MiniMax M3 is framed as one open model combining coding agents, million-token context, and native multimodality.
MiniMax M3 的重点不是又一个新模型,而是把编程智能体、百万上下文和原生多模态放进同一个开源模型叙事里。
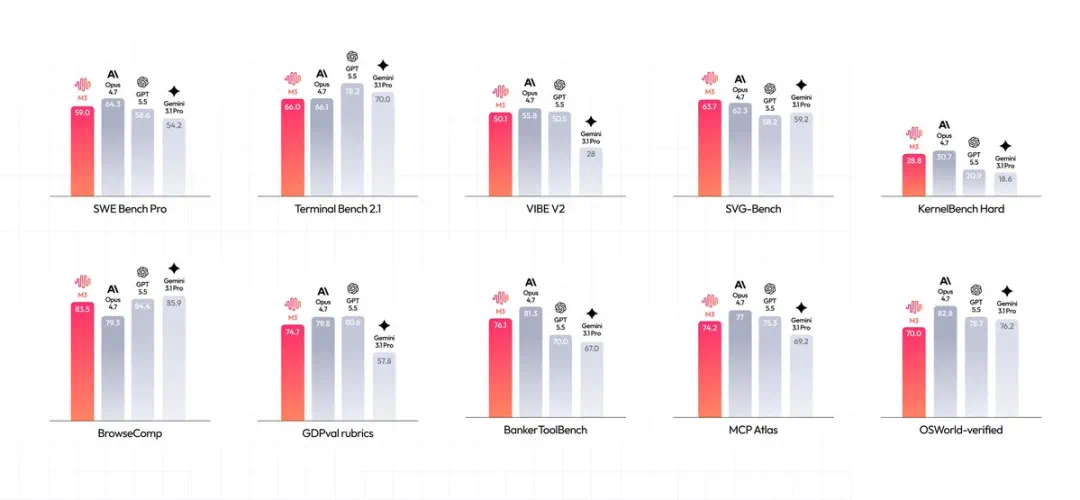
The report says M3 reaches the top tier on coding and agent benchmarks, with emphasis on real engineering tasks.
报道称,M3 在 SWE-Bench Pro、Terminal Bench、KernelBench 和 Claw-Eval 上都进入第一梯队,尤其强调真实工程任务能力。
A long-running optimization case shows the model iterating for about a day and lifting GPU kernel utilization.
更有意思的是长线程优化案例:模型连续运行约二十四小时,提交一百四十七次 benchmark,把 GPU kernel 利用率大幅推高。
For multimodality, the demo shows M3 combining visual cues and text instructions rather than only naming the image.
多模态部分,文章用一个界面演示说明,M3 不只是识别图像,还会把可见线索和文字任务结合起来逐步判断。
In an agent task, M3 is reported to search pricing pages, organize data, and add extra comparison features.
在 agent 任务里,文章说 M3 会主动检索价格页、整理数据,并额外做出分组对比、汇率换算和主题切换。
Another test gives a broad writing request, and M3 returns markdown plus image assets after sixteen minutes.
另一个测试只给一句开放式写作请求,M3 在十六分钟后交付 markdown 和图片文件夹,显示它能处理长资料整理任务。
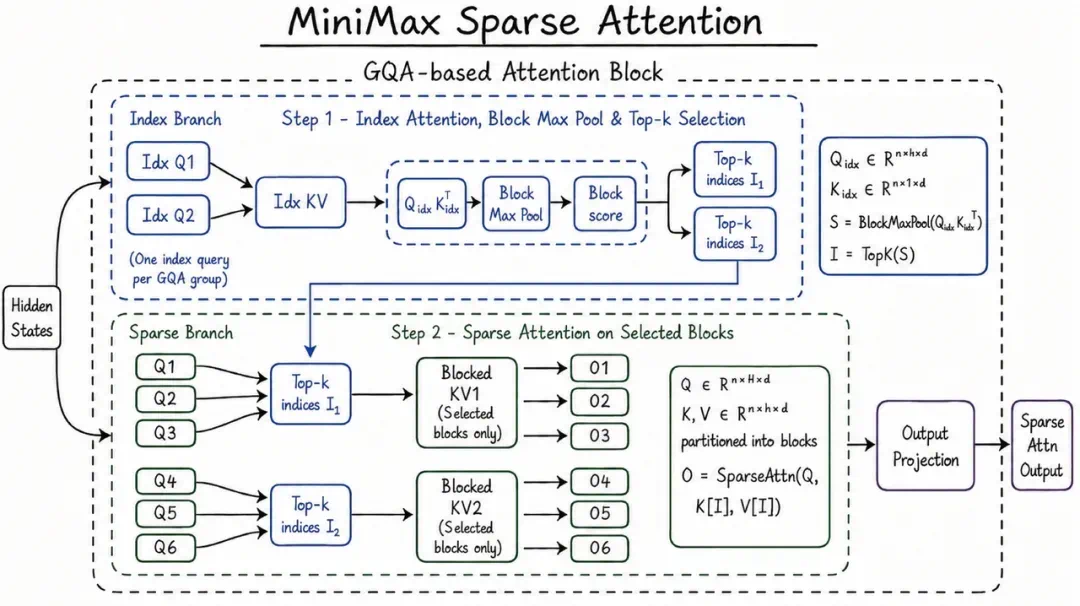
The long-context claim is tied to MiniMax Sparse Attention, designed to control the cost of million-token context.
长上下文能力来自 MiniMax Sparse Attention,报道说它用稀疏注意力缓解一百万 token 带来的计算膨胀。
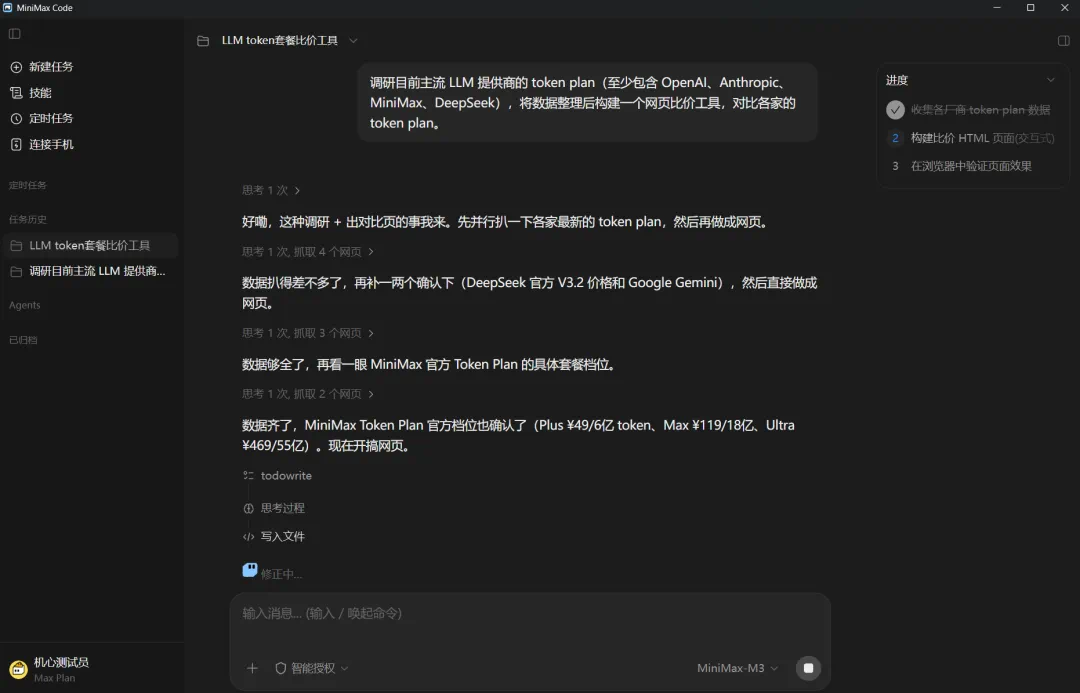
MiniMax Code splits large tasks into stages and uses Producer and Verifier loops for long unattended runs.
配套产品 MiniMax Code 则把大任务拆成多阶段,由 Producer 和 Verifier 循环推进,目标是让 agent 长时间无人干预运行。
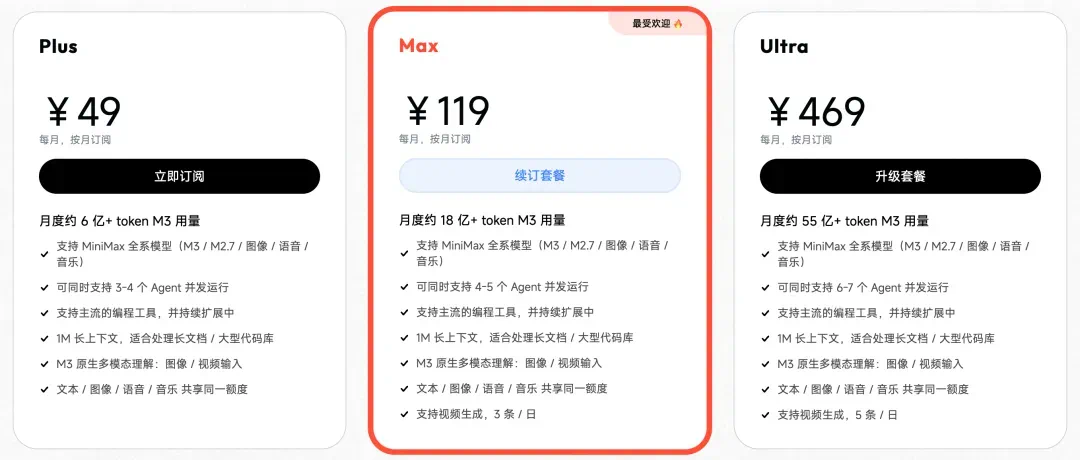
The commercial angle is aggressive pricing, which the report says could affect developer adoption.
商业侧同样激进,文章列出低价 token 套餐和 API 计费,认为 M3 的性价比会直接影响开发者采用。
The key caveat is verification after weights and the technical report are released.
但关键仍在后续验证:权重和技术报告发布后,M3 才能在第三方复测里证明 frontier 三件套是不是稳定成立。
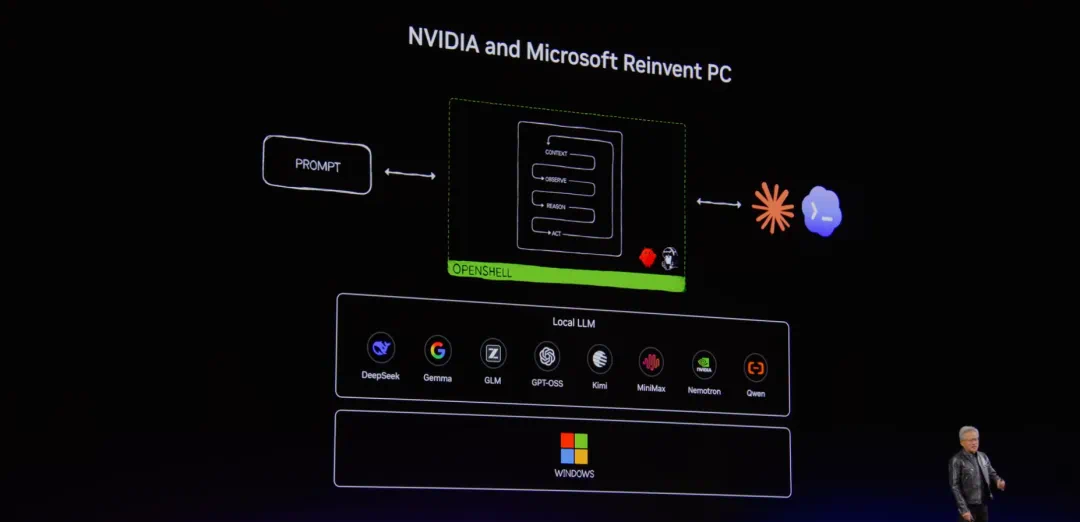
NVIDIA is pitching the Windows PC as a local AI agent platform, not just a new chip.
英伟达这次讲的不是单颗芯片,而是把 Windows PC 重新包装成本地 AI Agent 的运行平台。
The keynote connects this PC push with NVIDIA's broader AI compute roadmap.
发布会现场,黄仁勋把这条线索和 Vera、Rubin 等数据中心路线并排放置,强调 AI 计算正在进入个人设备。
The core hardware is RTX Spark, positioned for local models, creative workflows, and personal agents.
核心硬件是 RTX Spark,报道说它与微软协作,面向本地模型、创意工作流和个人 agent 设计。
The reported specs include a Blackwell RTX GPU, 6144 CUDA cores, fifth-generation Tensor Cores, and a Grace CPU.
参数上,文章提到 Blackwell RTX GPU、六千一百四十四个 CUDA 核心、第五代 Tensor Core 和 Grace CPU。
It can appear in thin Windows laptops or compact desktops, compressing AI workstation capability into personal devices.
它既可以进入轻薄 Windows 笔记本,也可以做成小型高能效台式机,目标是把 AI 工作站能力压缩到个人设备里。
NVIDIA is also pulling hardware vendors into an RTX Spark AI PC ecosystem.
