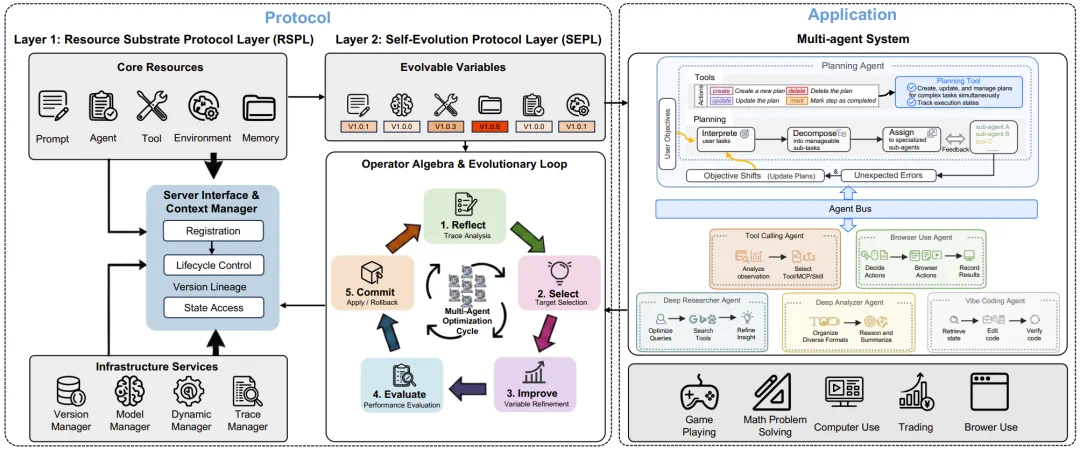
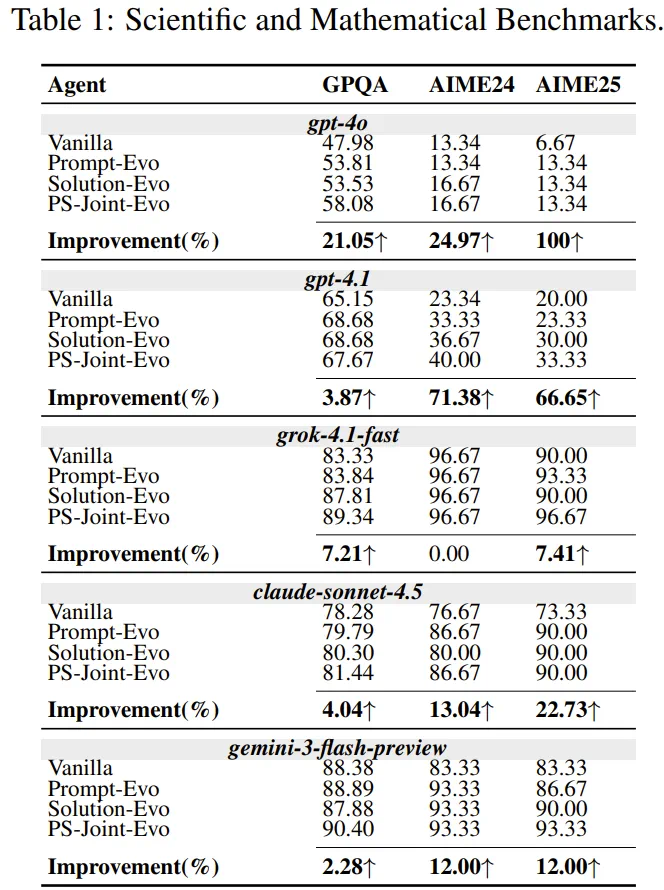
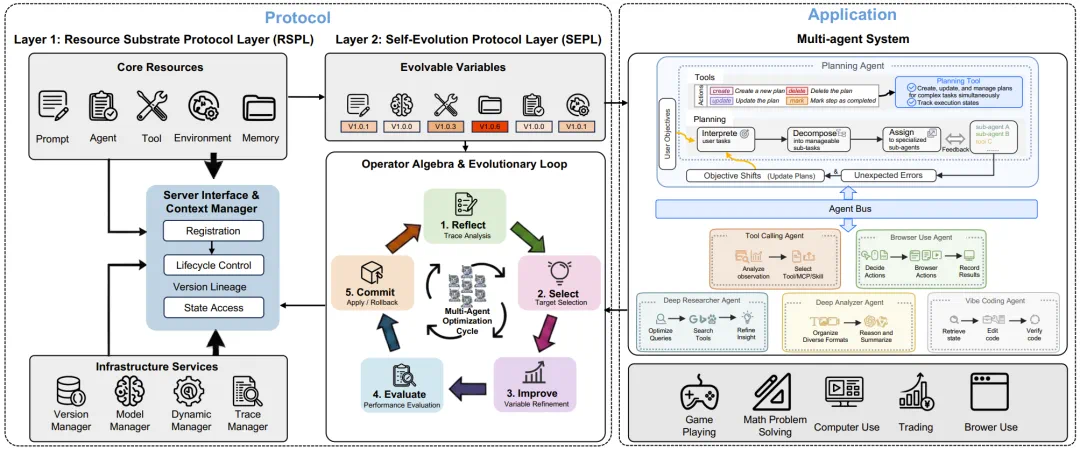
The lead agent story is Autogenesis: the article says it gives self-modifying agents a governable operating system.
