering optimization.
把 Cider 和 Mano-P 放在一起看,明略想讲的是端侧智能体从模型到工程优化的一整套方案。
The next test is whether GUI agents stay reliable across Macs, interfaces, and permission environments.
下一步关键是复测:不同 Mac、不同界面、不同权限环境下,GUI agent 是否还能稳定完成任务。
Acorn Robot argues that robots need physical-world instinct, not only imitation from videos.
Acorn Robot 这篇报道把问题说得很直接:机器人不能只靠看视频学动作,还要有物理世界里的本能。
The critique targets pure VLA routes: models can understand language and images but may fail under force, friction, and disturbance.
它批评的对象是单纯 VLA 路线:模型能理解语言和画面,但遇到摩擦、力和干扰时,动作未必稳。
Acorn starts from operation primitives, touch, and force control to make robotic hands contact objects reliably.
Acorn 的解法是从底层操作原语、触觉和力控开始,先让机器手学会稳定接触。
The report highlights robots keeping hold of objects even when humans disturb them.
报道中特别强调,一个物体被人干扰时,机器人仍然能保持住,而不是立刻掉线。
Embodied instinct means building transferable action ability through hardware and software, not only more demonstrations.
这就是具身本能的含义:不是先堆更多示范数据,而是让软硬件协同形成可泛化的动作能力。
The team story is engineering-heavy, with nine Tsinghua PhD-background members and years of hardware and algorithm work.
团队背景也很工程化,文章说 9 位清华博士参与,并经历了多年硬件和算法探索。
Industrial lines are a natural target because objects vary and action errors are costly.
工业产线是它瞄准的第一类场景,因为那里物体变化多,动作容错又非常低。
This is less a replacement for VLA and more a physical control layer under it.
不过这还不是对 VLA 的替代结论,更像是给 VLA 补上真实接触控制的一层底座。
The next question is whether this instinct scales to long tasks and stable language-guided planning.
后续要看的,是这套本能能否扩展到复杂长任务,并和语言规划稳定结合。
Mind Lab frames LoRA as a thread for continual learning, not only a fine-tuning trick.
Mind Lab 这篇报道不是单讲一个 LoRA 技巧,而是把 LoRA 变成持续学习的一条主线。
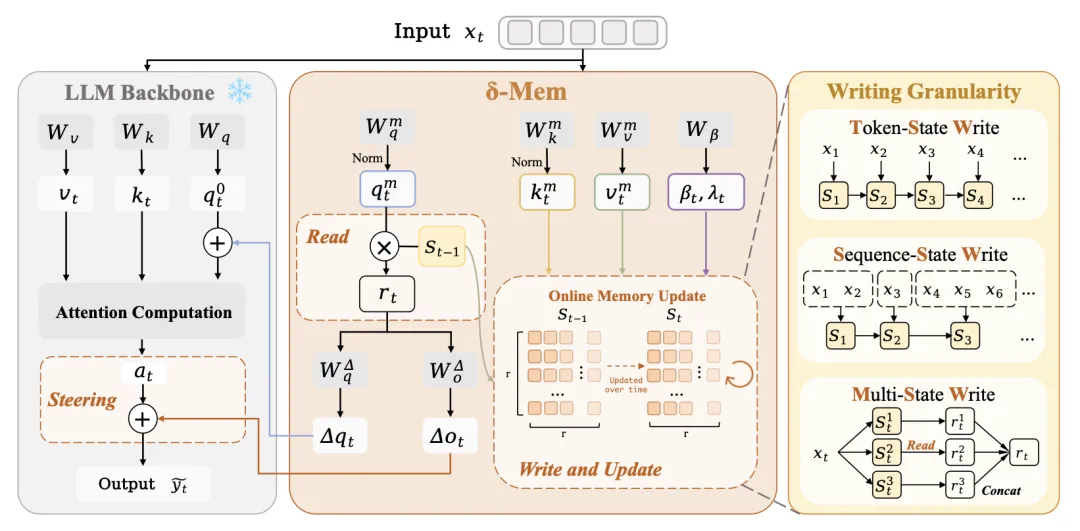
The first piece is delta-mem, a LoRA-shaped linear-attention module used as online memory.
第一块是 δ-mem:它把 LoRA 形态的线性注意力模块,用作模型的在线记忆。
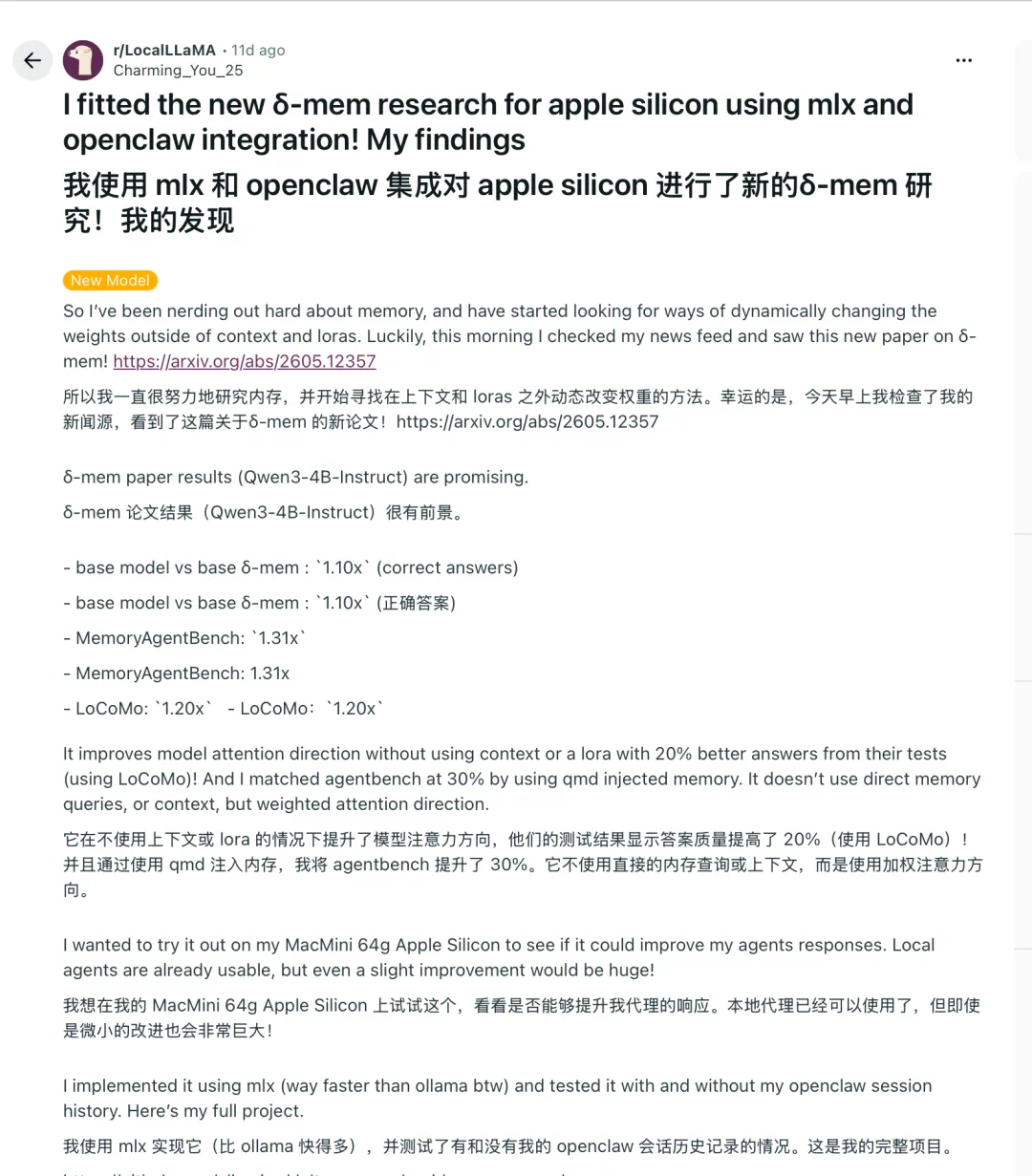
The report says an 8 by 8 memory state adds about 0.12 percent parameters while improving long-memory tasks.