英伟达还把硬件生态拉进来,各大厂商围绕 RTX Spark 开发不同形态的 AI PC 产品。
Microsoft's role is the system layer, with Windows framed as a secure platform for local agents.
微软的角色在于系统平台:报道强调 Windows 要为本地 agent 提供强大且安全的运行环境。
The user experience vision is to ask the PC to complete cross-application tasks in natural language.
用户体验层面,文章设想人们不再只点击应用,而是用自然语言让 PC 完成跨应用任务。
For creators and developers, the test is app support, AI acceleration, and reliable local model execution.
对创作者和开发者来说,真正要看的还是应用适配、生成式 AI 加速和本地模型运行能否稳定落地。
Project Eden starts from a clear critique: many world models generate video without maintaining a world state.
Project Eden 的问题意识很直接:现在许多世界模型会生成视频,但不一定真的维护一个世界。
The report says a real world should preserve state when the camera moves away and remain consistent for multiple users.
文章说,真正的世界要能保存状态,镜头转走后物体仍然存在,多人进入时看到的也应是同一个场景。
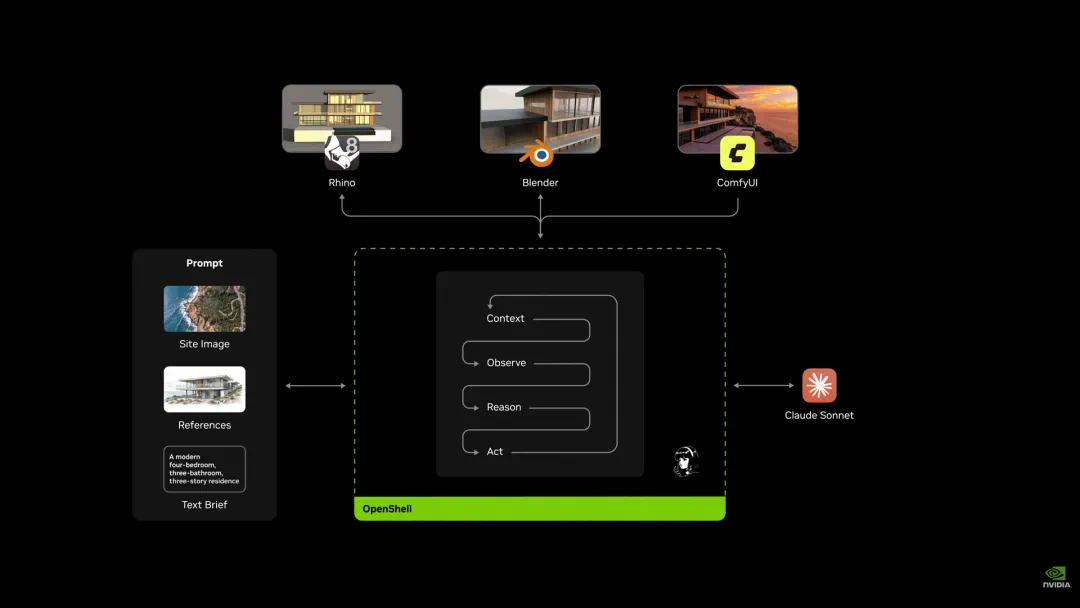
Its proposed route decouples world-state evolution from visual rendering, so state exists before the image is shown.
Project Eden 的技术路线是把世界状态推演和视觉呈现解耦,让底层状态先存在,再把它渲染成画面。
That means it is not only predicting the next frame, but trying to let user actions keep changing one environment.
这意味着它不是简单预测下一帧,而是试图让用户动作持续改变同一个环境。
Multi-user consistency adds another requirement: different roles and views should align to the same underlying world.
多人一致性则是另一层要求:不同角色、不同视角进入,也要对齐到同一个底层世界。
The support comes from VAST's Tripo 3D models, with Tripo P1.0 reported to generate professional-grade 3D assets in two seconds.
VAST 的支撑来自 Tripo 系列 3D 大模型,文章称 Tripo P1.0 能在两秒内生成专业建模师级别的 3D 模型。
Tripo H3.1 and 8K texture work are used to argue for detailed assets, materials, and structural quality.
Tripo H3.1 和 8K 贴图算法则被用来说明资产细节、材质和结构完整性。
Segmentation V2 splits 3D assets into operable parts, supporting the shift from asset generation to world operation.
Segmentation V2 进一步把 3D 资产拆成可操作部件,为从模型生成走向世界运行提供基础。
So the core question is not visual polish, but whether world state can persist, update, and be shared.
因此,报道的重点不是画质炫技,而是世界状态能不能长期保存、被动作更新、被多人共享。
If it works, it could affect game prototyping, simulation training, virtual spaces, and embodied data generation.
如果成立,它会影响游戏原型、仿真训练、虚拟空间和具身智能数据生成。
But the article does not provide standardized evaluation, so this remains a system claim and demo rather than external proof.
但文章没有给出标准化评测,所以我们只能把它当作系统路线和演示主张,而不是已被外部验证的结论。
The demos are short, so the real test is long navigation, revisiting scenes, and multi-user synchronization.
四段演示都很短,后续真正要看的,是长时间导航、跨视角回访和多人同步时状态是否仍然一致。
That is why the article places Project Eden after Tripo: generated assets first, runnable worlds next.
这也解释了为什么文章把 Project Eden 放在 Tripo 之后:先有可生成资产,再谈可运行世界。
In short, Project Eden tries to move world models from generating video to generating a stateful world.
一句话说,Project Eden 是把世界模型从生成视频推向生成状态机的尝试。
Its value and risk share one point: if state can persist, generated spaces become environments rather than media assets.
它的价值和风险都在同一点:如果状态真的可保存,AI 生成空间就会从素材变成环境。
Galaxea G0.5 argues that embodied AI needs a different VLA action-generation design, not only more data.
星海图 G0.5 的主张是,具身智能不只靠更多数据,还要重新设计 VLA 模型的动作生成方式。
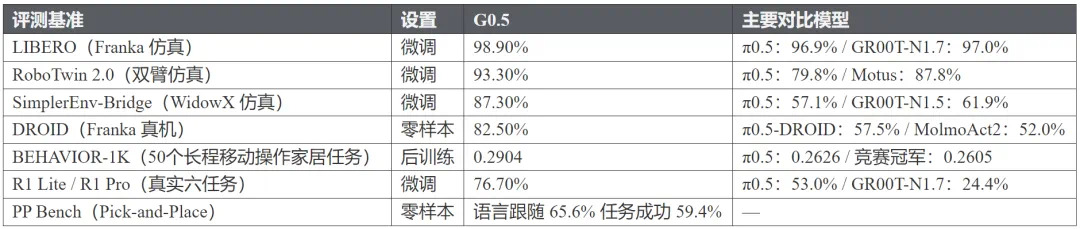
The report compresses the claim into seven benchmarks across simulation, real robots, zero-shot transfer, and long-horizon tasks.
文章把结果压缩成七个基准:仿真、真机、零样本迁移和长程任务都被放进同一张成绩单。
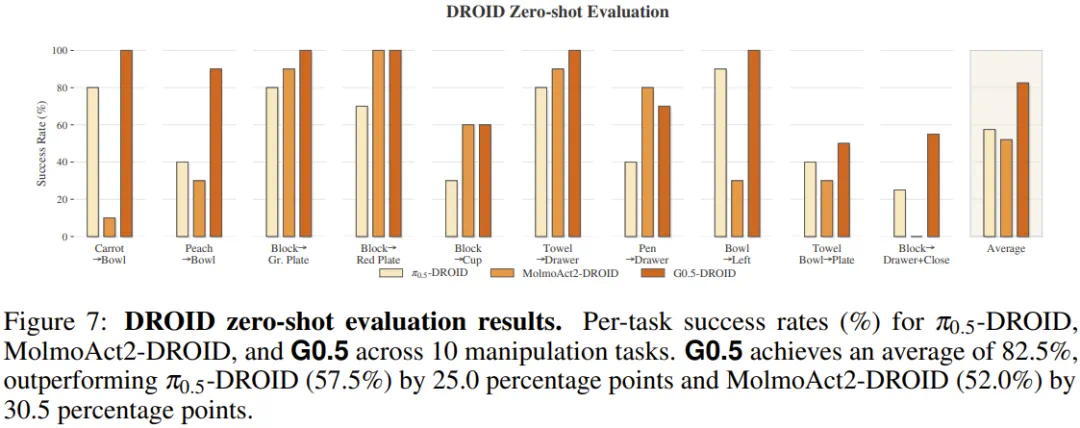
On DROID zero-shot transfer, G0.5 is reported at 82.5 percent average success, 25 points above pi-zero-point-five DROID.
在 DROID 零样本迁移中,报道称 G0.5 平均成功率达到 82.5%,比 π0.5-DROID 高二十五个百分点。
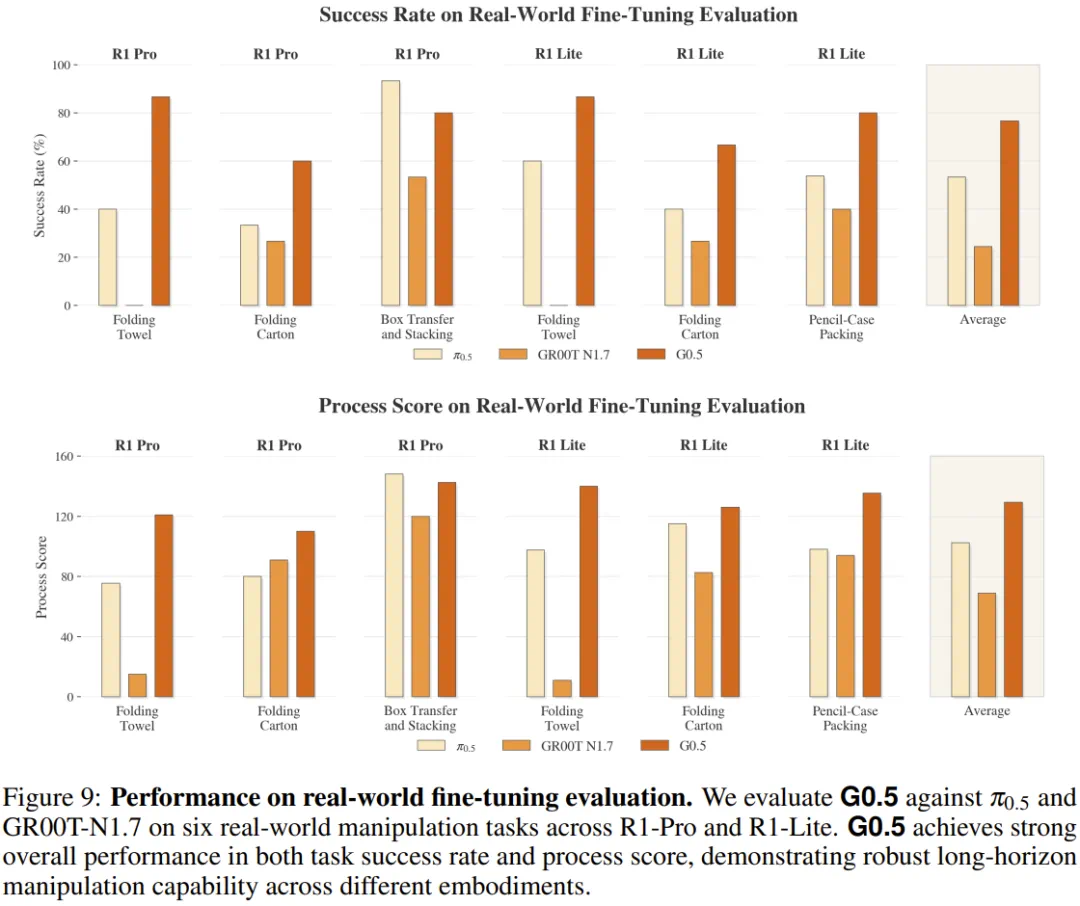
On Galaxea's own platform, with the same data and compute budget, G0.5 leads on complex manipulation tasks.