今天的智能体头条是 Autogenesis:文章说,它想给会自我修改的 Agent 装上一套可治理的操作系统。
The key is not just adding tools, but making prompts, tools, memory, environments, and agents lifecycle-managed resources.
它的关键不是多接几个工具,而是让 Prompt、工具、记忆、环境和 Agent 本身都成为有生命周期的资源。
The protocol has two layers: RSPL defines what can evolve, while SEPL defines reflect, select, improve, evaluate, and commit.
协议被拆成两层:RSPL 定义什么能进化,SEPL 定义如何经过反思、选择、改进、评估和提交。
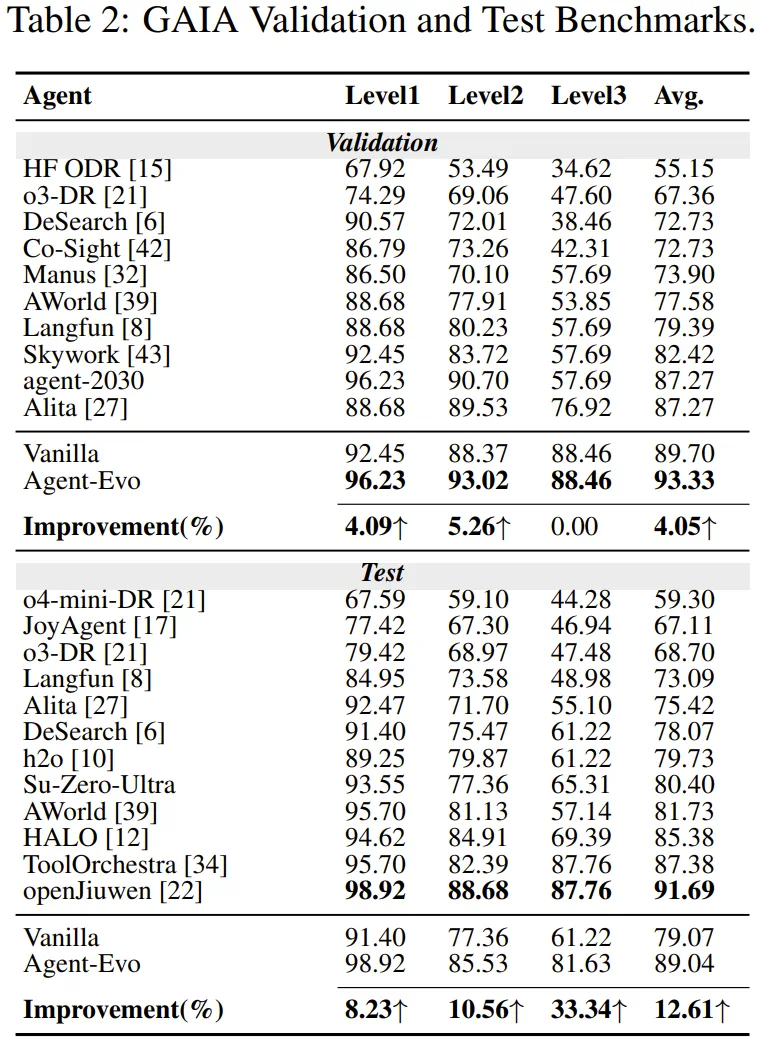
The article reports 93.33 on GAIA Validation and 89.04 on GAIA Test for AGS.