报道说,8x8 的 memory state 只增加约 0.12% 参数,却能在长期记忆任务上带来明显提升。
On Memory Agent Bench it reports a 1.31x lift, and on LoCoMo a 1.20x lift.
在 Memory Agent Bench 上,δ-mem 提升 1.31 倍;在 LoCoMo 上,提升 1.20 倍。
The point is to learn reusable memory instead of stuffing all history back into context each time.
它的意义在于,模型不必每次把所有历史都塞进上下文,而是学习怎样保存可复用的信息。
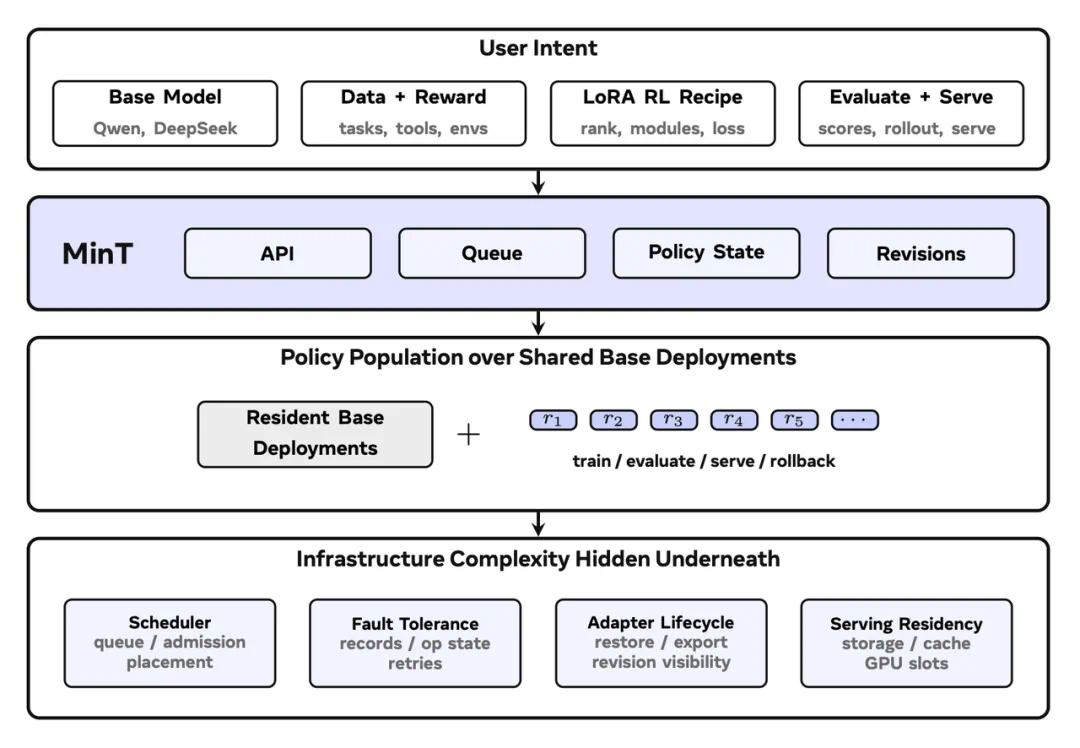
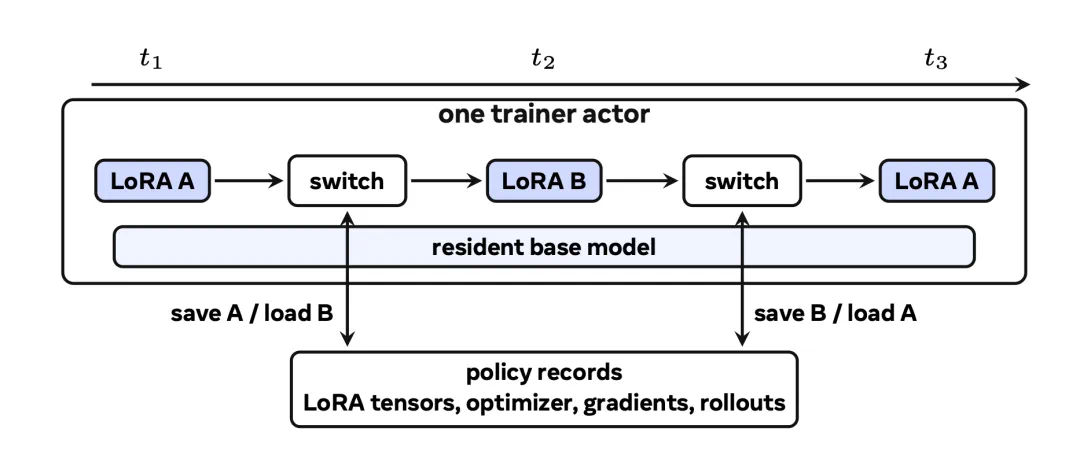
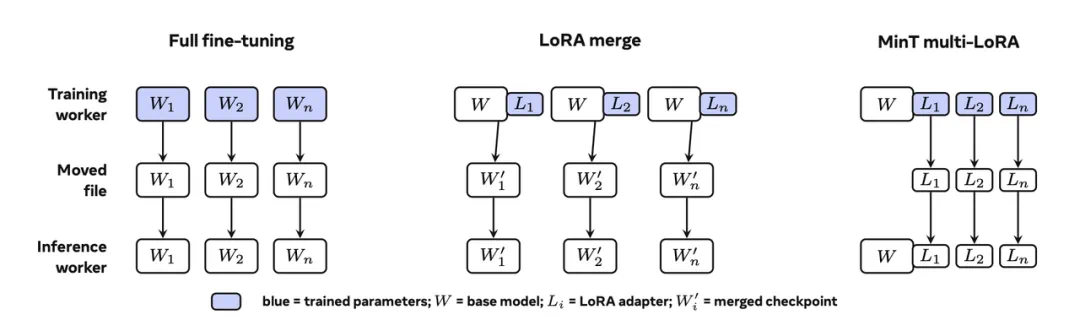
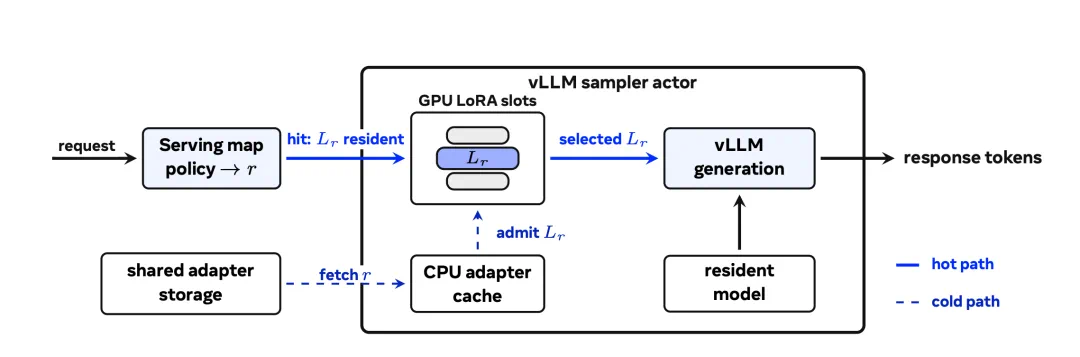
The second piece is MinT, shifting from algorithm to systems: training many adapters in parallel.
第二块是 MinT,重点从算法转到系统:怎样并行训练很多 adapter,而不是一个个慢慢跑。
The report claims MinT can reach about 4x training speed, important for batch adaptation.
报道称 MinT 最高能做到约 4 倍训练加速,这对企业批量适配任务非常关键。
The third piece is PEFT scaling, where base-model size and adapter size interact.
第三块是 PEFT scaling:它讨论基座模型规模和适配器规模不是孤立变量,而是会共同影响性能。
Low-cost adaptation is not simply about making adapters smaller; it needs a balance among base, task, and capacity.
这意味着,低成本适配不是越小越好,而是要找到基座、任务和 adapter 容量之间的平衡。
Macaron-A2UI pushes the idea into agents and UI tasks, where models learn to generate and use interfaces.