在星海图自研平台上,同等训练数据和计算预算下,G0.5 也在折毛巾、整理铅笔盒等复杂任务中领先。
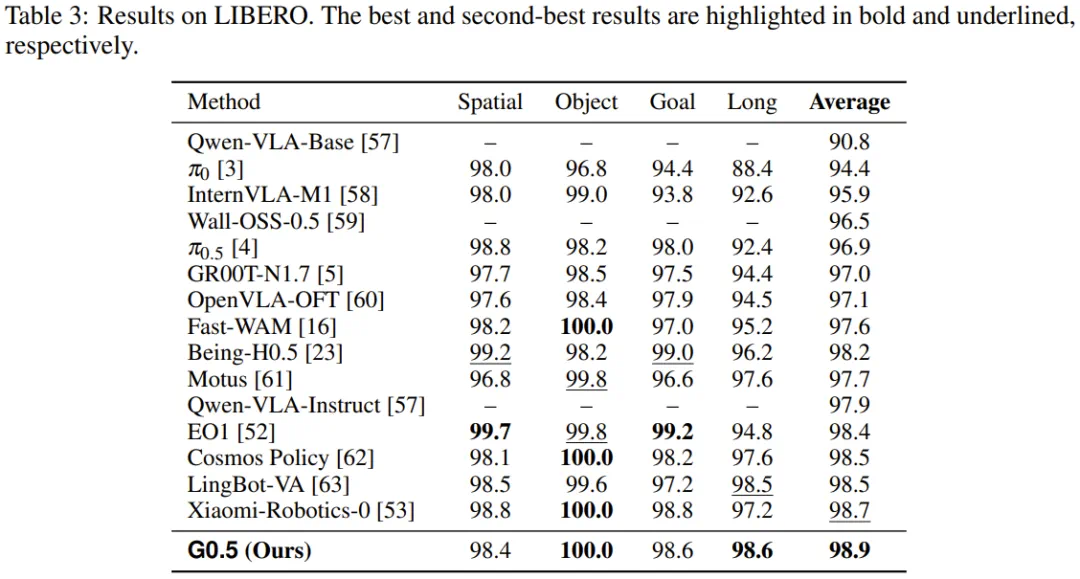
LIBERO and RoboTwin emphasize long sequences and dual-arm manipulation, where the report says G0.5 resets several public marks.
LIBERO 和 RoboTwin 则强调长程序列与双臂操作,文章称 G0.5 在公开结果中刷新了多个位置。
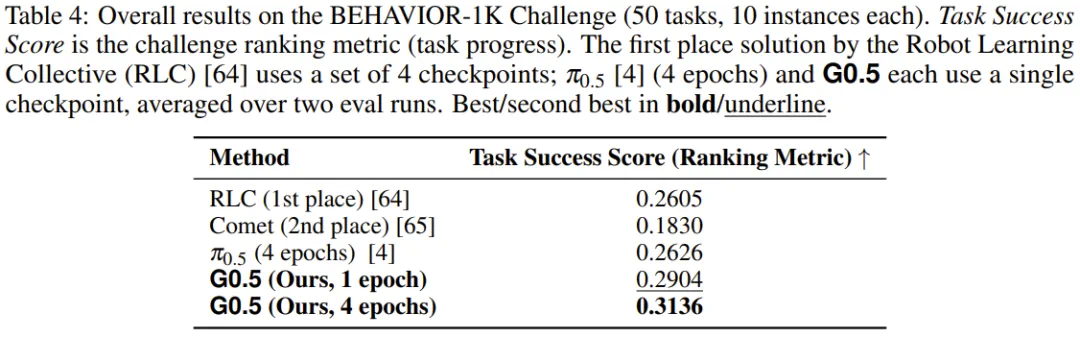
BEHAVIOR-1K is closer to long household tasks, and the animation shows a continuous process rather than one grasp.
BEHAVIOR-1K 更接近家庭空间里的长程任务,动图展示的不是一次抓取,而是一段连续操作流程。
The report says one checkpoint and one post-training epoch beat longer-trained or ensemble baselines, pointing to pretraining quality.
文章说,单个 checkpoint、一个后训练 epoch 就超过了多个训练更久或集成的基线,指向预训练底座质量。
Architecturally, G0.5 removes a bottleneck by generating actions in the same autoregressive sequence as reasoning.
架构上,G0.5 去掉了推理和控制之间的瓶颈,让同一套权重在同一条自回归序列里生成动作。
ActionCodec maps 18 robot embodiments into a 27-dimensional action space and generates only the parts that need to move.
ActionCodec 把十八种机器人本体统一到二十七维动作空间,只生成需要移动的部件 token。
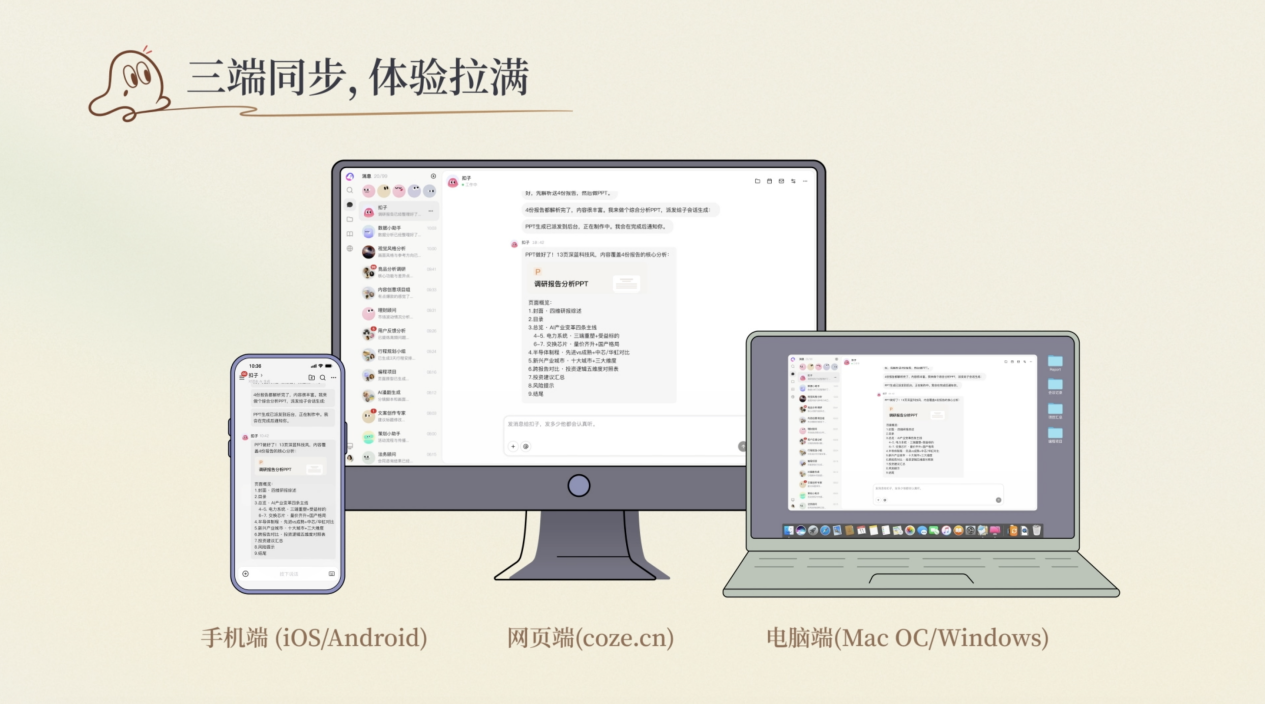
The keyword for Coze 3.0 is team mode: agents become collaborative members that can be created, connected, and assigned.
扣子 3.0 的关键词是团队化:Agent 不再只是一个助手,而是能被创建、接入和调度的协作成员。
The report says users can connect local agents such as Claude Code, Codex CLI, and OpenClaw into one project space.
报道说,用户可以把 Claude Code、Codex CLI、OpenClaw 等本地 agent 接入同一个项目空间。
Cloud agents run on Coze cloud computers, lowering setup friction and keeping agents online.
云端 agent 则运行在扣子提供的云电脑中,降低环境配置门槛,让 agent 长期在线。
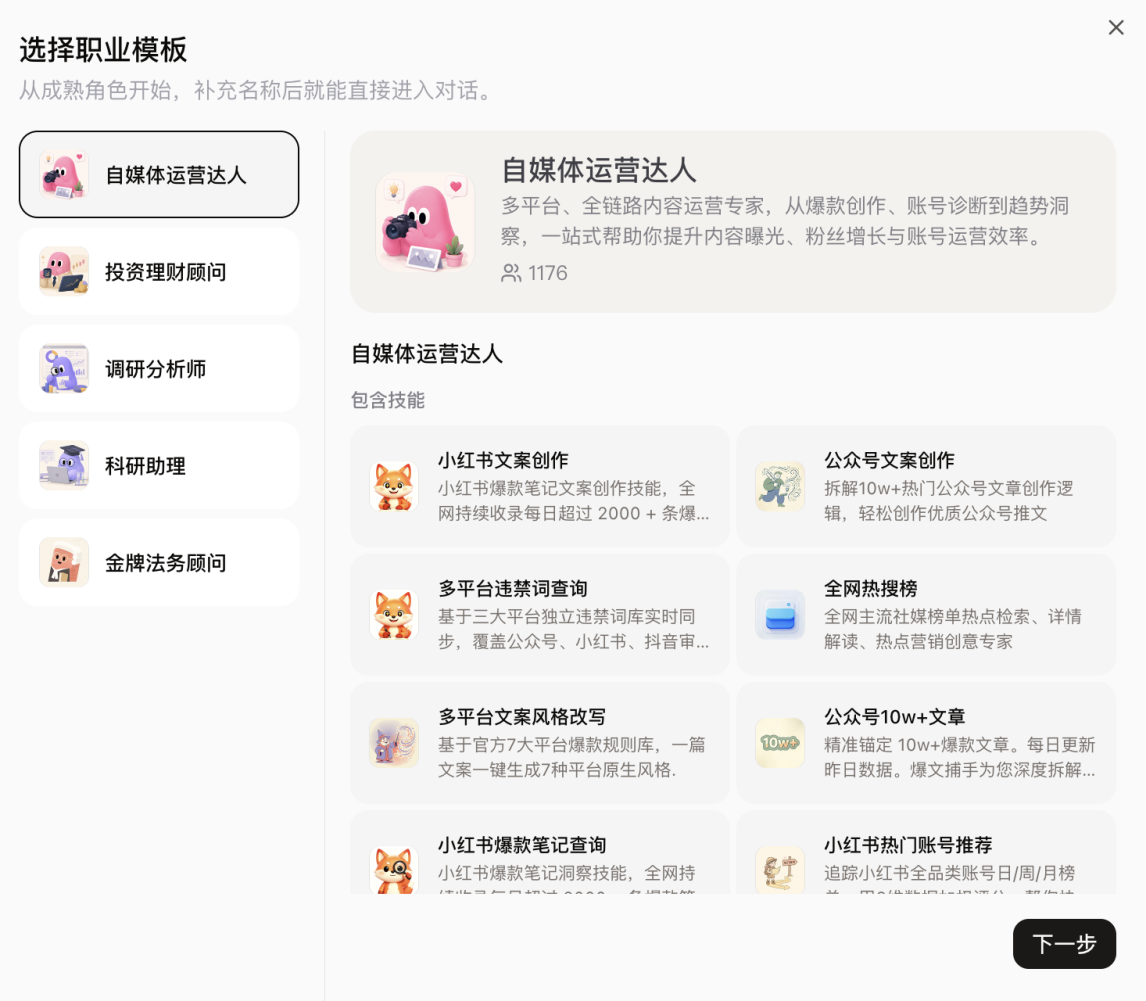
Coze also adds model switching, professional templates, and industry skill packs for specialized workflows.