文章报告,AGS 在 GAIA Validation 达到九十三点三三,在 Test 达到八十九点零四。
The hardest Level 3 split rises from 61.22 to 81.63, so the gain concentrates on complex tasks.
最难的 Level 3 从六十一点二二提升到八十一点六三,说明提升集中在复杂任务上。
On the full HLE test, the article says AGS reaches 59.6, extending the evidence to a broader task set.
在 HLE 全量测试里,文章称 AGS 达到五十九点六;这是把自进化机制放到更宽任务面上观察。
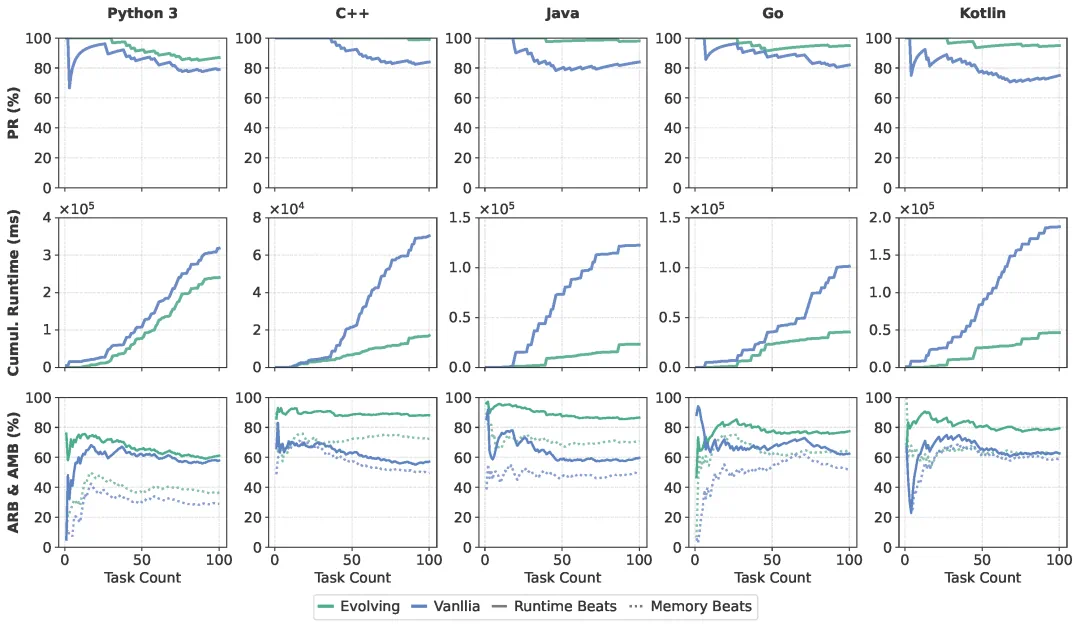
The coding side is tested separately: LeetCode covers five languages, with C++ near full marks.
代码侧也被单独测了:LeetCode 覆盖五种语言,C++ 接近满分。
So the real point is that once agents change themselves, systems must record, evaluate, and roll back those changes.
所以这篇文章真正强调的,是当 Agent 开始改变自己,系统必须先能记录、评估和回滚这些变化。
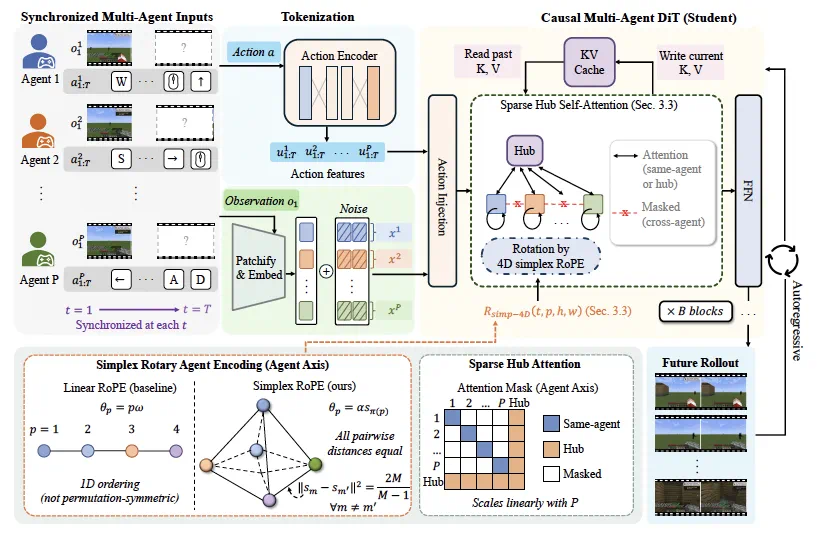
Gamma-World is about world models moving from single-player generation to shared multi-agent worlds.