第四块 Macaron-A2UI 则把视角推到 agent 和界面任务,让模型不只学文本,还学怎样生成和使用界面。
Together, LoRA becomes an interface for memory, training, scaling, and interface action.
四块放在一起看,LoRA 从微调插件变成了记忆、训练、扩展规律和界面行动的共同接口。
Continual learning also brings risks: memory pollution, forgetting, and the need for auditable user data.
但持续学习也有风险:记忆会污染,旧知识会遗忘,用户数据还必须可控、可审计。
The deeper question is whether PEFT moves from a cost-saving tool into core infrastructure for long-running agents.
所以这篇报道真正值得看的,是 PEFT 是否会从省钱工具,变成长期 agent 的核心基础设施。
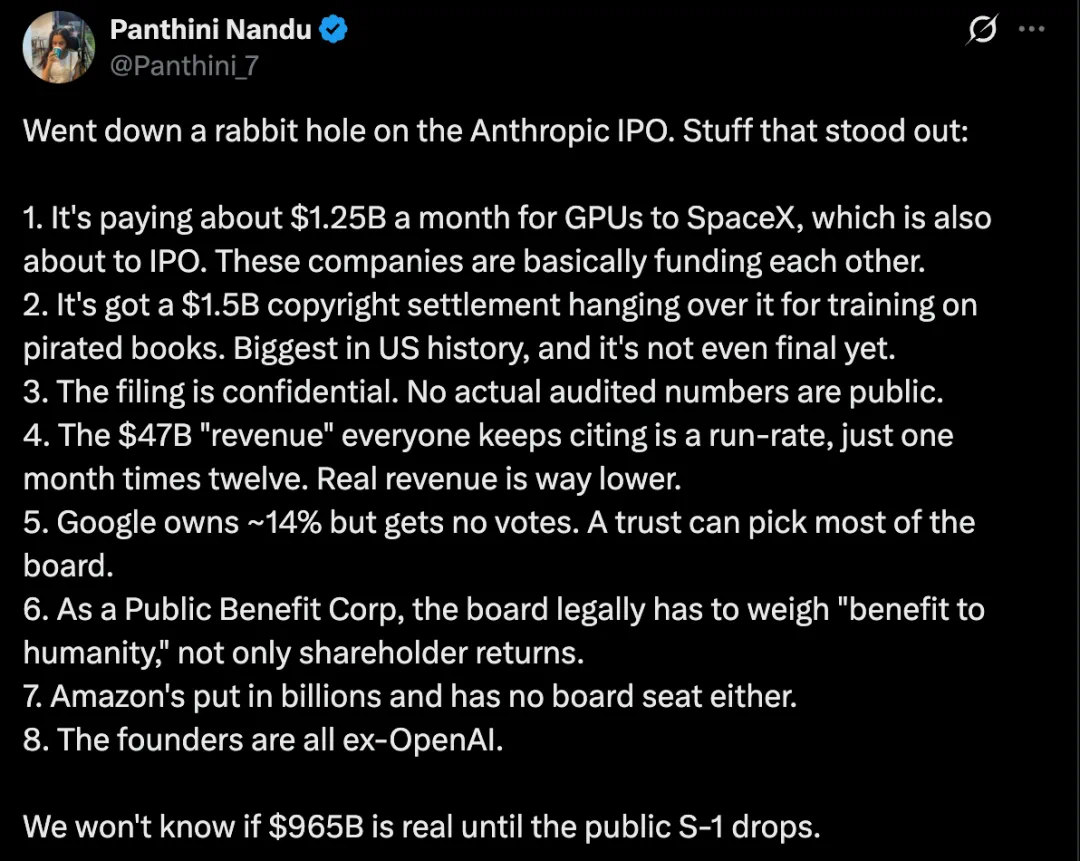
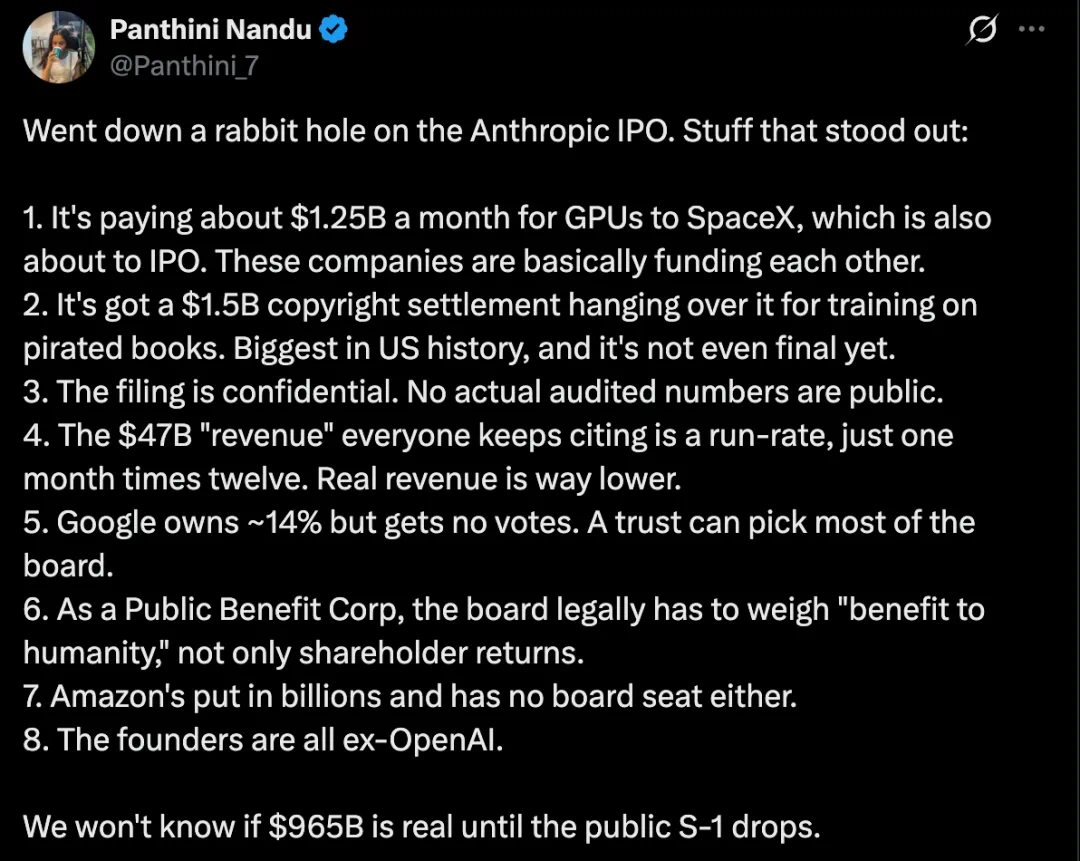
Anthropic's IPO news matters because a frontier model company may enter hard disclosure territory.
Anthropic 的 IPO 消息,重点不只是又一家 AI 公司要上市,而是前沿模型公司可能进入硬披露阶段。
The report says Anthropic has confidentially submitted an S-1 draft to the SEC.
报道称,它已经向美国 SEC 秘密提交 S-1 草案,为未来上市保留选择。
The market focus is valuation, with the article discussing a near-trillion-dollar path.
市场最关注的是估值:文章把 Anthropic 放进接近万亿美元市值的讨论里。
The narrative is supported by Claude model demand, Claude Code developer usage, and expected revenue growth.
支撑这个叙事的,是 Claude 模型热度、Claude Code 的开发者使用,以及收入增长预期。
An IPO would expose the hardest questions: training cost, inference economics, and customer concentration.
但 IPO 会把行业最难回答的问题摆出来:训练花多少钱,推理亏不亏,客户是不是足够分散。
If Anthropic lists, investors could systematically see revenue quality and capital spending for a frontier model business.
如果 Anthropic 真的上市,投资人第一次能系统看到前沿模型业务的收入质量和资本开支。
It would also affect financing logic and valuation references for OpenAI, xAI, Mistral, and others.
这也会反向影响 OpenAI、xAI、Mistral 等公司的融资逻辑和估值参照。
Confidential filing does not mean an immediate listing; timing, valuation, and structure can change.