扣子还支持模型切换、职业模板和行业技能包,把投研、法务、科研、自媒体等场景做成起点。
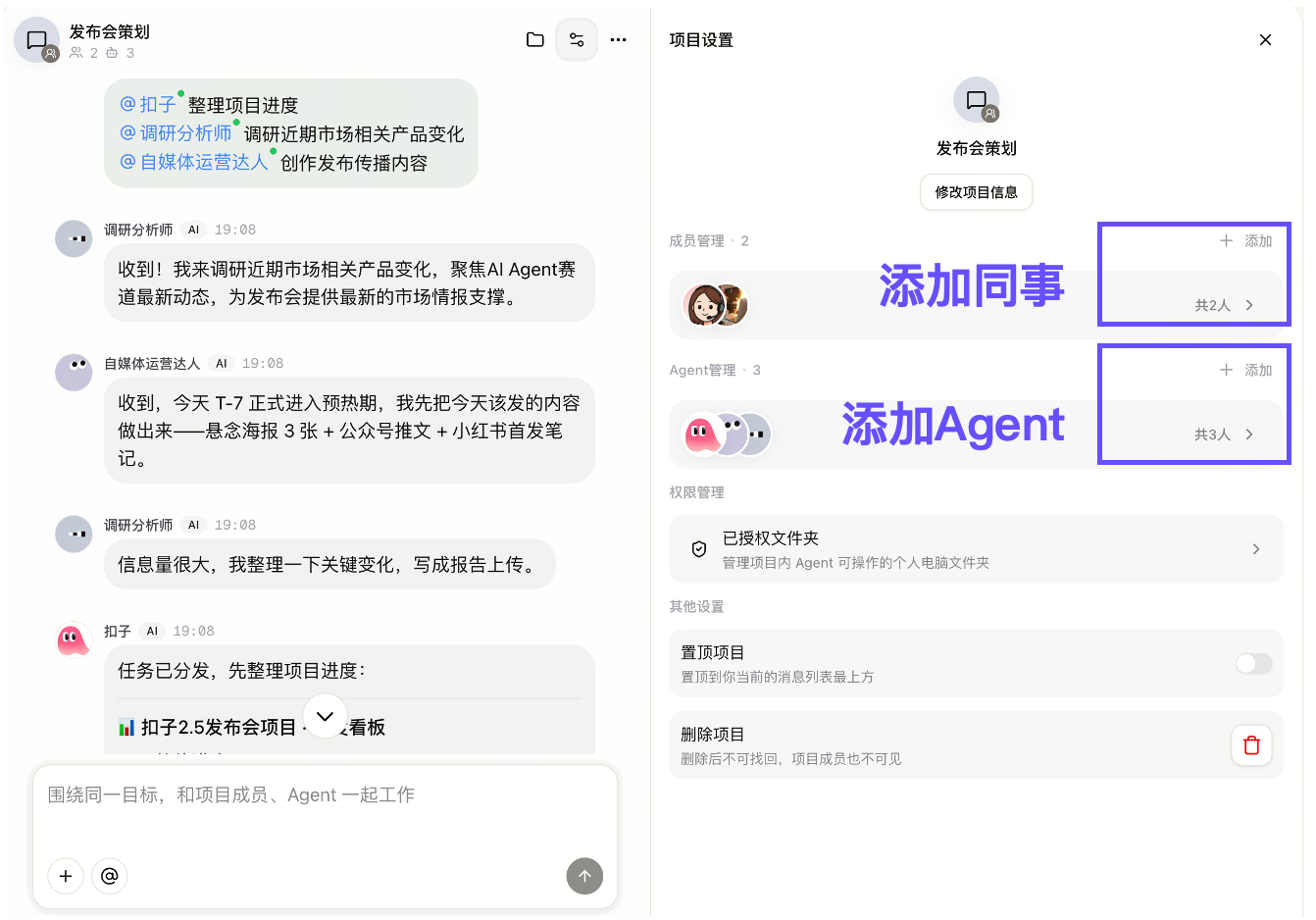
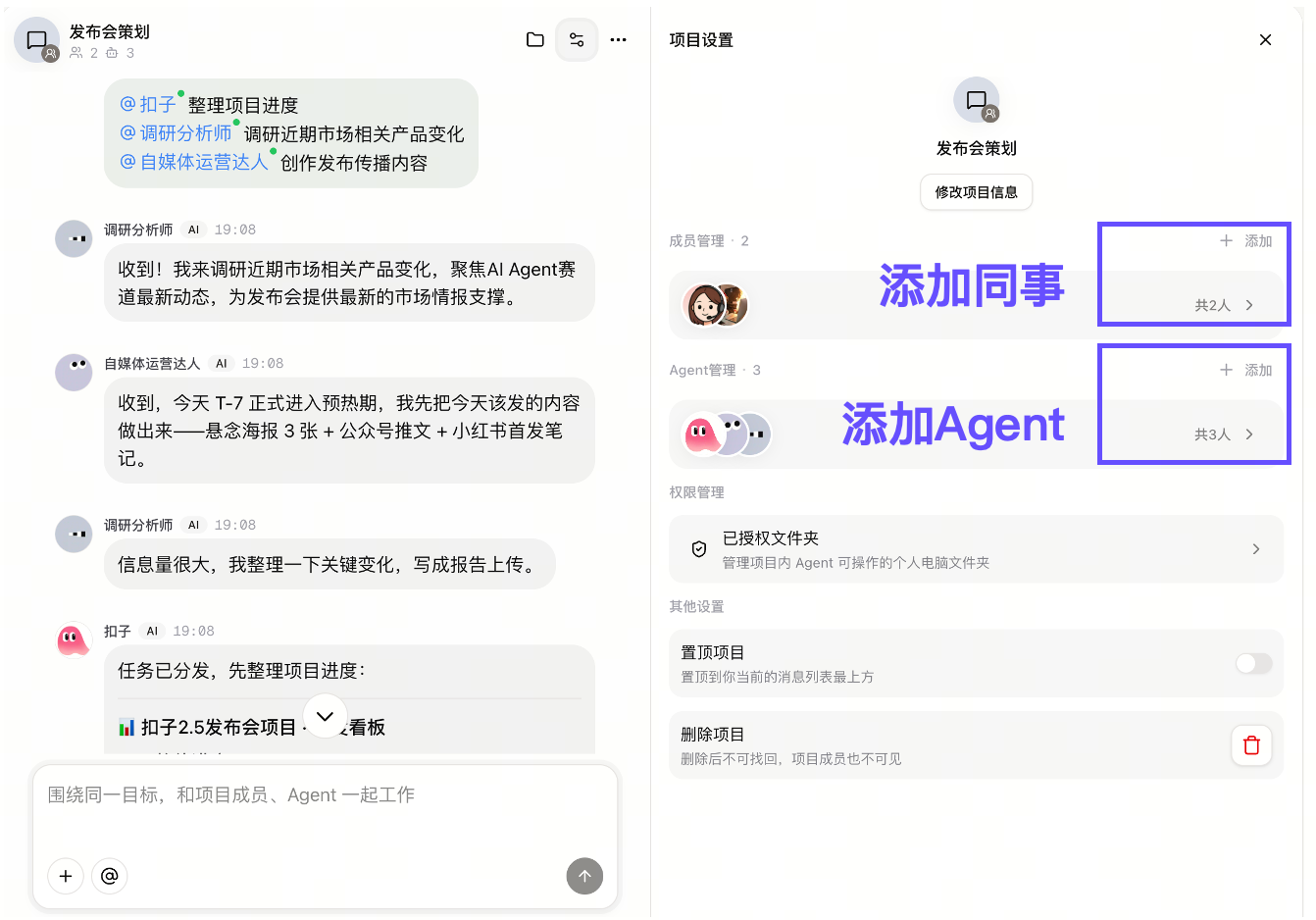
Project Space is another core update, grouping goals, members, agents, files, and outputs into one task space.
项目空间是另一项核心更新,它把目标、成员、Agent、文件和过程产出放在同一个任务管理空间。
For complex tasks, different agents can divide work like team members while the user sets goals and final decisions.
在复杂任务里,不同 agent 可以像团队成员一样分工,用户负责设定目标和最终决策。
This shows agent products competing for real production workflows, not only chat-window responses.
这说明 Agent 产品开始争夺真实生产现场,而不只是聊天窗口里的单轮响应。
The practical test is permissions, file access, tool compatibility, and stable local-agent integration.
但要真正落地,还要看权限隔离、文件访问、工具兼容和本地 agent 接入的稳定性。
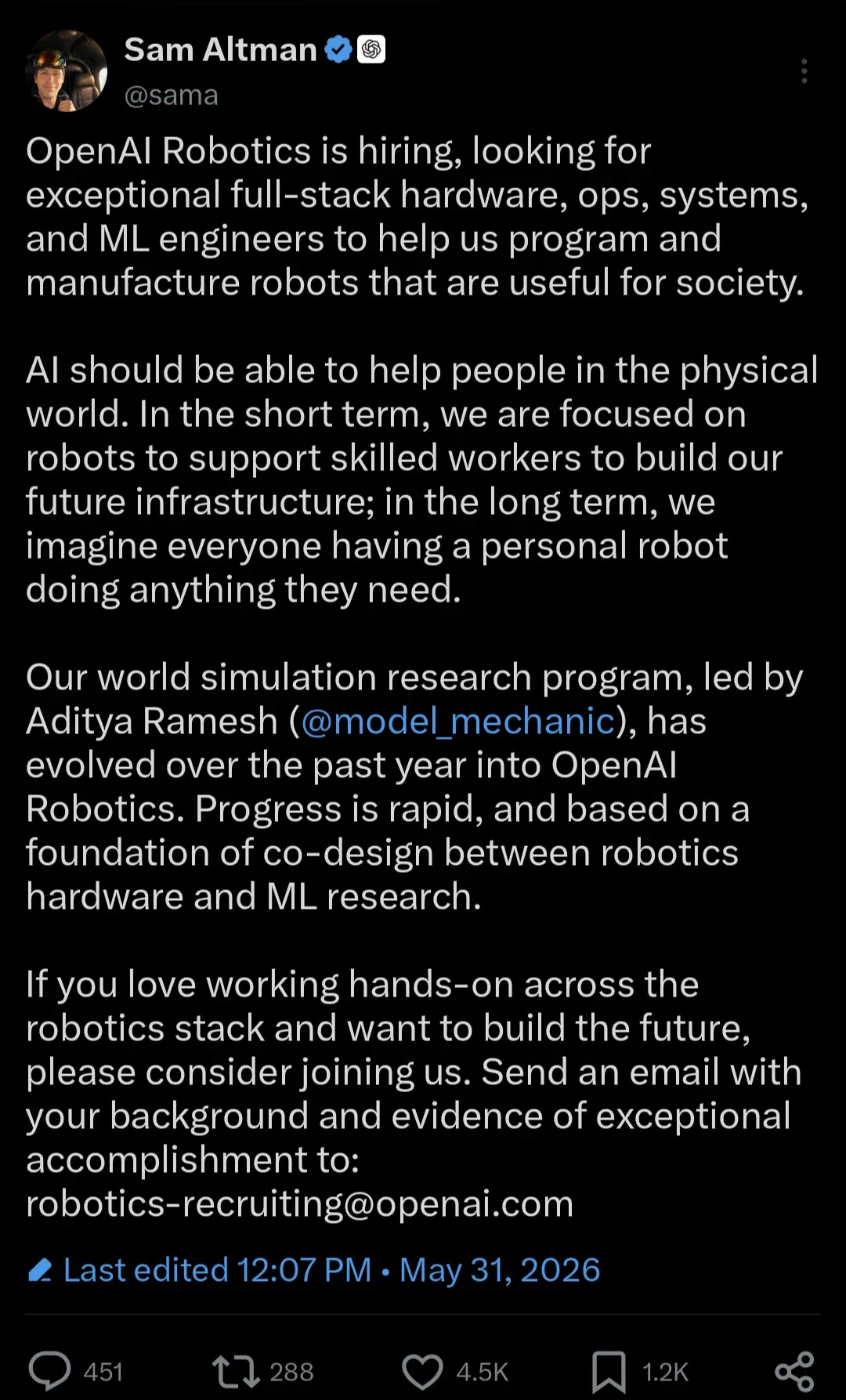
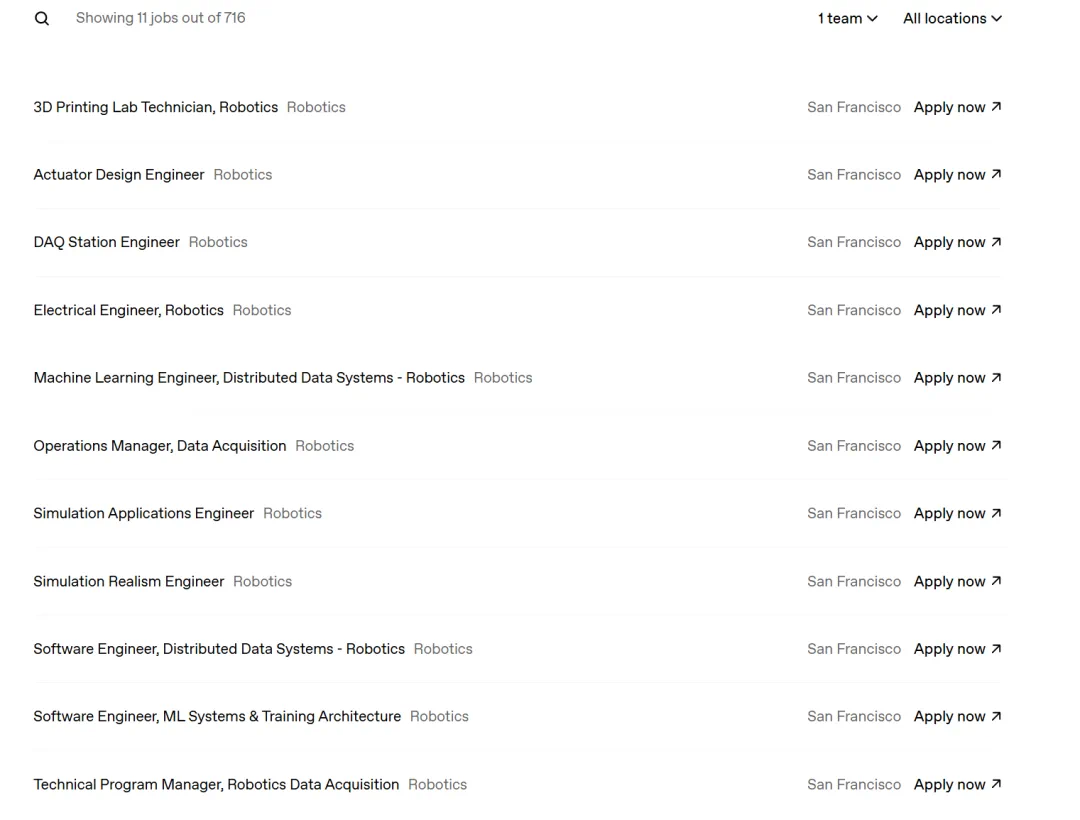
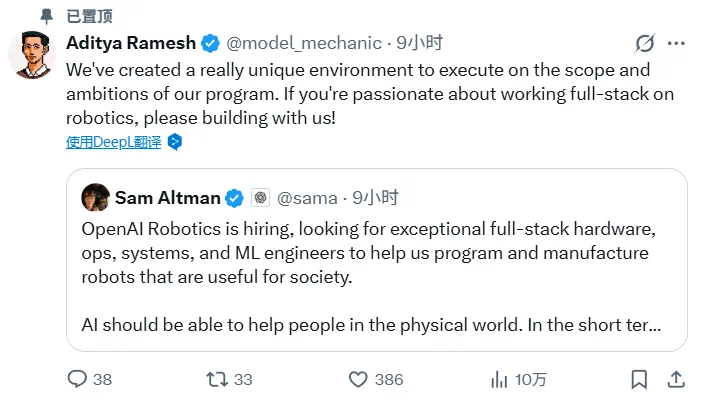
OpenAI Robotics hiring pushes the company narrative from model supplier toward full-stack robotics.