Gamma-World 这篇文章讲的是:世界模型正在从单机时代,走向多智能体共享世界。
The issue is not just generating more video, but keeping world state consistent when multiple agents affect each other.
它要解决的不是再生成一段视频,而是多个主体互相影响时,世界状态如何保持一致。
The article says prior systems often use fixed player slots: two players work, but adding players breaks symmetry.
文章说,已有方案常把玩家写成固定槽位,两个玩家能跑,但增加玩家就破坏对称性。
Gamma-World uses simplex positional encoding so any two players are equally spaced, with no privileged slot.
Gamma-World 用正单纯形位置编码,让任意两个玩家距离相同,谁也不是特殊的一号位。
For complexity, hub tokens collect and broadcast information, reducing quadratic interaction to linear growth.
复杂度方面,它让玩家先把信息汇入 hub token,再由枢纽广播,计算从平方增长压到线性增长。
The reported number is one eighth of the fully connected compute at eight players, with latency down from 17.6 to 4.5 ms.
文章给出的数字是,八个玩家时算力只有全连接方案的八分之一,延迟从十七点六毫秒降到四点五毫秒。
More importantly, without four-player training data, it can still generate four synchronized views at inference.
更关键的是,模型没见过四人训练数据,也能在推理时生成四路同步视角。
The article also shows robot transfer, while leaving the key question of physical and causal validity open.
文章还展示机器人迁移实验,但它也留下问题:生成交互是否经得起真实物理和因果检验。
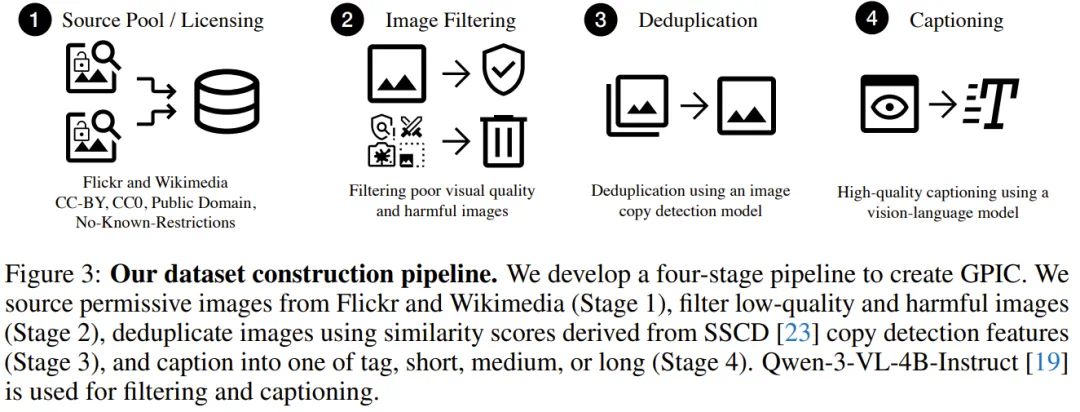
The GPIC story says visual generation needs a new open ImageNet.
GPIC 这篇文章讲的是,视觉生成需要一个新的开放 ImageNet。
The reason is that ImageNet is label-centric, while modern image models train on text prompts and massive image-text data.
原因是旧 ImageNet 面向分类标签,而今天的图像模型靠文本提示和亿级图文数据训练。
The first value is licensing: GPIC uses clearly permitted images from Flickr and Wikimedia.