不过秘密提交不等于马上挂牌,时间表、估值和发行结构都可能继续变化。
The real opening is public-market scrutiny of foundation-model economics.
所以这条新闻真正开启的,是资本市场对基础模型经济性的公开审题。
Deep Principle presents a more aggressive AI4S path: agents building a materials foundation model.
深度原理这篇报道讲的是一个更激进的 AI4S 方向:让智能体自己打造材料基座模型。
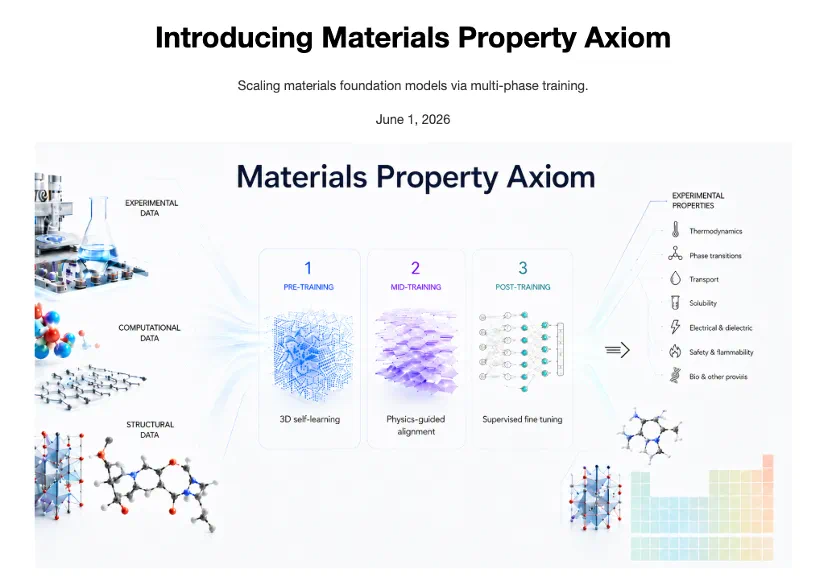
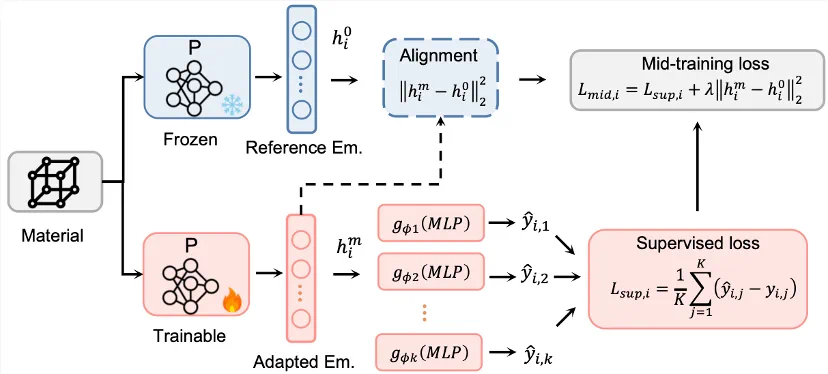
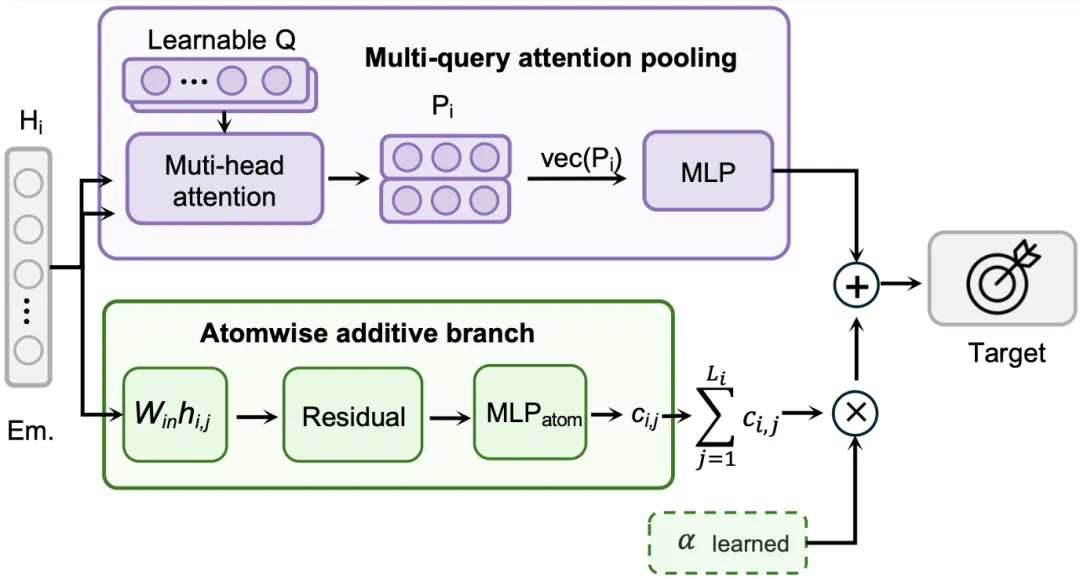
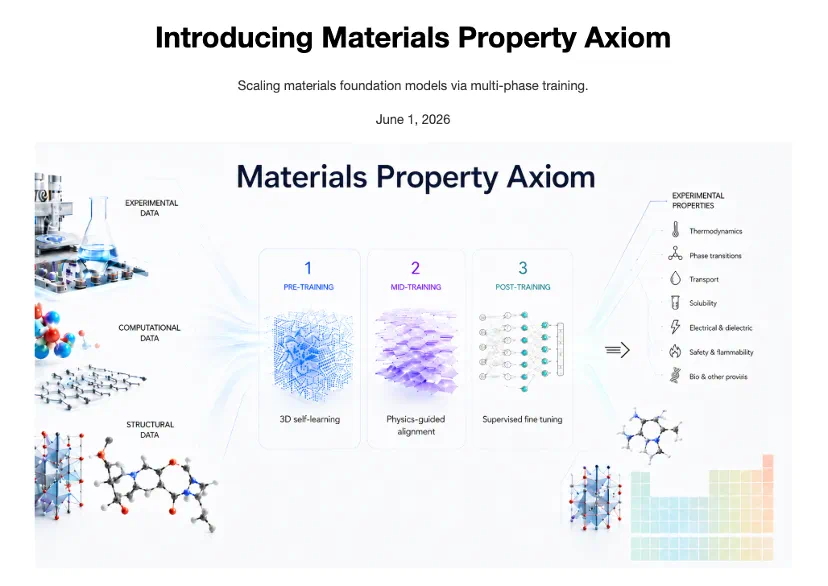
The new model is Materials Property Axiom, or MPA, aimed at general materials property prediction.