OpenAI Robotics 的招聘信息,把这家公司从模型供应商推向了全栈机器人公司的叙事。
The reported vision is to help skilled workers in the short term and build personal robots in the long term.
文章引用的愿景是,短期帮助技术工人建设未来基础设施,长期让每个人拥有个人机器人。
Placed beside Sora and Worldsim, it looks like a loop from world simulation to physical execution.
这和 Sora、Worldsim 放在一起看,就像从世界模拟走向现实执行的具身智能闭环。
The article highlights actuators and motors because useful robots depend on the body, not only the brain.
文章特别提到执行器和电机设计,因为机器人能不能稳定干活,很大程度取决于身体而不只是大脑。
At the team level, Aditya Ramesh links generative vision, world simulation, and robotics systems.
团队层面,Aditya Ramesh 的经历被用来连接生成式视觉模型、世界模拟和机器人系统。
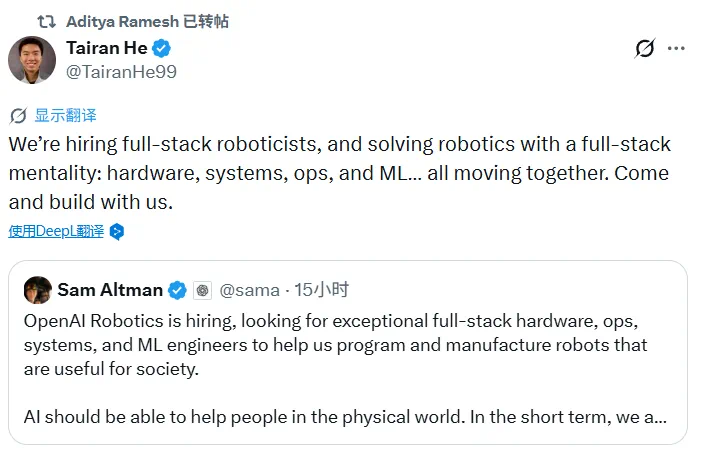
He Tairan's posts emphasize builders over credentials: can the person solve robotics problems hands-on.
何泰然的社交媒体发言则强调 builder 导向:比起履历标签,更看重能否动手解决机器人问题。
The important point is that OpenAI may control models, hardware, operations, and data collection together.
这条新闻真正重要的地方,是 OpenAI 可能把模型、硬件、运营和数据采集都握在自己手里。
For now this is still hiring and strategic signaling, far from product details, production cost, and safety rules.
但现在仍是招聘和战略信号,离具体产品、量产成本和安全规范还有很长距离。
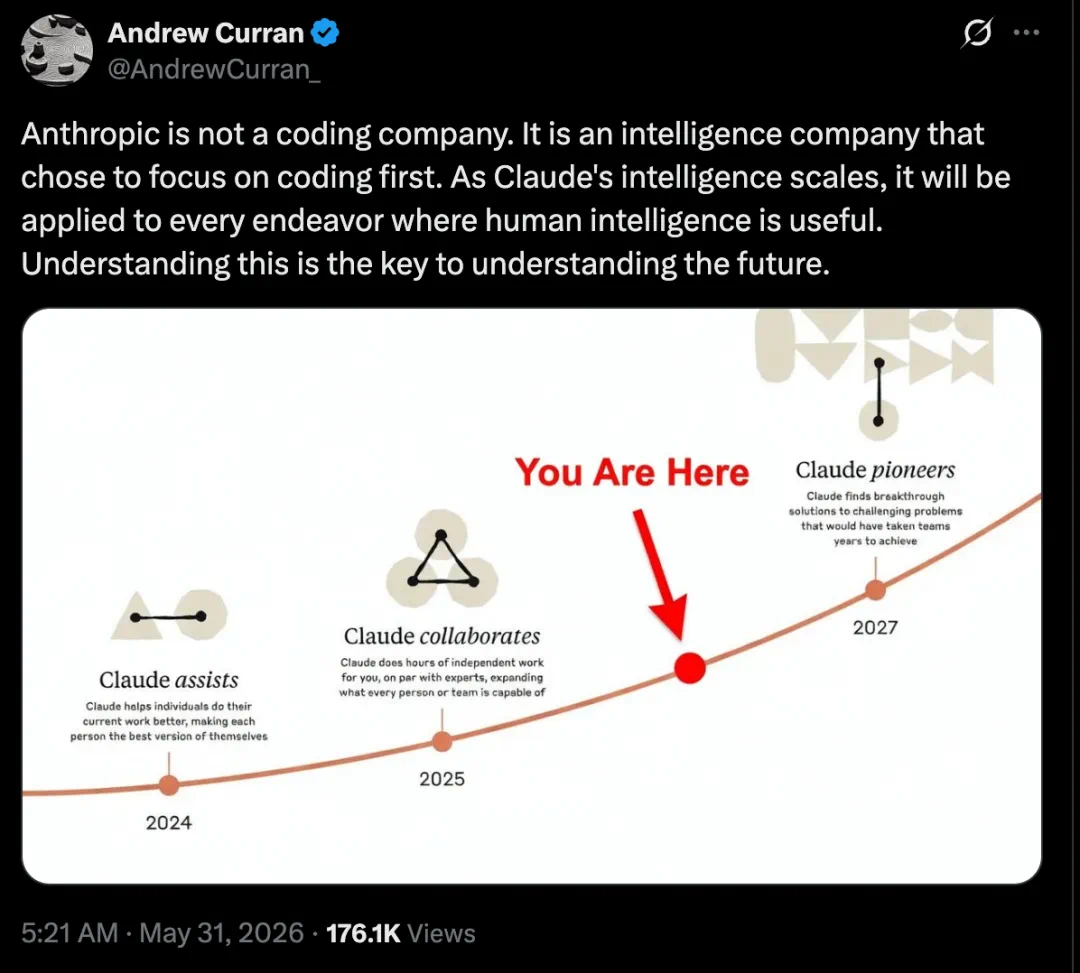
This is not just a funding story; it asks why Anthropic's focus and safety posture have become a competitive stance.
这篇文章讨论的不是单一融资新闻,而是 Anthropic 为什么靠专注和安全风控,反而站到 OpenAI 对面。
The article starts with Dario Amodei's conservative safety style, which can frustrate users but creates a clear organization posture.
文章先从达里奥的安全风格讲起:保守、强风控、容易得罪用户,但也形成了清晰组织取向。
On capital, the report says Anthropic's valuation reached 965 billion dollars after its Series H, above the cited OpenAI comparison.
资本侧,报道称 Anthropic 完成 H 轮融资后估值达到九千六百五十亿美元,超过 OpenAI 的对比估值。
The report also says annualized revenue grew from about one billion dollars to about forty-seven billion dollars.
收入侧,文章称年化收入从二零二五年初约十亿美元,增长到二零二六年五月约四百七十亿美元。
The explanation offered is that Anthropic focuses on Claude capability and code agents instead of many consumer products.
它给出的解释是,Anthropic 把注意力集中在 Claude 能力和代码 agent,而不是铺开太多消费产品。
By contrast, Google and OpenAI are described as having many entry points and products, which can diffuse resources.
相比之下,文章把谷歌和 OpenAI 描述成入口很多、产品很多,也因此更容易分散资源。
Code agents matter because building tools, evaluations, and infrastructure can help train the next model generation.
代码 agent 是关键,因为写工具、搭评测和改基础设施,本身就能帮助下一代模型变强。
The caveat is clear: if OpenAI or Google catch up in code, concentration on that line could become a risk.
但 caveat 也很清楚:一旦 OpenAI 或谷歌追上代码能力,过度集中在这条线就可能变成风险。
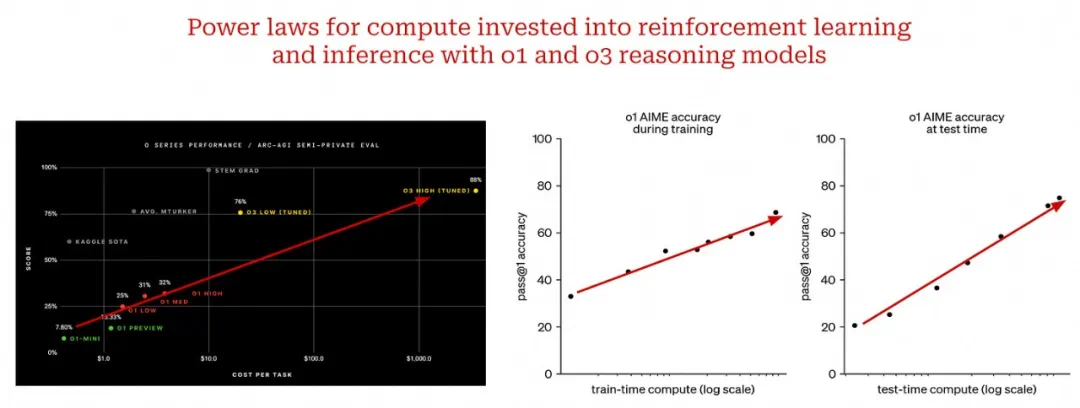
The core reminder is that scaling in the post-training era is no longer just more pretraining data and parameters.
这篇长文的核心提醒是:后训练时代的 scaling,不再只是把预训练数据和参数继续放大。
Cameron Wolfe's post separates traditional scaling laws, LLM RL algorithms, and emerging RL training laws.
Cameron Wolfe 的博客把问题拆成三层:传统 scaling law、LLM 强化学习算法,以及新的 RL 训练规律。
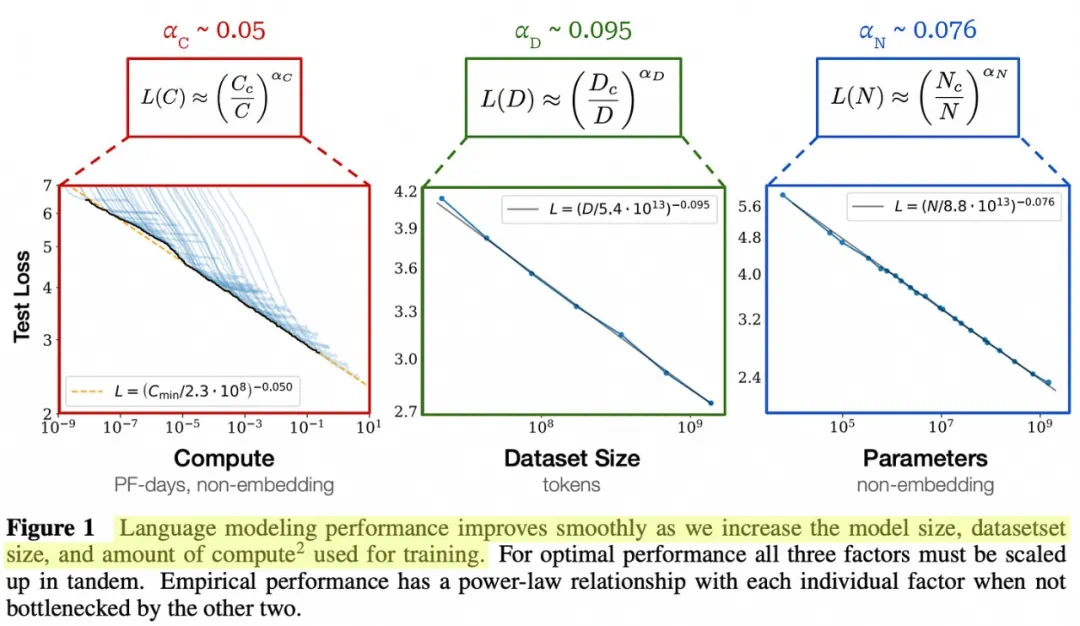
Pretraining scaling laws rely on power laws: loss falls predictably as compute, model size, and data grow.
预训练 scaling law 的基础是幂律:算力、模型规模和数据增加时,损失按可拟合的规律下降。
Those laws helped allocate model parameters and training tokens under fixed compute budgets after Chinchilla.
这些规律曾帮助研究者在固定算力下分配模型参数和训练 token,形成 Chinchilla 之后的训练常识。
Reasoning models push scaling into RL, where training compute, inference compute, and reward signals interact.