新模型叫 Materials Property Axiom,简称 MPA,目标是做通用的材料性质预测。
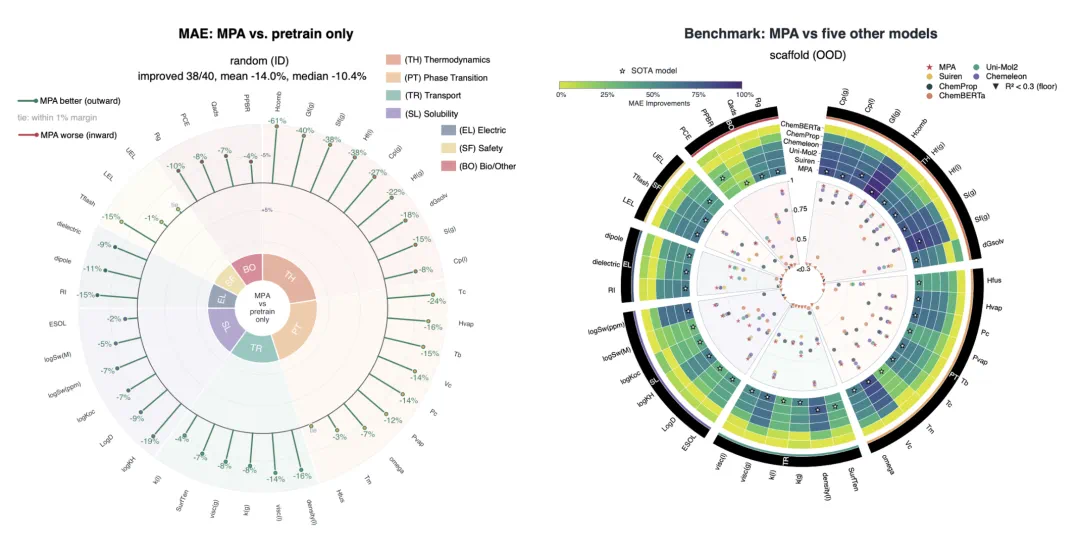
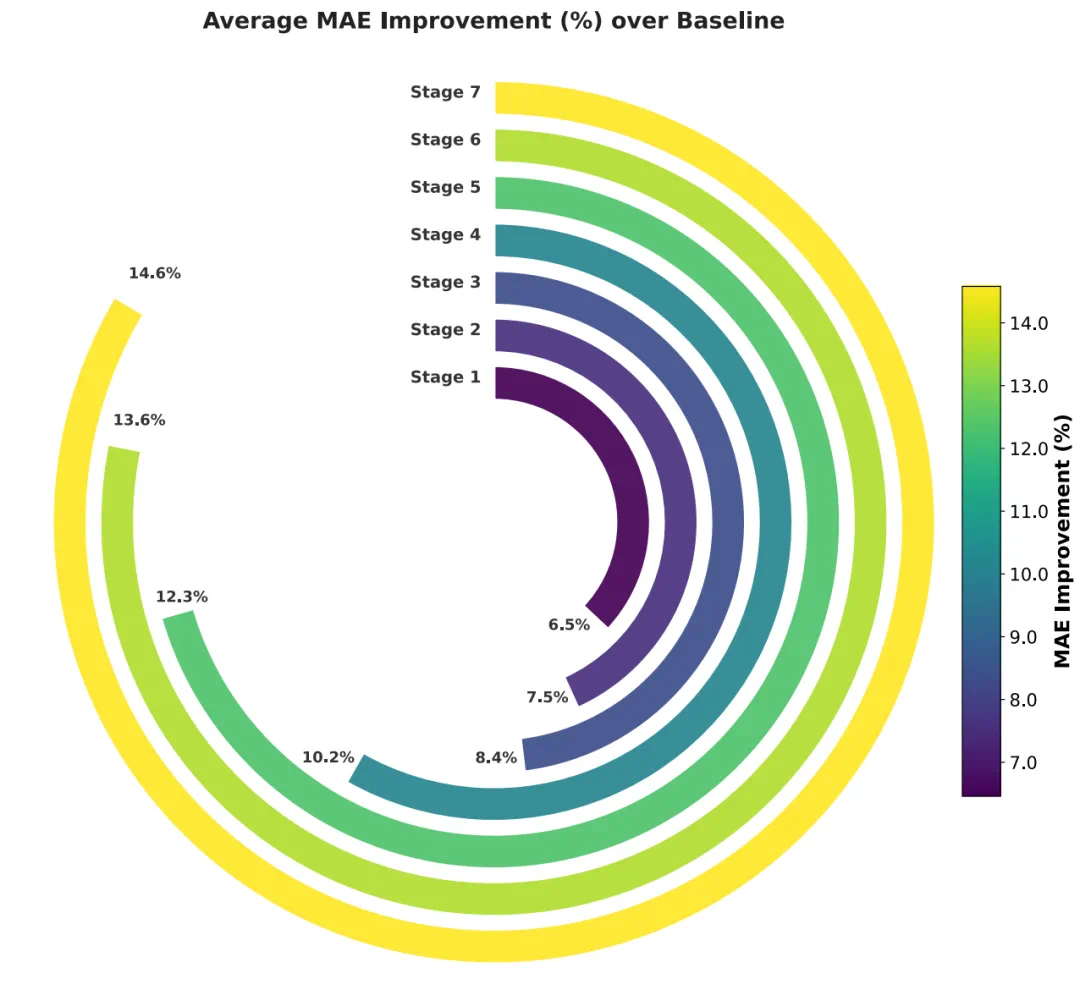
The article says MPA reaches SOTA across 40 experimental property prediction tasks, lowering average MAE by 10 percent.
文章称,MPA 在 40 项实验性质预测任务中全面刷新 SOTA,平均 MAE 降低 10%。
In the strongest case, the error reduction reaches 51 percent, more than a small tuning gain.
最强的单项结果中,误差降幅达到 51%,这让它不只是一个小幅调参成果。
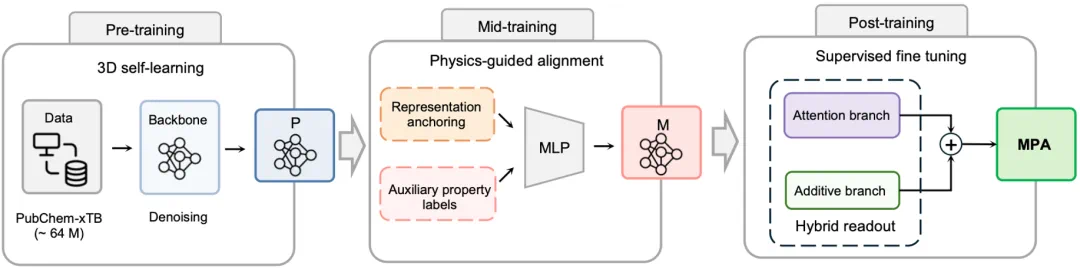
The special part is the workflow: MIRA reportedly handles research, architecture adaptation, coding, data construction, and iteration.
真正特殊的是研发流程:报道说 MIRA 参与预研、模型结构适配、代码编写、数据构造和迭代搜索。
AI is not only running scripts for scientists; it enters proposal and model modification stages.
也就是说,AI 不只是帮科学家跑脚本,而是进入了提出方案和修改模型的环节。
That is the recursive-agent idea: AI systems generating and optimizing the next scientific model.
这正是报道里所谓递归智能体的含义:AI 系统生成和优化下一代科学模型。
The article places MIRA in a broader trend alongside Google Co-Scientist, FutureHouse Robin, and Google ERA.
文章也把 MIRA 放进更大的趋势里,对比 Google Co-Scientist、FutureHouse Robin 和 Google ERA。
Materials science fits this path because candidates are many, experiments are costly, and single-task models are narrow.
材料领域适合这种路线,因为候选结构多、实验成本高,单任务模型又很难覆盖所有性质。
If MPA holds up, researchers may reduce repeated data cleaning and model selection from scratch.
如果 MPA 成立,研究者可以少做很多从零开始的数据清理和模型选择。
But SOTA claims need reproduction through data, code, splits, and cross-lab evaluation.
不过这类 SOTA 新闻一定要看复现:数据、代码、划分方式和跨实验室评测都很关键。
It is also important to separate human design, automatic search, and gains from data processing.
还要区分,哪些设计来自人类,哪些来自自动搜索,哪些只是数据整理带来的收益。
The value is moving AI autonomous research from concept demos into the hard task of materials foundation models.
所以这条新闻的价值,是把 AI 自主科研从概念展示,推到材料基座模型这个硬任务上。
DataMaster asks whether AI can perform its own data engineering when data determines model limits.
DataMaster 关注的是一个很现实的问题:如果数据决定模型上限,AI 能不能自己做数据工程。
It lets the system find external data sources, filter, clean, transform, and build training inputs.
它让系统主动找外部数据源,再过滤、清洗、变换,最后构造训练输入。
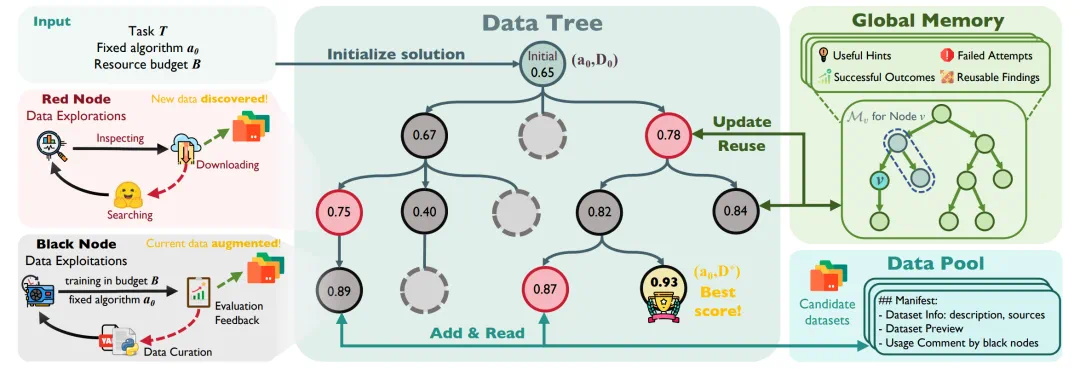
The framework uses a data tree, data pool, and global memory to track sources, operations, and feedback.
框架里有数据树、数据池和全局记忆,用来记录来源、操作步骤和实验反馈。
Red nodes seek new sources, black nodes clean and combine data, and downstream performance guides the loop.
红色节点负责找新来源,黑色节点负责清洗和组合数据,下游模型表现再反过来指导搜索。
This turns AI research agents from code writers into systems that handle the slow data side of experiments.
这让 AI research agent 不只是写代码,也开始接管实验里最耗时的数据部分。
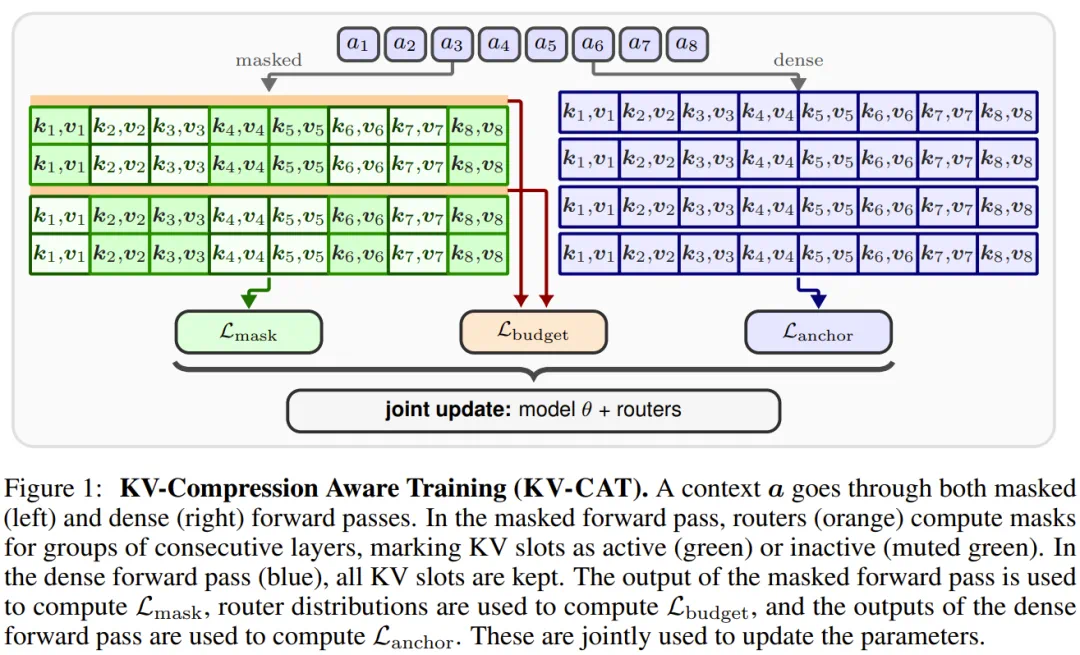
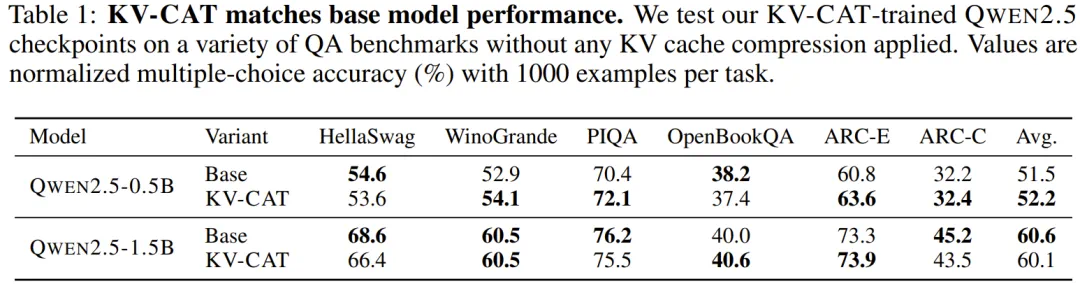
This paper targets a hard cost in long-context models: KV Cache grows with sequence length.
这篇论文讨论长上下文模型的一个硬成本:序列越长,KV Cache 占用越大。
Many methods compress cache after inference; KV-CAT puts compressibility into training.
过去很多方法是在推理后压缩缓存,KV-CAT 则把压缩友好性放进训练目标。
In other words, the model learns to create intermediate memory that is easier to keep or prune.
换句话说,模型提前学会生成更容易被保留和裁剪的中间记忆。
A word-frequency task shows that natural implementations are not always compression-friendly; structured ones can be.
文章用词频任务说明,自然实现未必压缩友好,结构化实现才更适合长程缓存。
The key is saving memory without losing the information needed for reasoning.
核心问题是,压缩省显存的同时,不能牺牲模型真正需要的推理信息。
This Sutton-related work is about how AI should understand the world, not bigger models.
Sutton 相关这篇新作,讨论的不是更大的模型,而是 AI 应该怎样理解世界。
It criticizes passive representation: encoding the world internally is not the same as participating in it.
它批评被动表征路线:模型只把世界编码进内部表示,并不等于真正参与世界。
Enactive cognition says perception, action, and environment interaction happen together, not as isolated modules.
生成认知强调,感知、行动和环境互动是一起发生的,不能拆成孤立模块。
A key idea is that the world is the best model, and agents update cognition through action.
文章里的关键思想是,世界本身就是最好的模型,智能体要通过行动不断校正认知。
This matters for robots and agents because real autonomy is tested through environmental feedback.
这对机器人和 agent 很重要,因为真实自主性最终要在环境反馈里被检验。
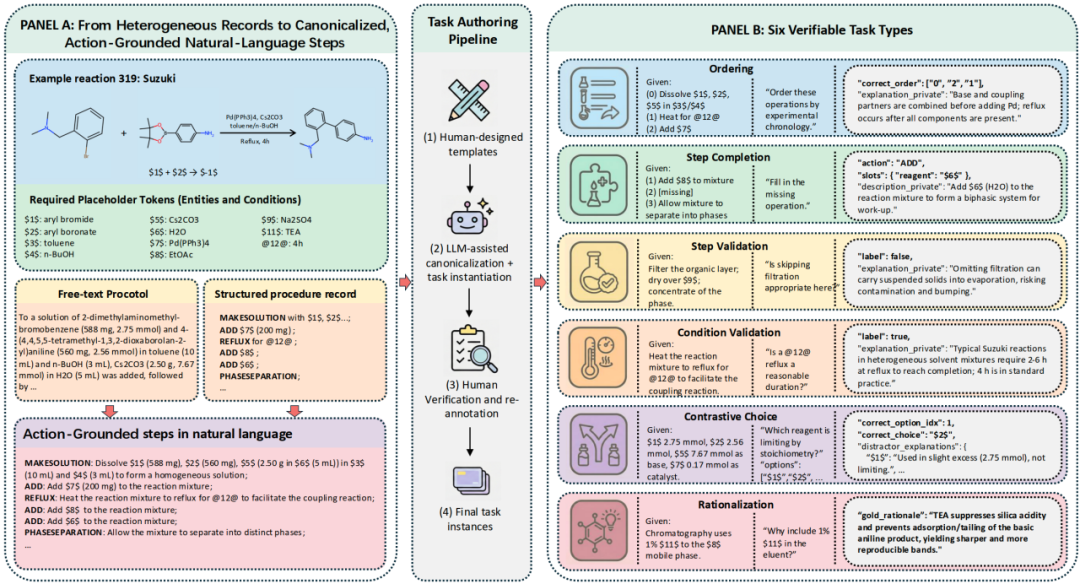
ChemReason-Bench asks whether LLMs understand synthesis procedures, not only chemistry facts.