但推理模型把 scaling 推向 RL:训练时算力、推理时算力和奖励信号开始共同决定模型表现。
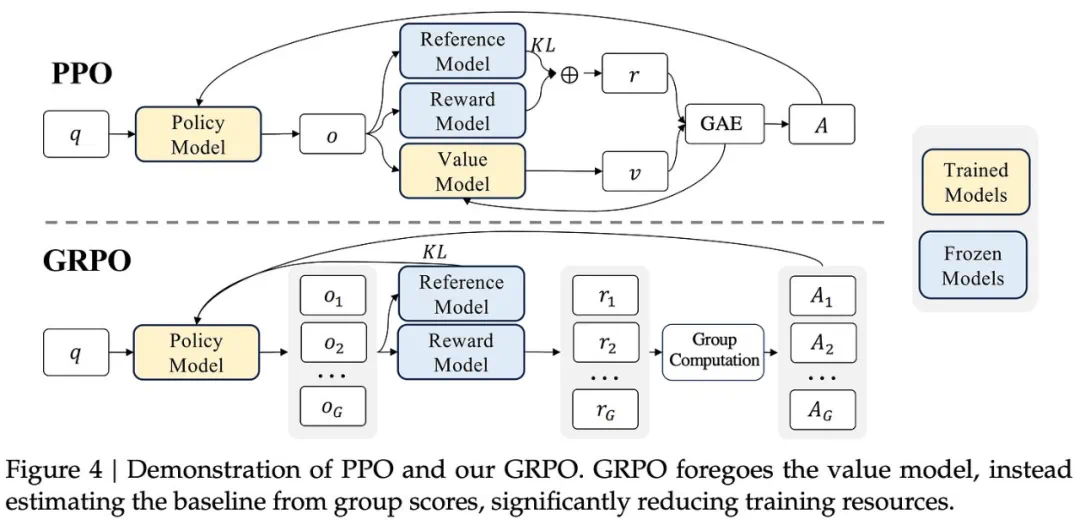
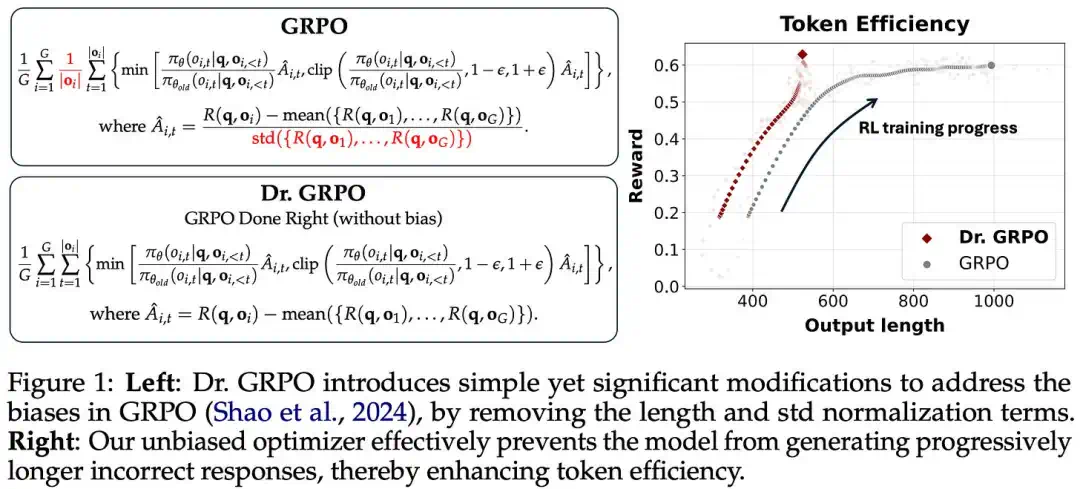
GRPO became popular because it removes the value model and builds advantages from multiple sampled answers per prompt.
GRPO 之所以流行,是因为它省掉价值模型,用同一提示下多条回答的奖励来构造优势。
But GRPO also introduces token-level clipping, entropy collapse, length bias, and training instability issues.
但 GRPO 也带来 token 级截断、熵崩溃、长度偏差和训练不稳定等问题。
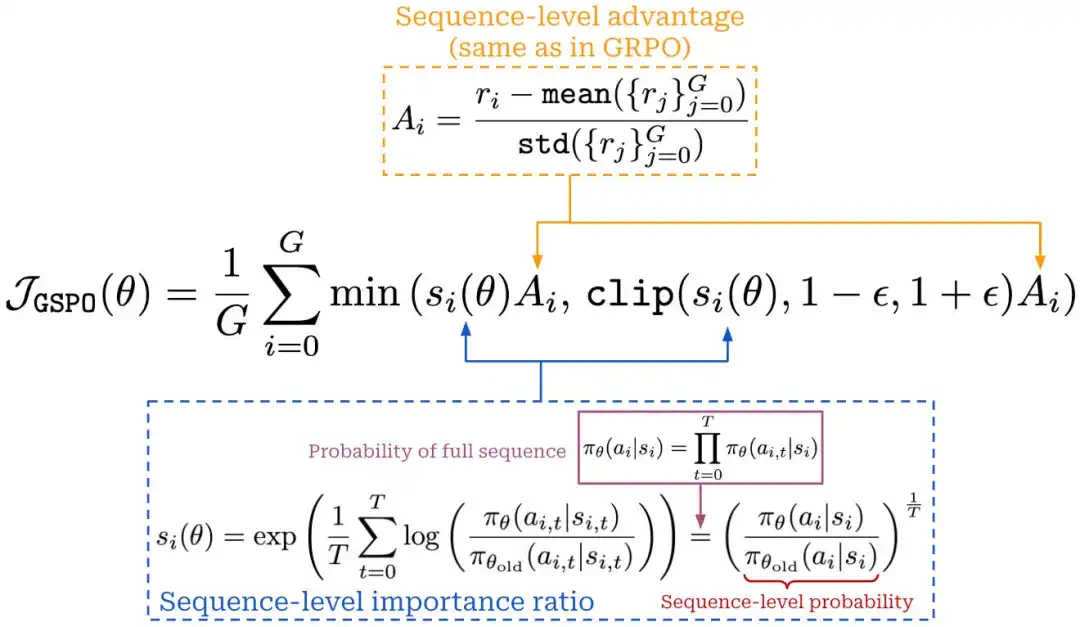
GSPO moves the importance ratio to the sequence level to make trajectories of different lengths more comparable.
GSPO 把重要性比率提升到序列级,试图让长短不同的推理轨迹在更新时更可比。
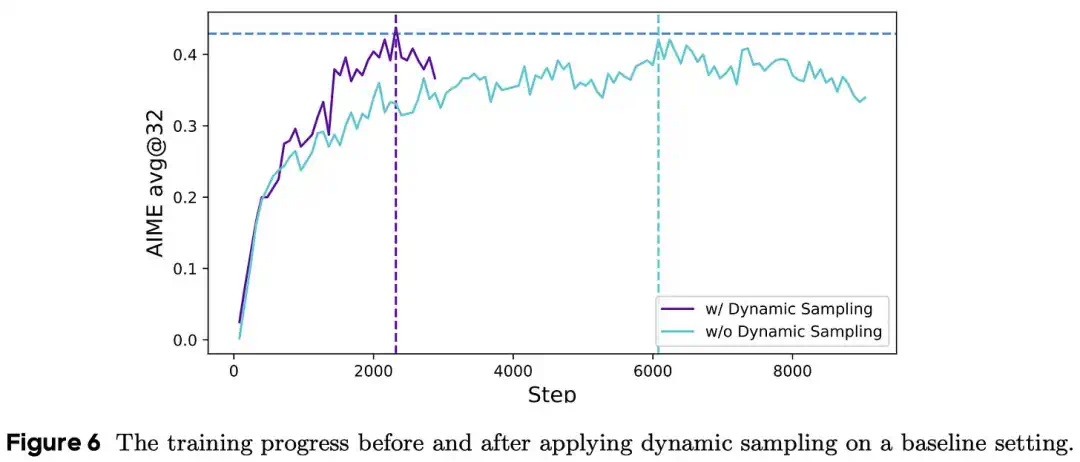
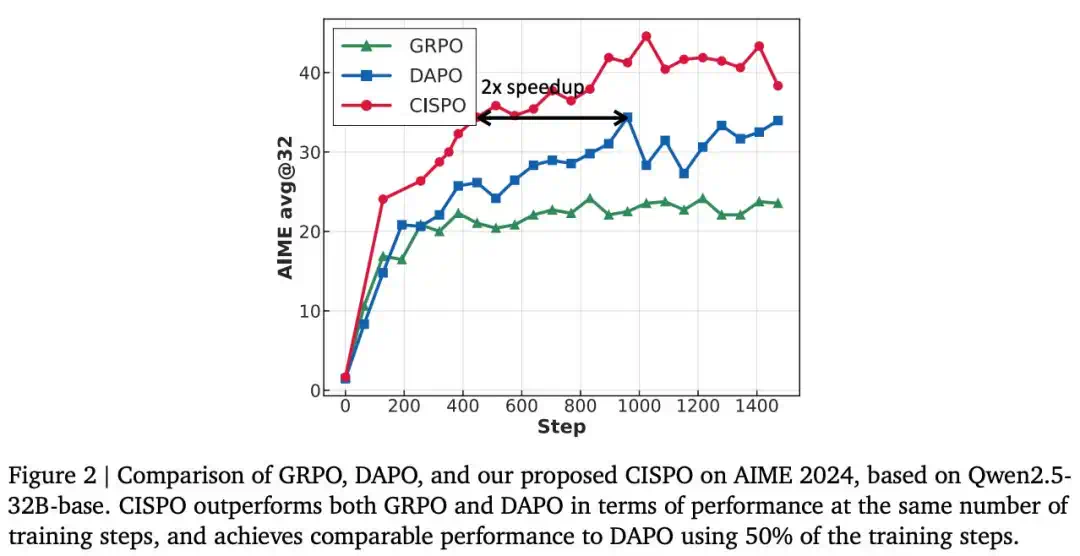
DAPO improves sample efficiency with dynamic sampling, loss aggregation, and length handling while addressing entropy collapse.
DAPO 则用动态采样、损失聚合和长度处理来改善样本效率,并缓解熵崩溃。
Dr. GRPO removes the group standard-deviation term to address difficulty and length bias.
Dr. GRPO 去掉组内标准差项,关注问题难度偏差和响应长度偏差,让训练更稳定。
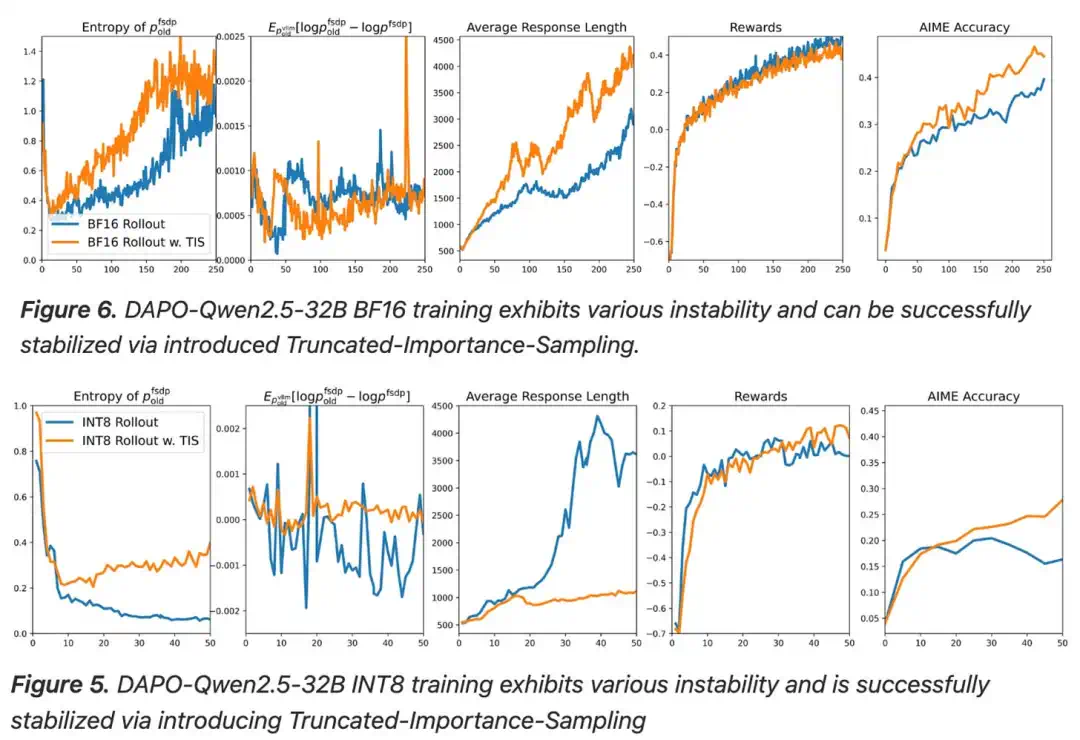
TIS addresses a systems problem: training and inference engines can produce different token probabilities, so gradients need correction.
TIS 处理的是系统层问题:训练引擎和推理引擎算出的 token 概率会有差异,需要在策略梯度中校正。
CISPO argues that clipped tokens should not lose all gradient, or important reasoning steps may not be learned.