ChemReason-Bench 问的是,大模型能不能真的理解化学合成步骤,而不只是背化学知识。
The benchmark covers 500 organic reactions and 7,306 manually verified tasks.
这个基准覆盖 500 个有机反应和 7306 个手工校验任务。
Tasks include step ordering, verification, condition checking, completion, contrastive selection, and principle explanation.
任务包括步骤排序、步骤验证、条件验证、步骤补全、对比选择和原理解释。
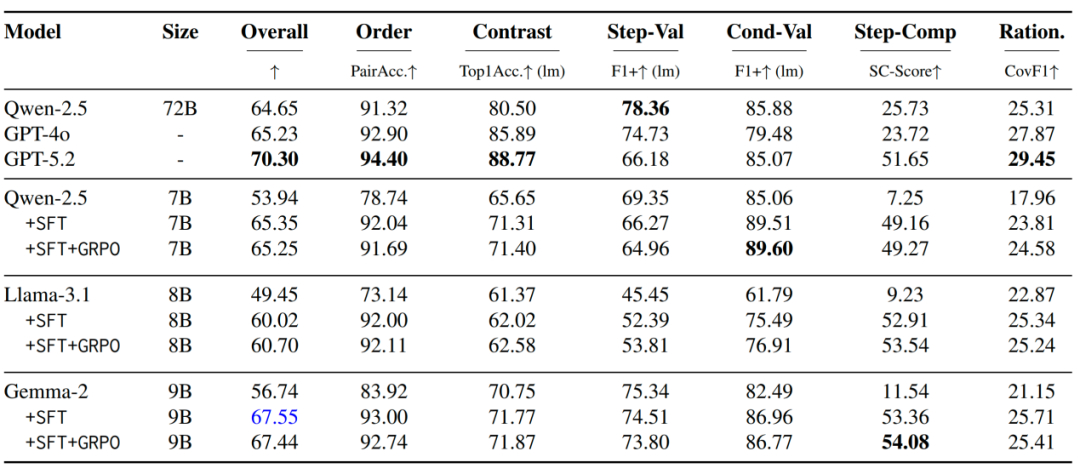
GPT-5.2 scores 70.30 and DeepSeek-v3.2 scores 65.21, but step completion remains hardest.
评测里,GPT-5.2 总分 70.30,DeepSeek-v3.2 为 65.21,但步骤补全仍然最难。
This shows AI chemistry assistants still need procedural logic and safety constraints before real experiments.
这说明 AI 化学助手离真实做实验还有距离,因为实验流程需要程序逻辑和安全约束。
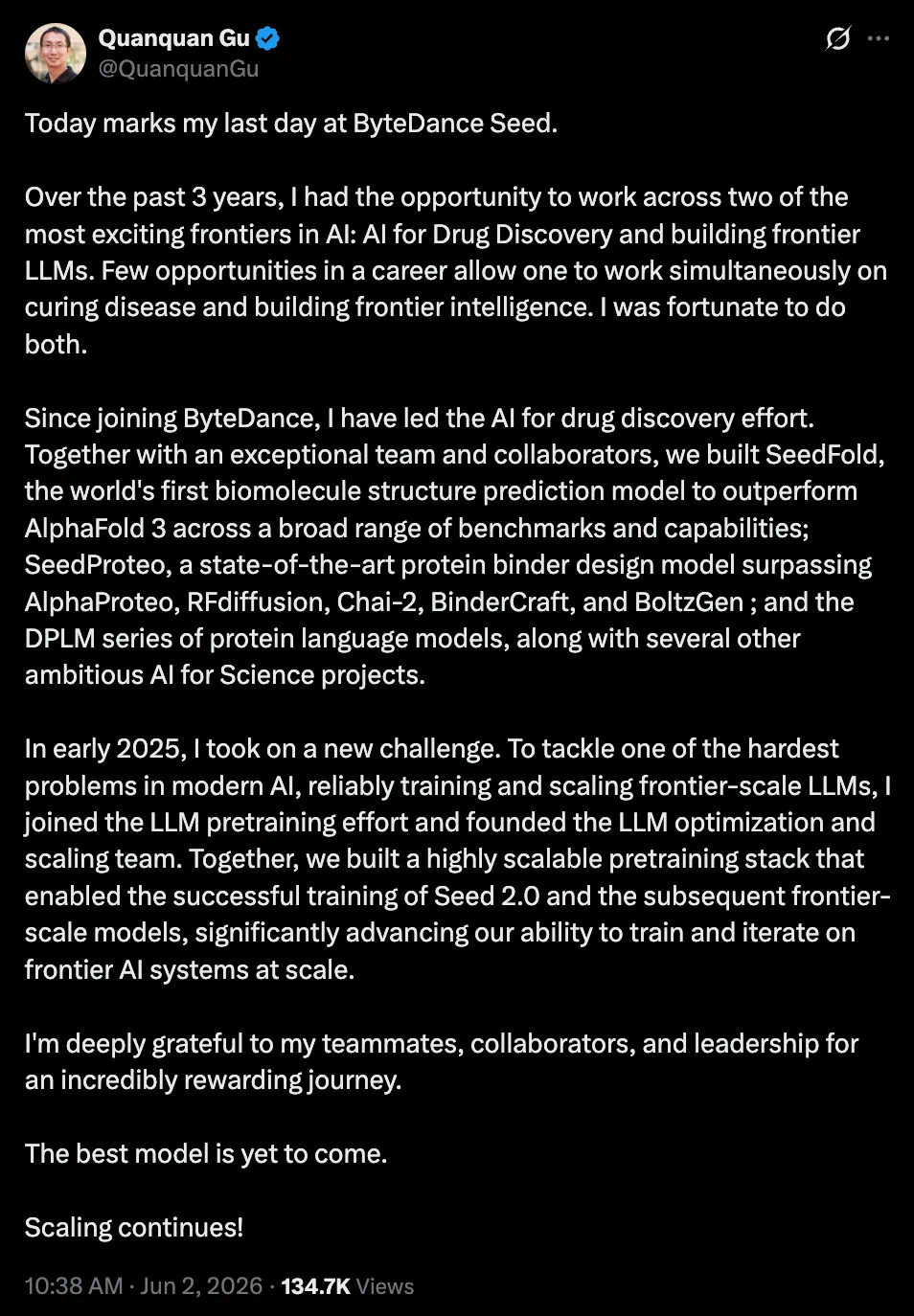
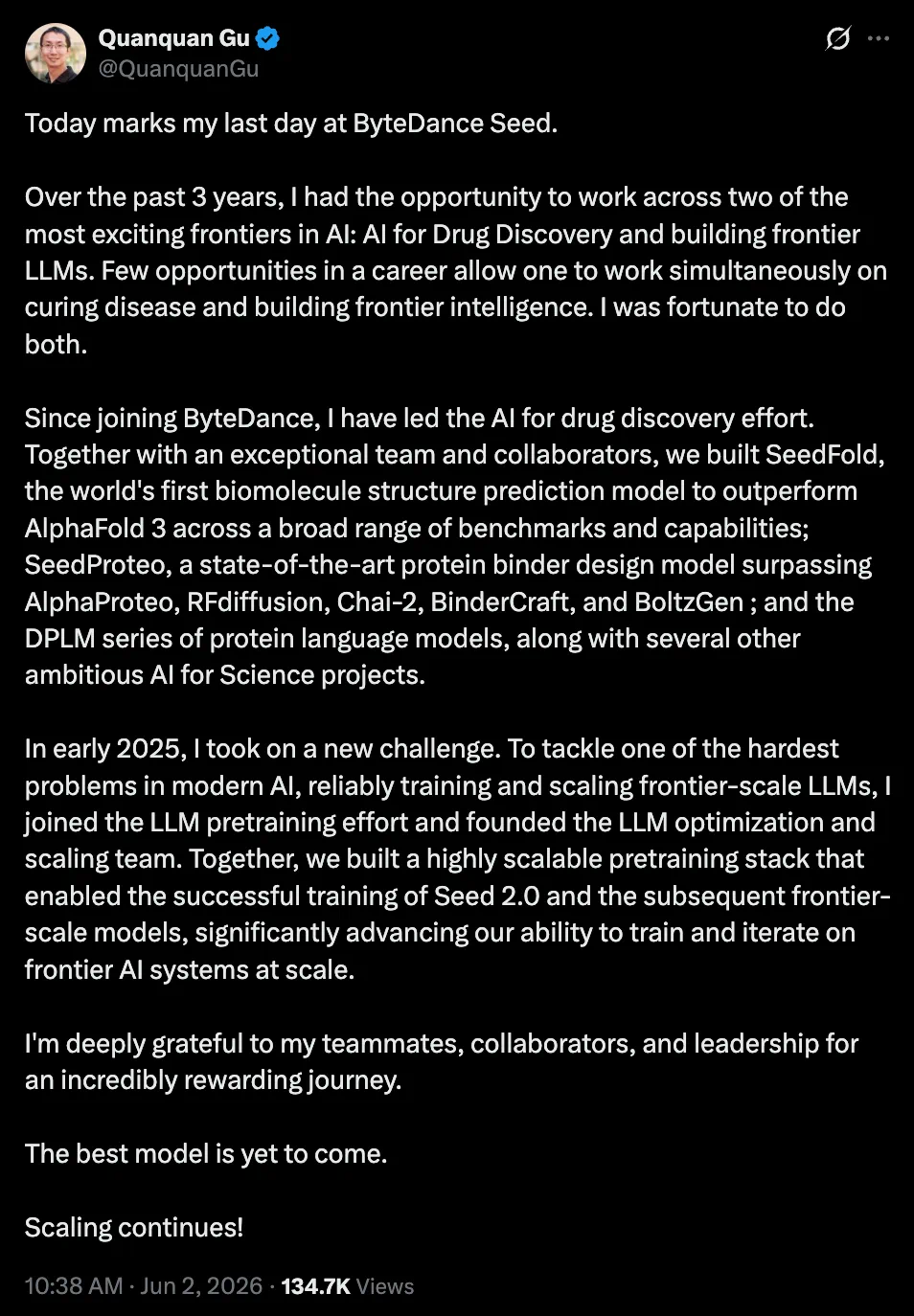
Gu Quanquan leaving ByteDance Seed is personnel news, but it reflects rising AI4S competition.
顾全全从字节 Seed 离职,表面是人事新闻,背后其实是 AI4S 方向的竞争升温。
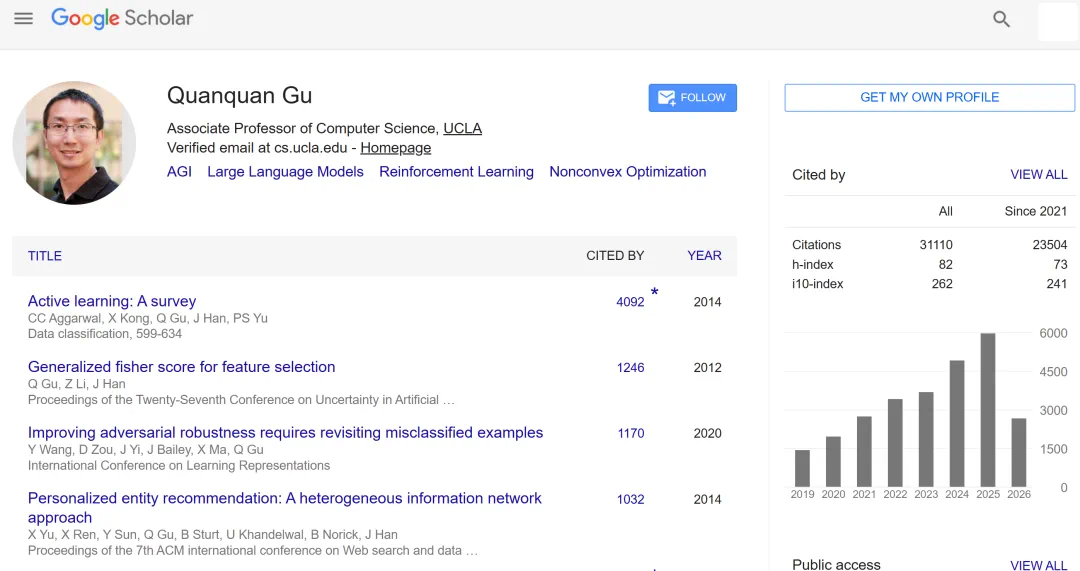
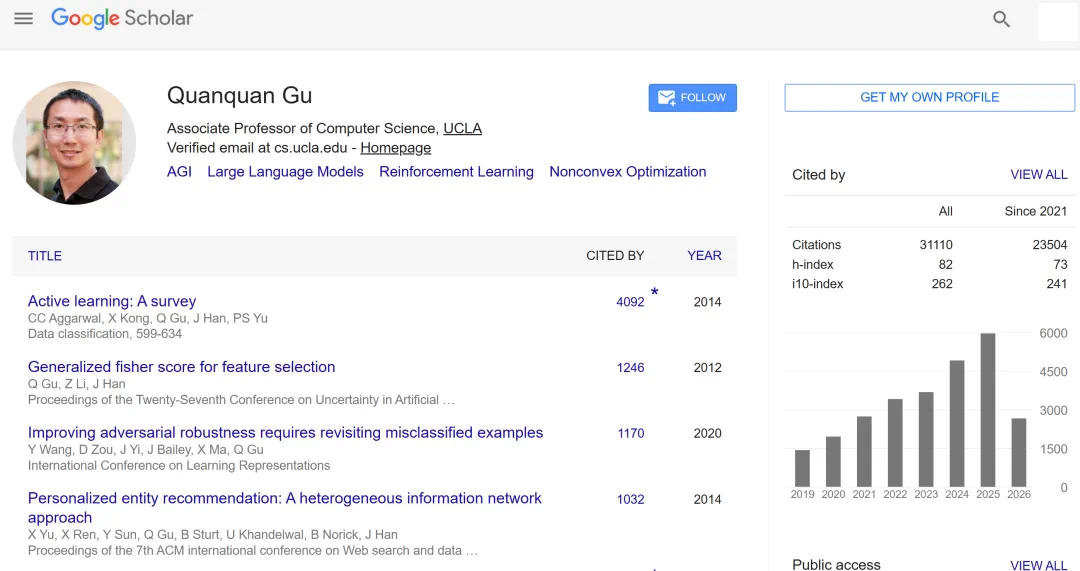
The report notes his UCLA background and work across AI drug discovery, protein design, and large-model training.
报道回顾,他曾任 UCLA 终身副教授,研究覆盖 AI 药物发现、蛋白质设计和大模型训练。
At Seed, the directions include SeedFold, SeedProteo, DPLM, and LLM optimization and scaling.
在字节 Seed,他参与的方向包括 SeedFold、SeedProteo、DPLM,以及 LLM 优化和 scaling。
The article says SeedFold beats AlphaFold 3 on several capabilities, while SeedProteo targets binding protein design.
文章称 SeedFold 在多项能力上超过 AlphaFold 3,SeedProteo 则面向 binding protein 设计。
These projects show AI4S is no longer peripheral; it links drugs, proteins, and foundation models.
这些项目说明,AI4S 已经不是大模型公司的边缘研究,而是能连接药物、蛋白和基础模型的核心赛道。
The report mentions team changes and possible startup plans, but those need official confirmation.
报道还提到团队调整和可能创业,但这部分仍需要等待本人或新公司的正式确认。
The key question is whether AI4S talent stays in big labs or moves into focused startups.
真正值得跟踪的是,AI4S 人才会继续留在大厂,还是转向更聚焦的新公司。
Either way, proteins, materials, and drug discovery remain important testbeds for foundation-model commercialization.
无论哪种结果,蛋白质、材料和药物发现都会继续成为基础模型商业化的重要实验场。