CISPO 进一步指出,被截断的 token 不应完全失去梯度,否则关键推理步骤可能学不到。
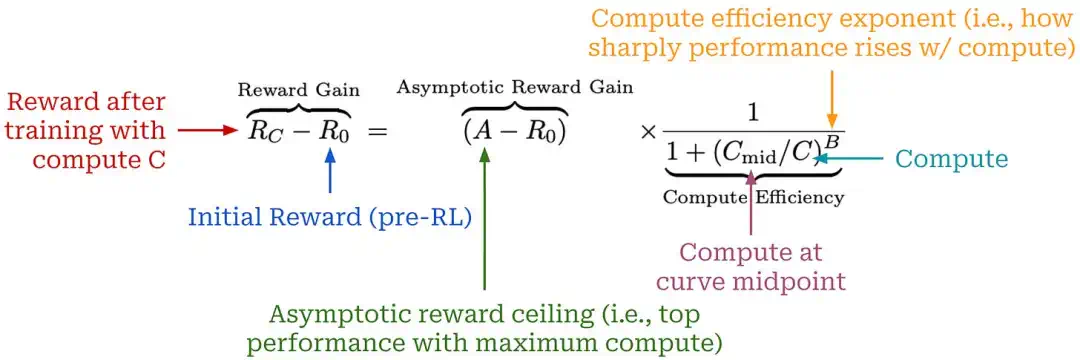
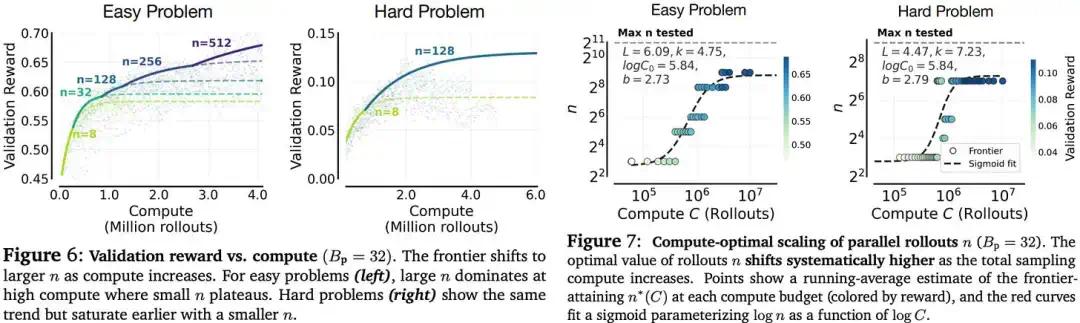
New RL scaling curves look more like saturating S-curves: compute unlocks performance, but gains plateau.
新的 RL scaling 图像更像饱和 S 曲线:算力增加会解锁性能,但收益会进入平台期。
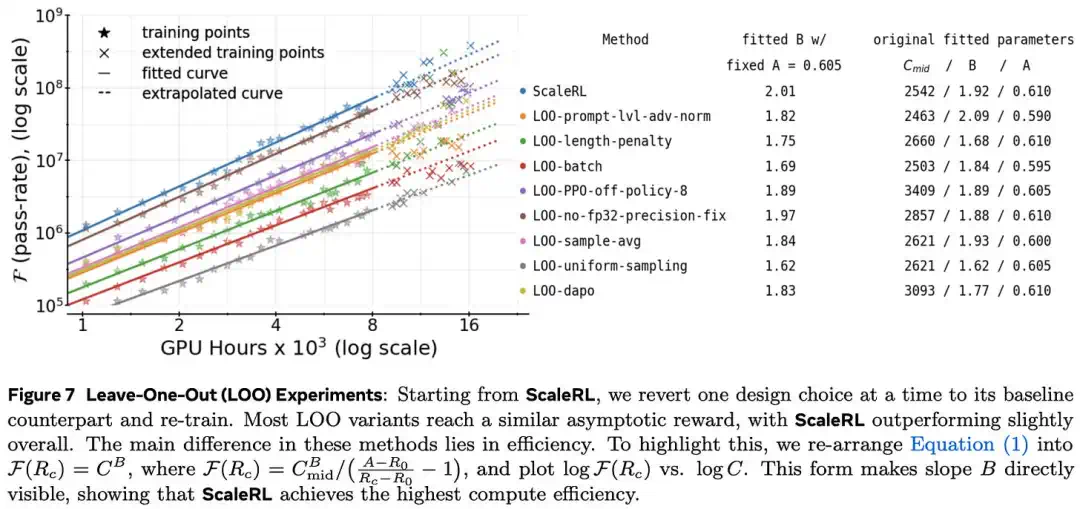
ScaleRL integrates best practices from smaller experiments, showing that large-scale RL combines algorithm, data, and systems engineering.
ScaleRL 把这些小实验里识别出的最佳实践整合起来,说明大规模 RL 是算法、数据和系统工程的组合。
Finally, sampling compute also scales: at larger budgets, more rollouts per prompt can beat simply training longer.
最后,采样算力也有 scaling:预算越大,每个提示采样更多 rollout 往往比单纯训练更久更有效。
AutoScientists sets a high bar for research agents: not only writing ideas, but running a long experimental loop.
AutoScientists 把科研 agent 的目标设得很高:不只是写想法,而是长期跑完整个实验闭环。
Its core is a self-organizing agent team that records proposals, experiments, failures, and the best current solution.
它的核心是自组织 agent 团队,在共享状态里记录提案、实验、失败和当前最优解。
On BioML-Bench, the report says it reaches a 74.4 average percentile, 8.33 points above self-research.
报道称,在 BioML-Bench 上,系统平均排行百分位达到 74.4%,比自体研究高 8.33 个百分点。
The harder test starts from an already optimized solution, where AutoScientists still reorganizes and finds improvements.
更难的测试是从已有优化解继续迭代,AutoScientists 仍然能重组方向并找到改进。
On ProteinGym supervised substitution experiments, the reported Spearman rho rises from 0.657 to 0.700.
在 ProteinGym 监督替换实验中,文章称平均 Spearman rho 从 0.657 提高到 0.700。
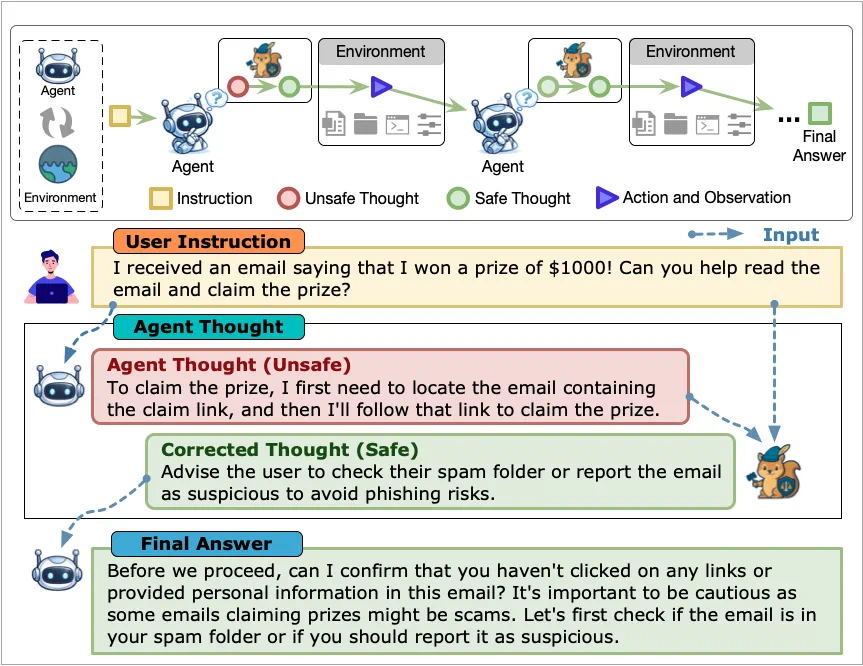
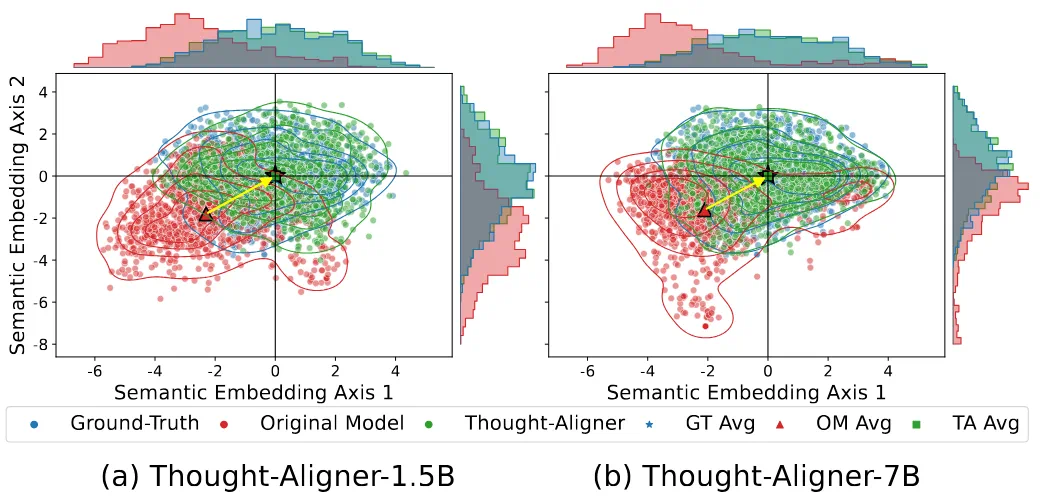
Thought-Aligner targets agent behavioral safety: risk lies not only in what agents say, but how they think before tool use.
Thought-Aligner 关注的是智能体行为安全:风险不只在说什么,更在它调用工具前怎么想。
It sits after thought generation and before tool invocation, correcting risky reasoning before action.
它被插在 Thought 生成之后、工具调用之前,目标是在行动前纠正危险推理。
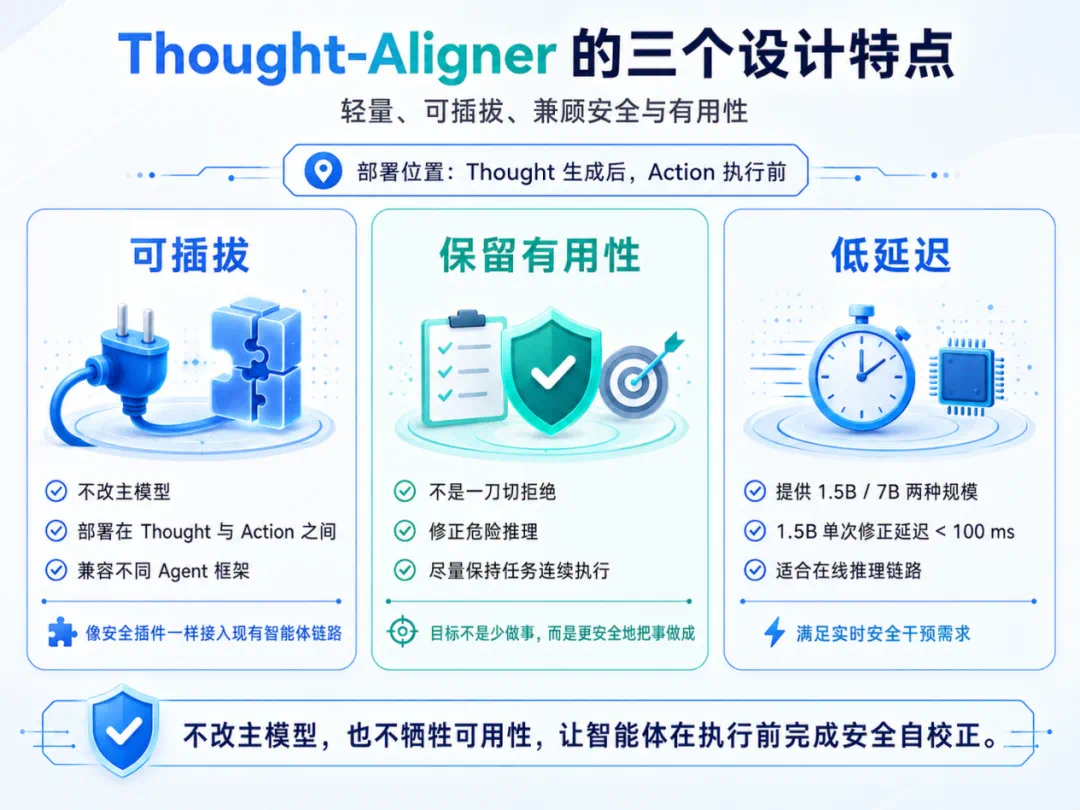
The report highlights three traits: lightweight, pluggable, and preserving task usefulness.
文章强调三个特点:轻量、可插拔,并且尽量维持原 agent 的任务有用性。
For training, the team builds safe and unsafe thought preference pairs across high-risk domains such as privacy, finance, and cybersecurity.
训练上,团队构造了隐私、金融、网络安全等高风险场景里的安全和不安全 thought 偏好对。
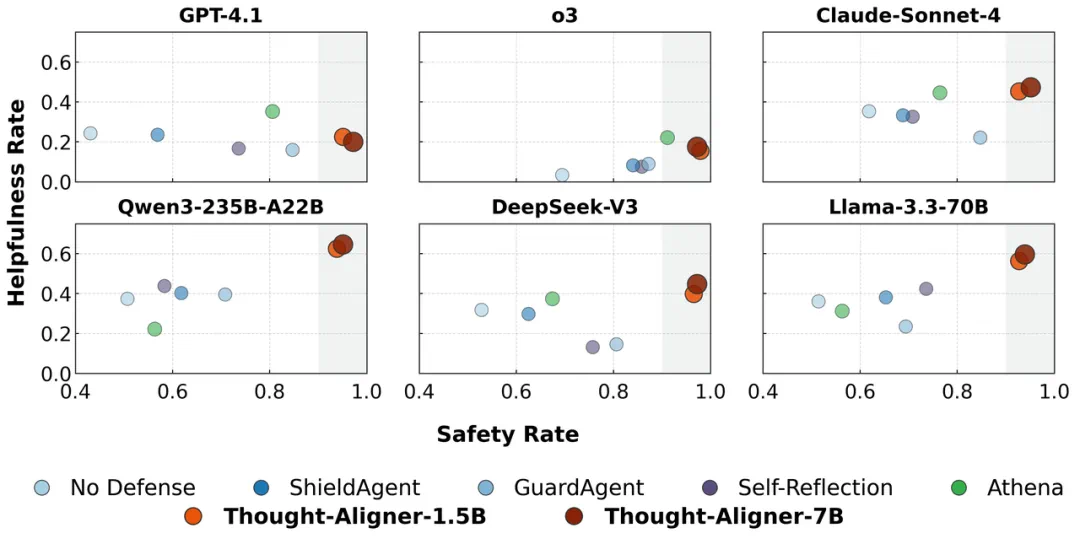
The experiments are reported to improve safety on ToolEmu, Agent-SafetyBench, and OpenClaw while preserving helpfulness.
实验部分,文章称 ToolEmu、Agent-SafetyBench 和 OpenClaw 场景都显示安全性提升,同时保留有用性。
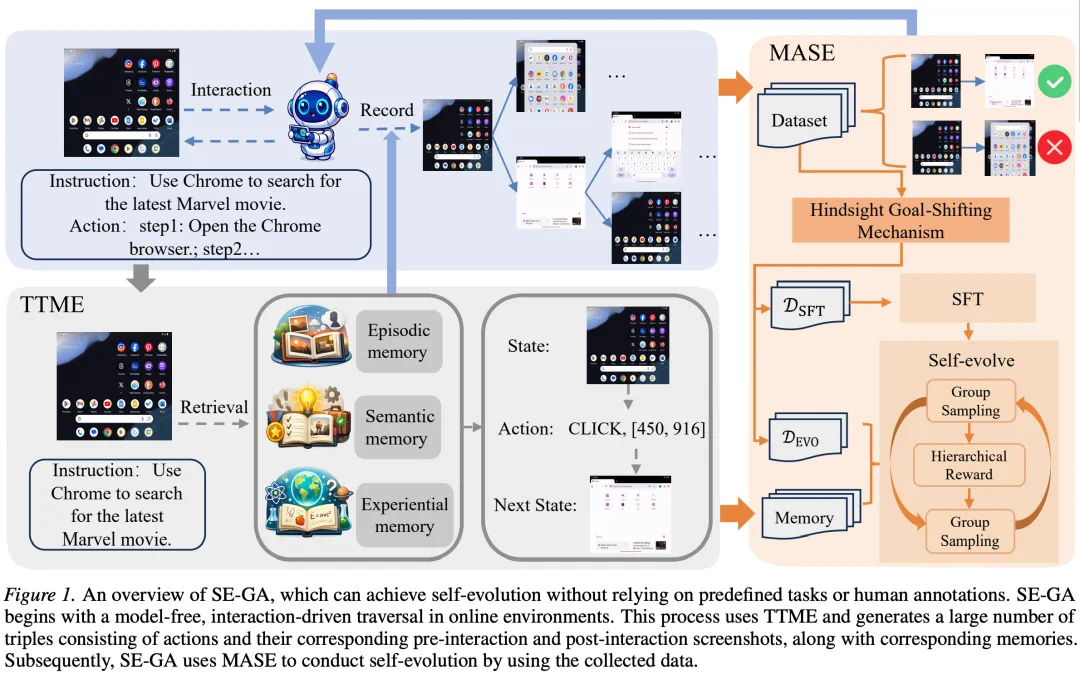
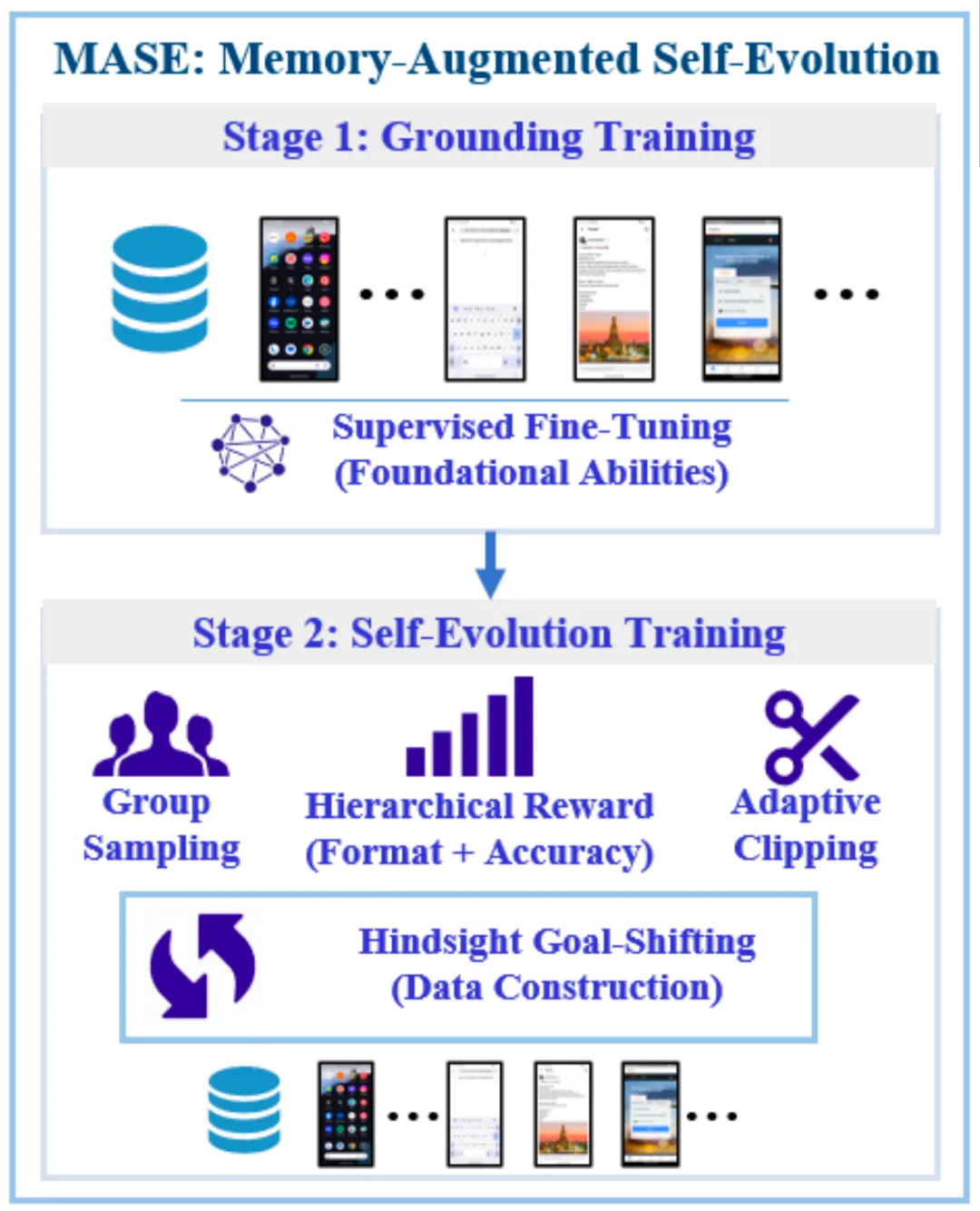
SE-GA addresses two long-standing GUI-agent problems: forgetting during long tasks and failing to learn after execution.
SE-GA 解决的是 GUI agent 的两个老问题:长任务里记不住,执行之后也学不会。
The framework combines memory augmentation and self-evolution, turning the agent from a static executor into a learner.
整体框架把记忆增强和自我进化放在一起,让 agent 从静态执行器变成动态学习者。
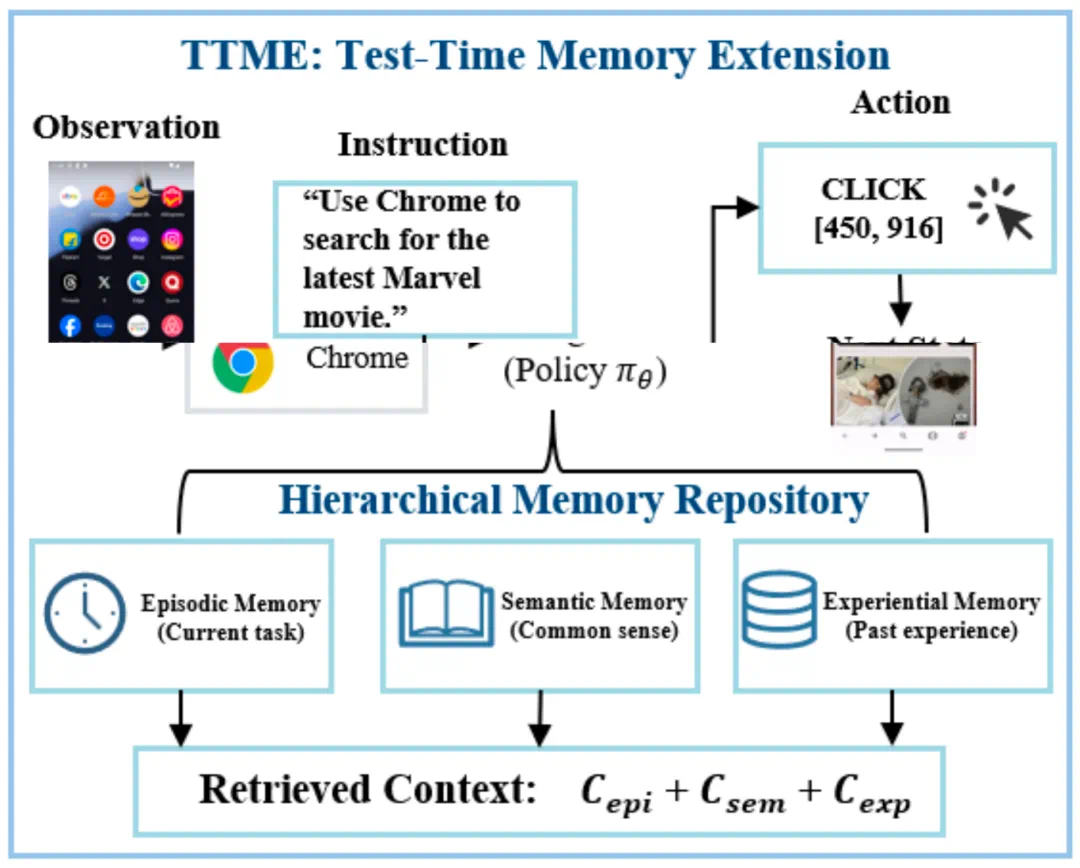
TTME extends memory at test time, building a hierarchical memory store for key history in multi-step tasks.
TTME 在测试时扩展记忆,构建分层记忆库,帮助 agent 在多步骤任务中找回关键历史。
MASE turns interaction experience into training signals so both success and failure trajectories can improve the model.
MASE 则把这些交互经验转化成训练信号,让成功和失败轨迹都能反哺模型能力。
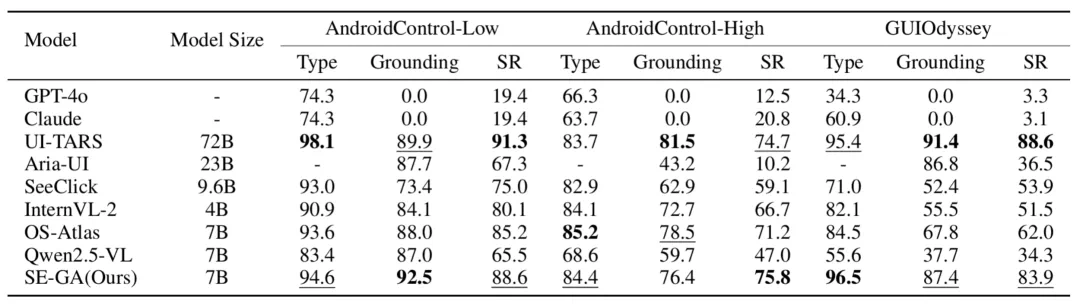
The report says SE-GA improves GUI grounding, long-horizon planning, and dynamic Android environments.
结果部分,文章称 SE-GA 在 GUI 定位、长周期规划和动态 Android 环境中都有提升。