GPIC 的第一层价值是授权:只收 Flickr 和 Wikimedia 中许可清晰的图片。
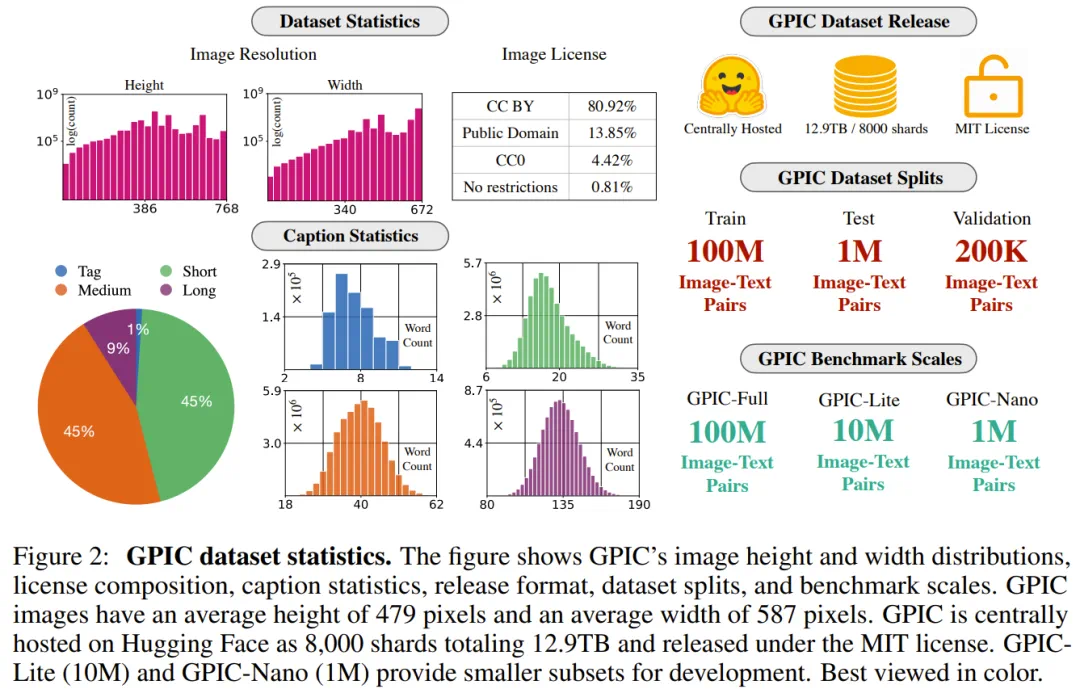
The scale is large: 100 million training images, 200 thousand validation images, one million test images, about 12.9 TB.
数据规模也很硬:一亿张训练图、二十万验证图、一百万测试图,总量约十二点九 TB。
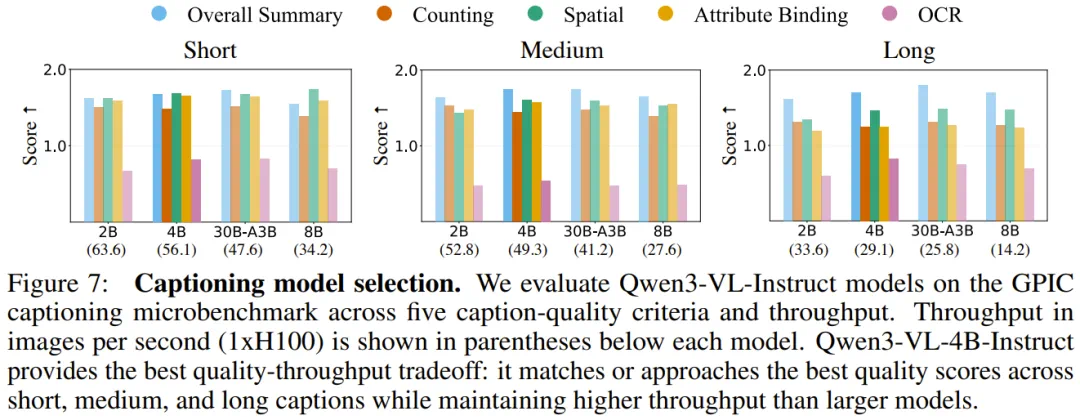
The article says Qwen3-VL regenerates four caption granularities, avoiding noisy legacy alt text.
文章还说,团队用 Qwen3-VL 重新生成四种粒度描述,避免传统 alt text 太脏。
For evaluation, GPIC uses FD-DINOv2 and an independent million-image test set to reduce memorization-driven scores.
评估上,GPIC 用 FD-DINOv2 和独立百万张测试集,避免模型靠记住训练集刷分。
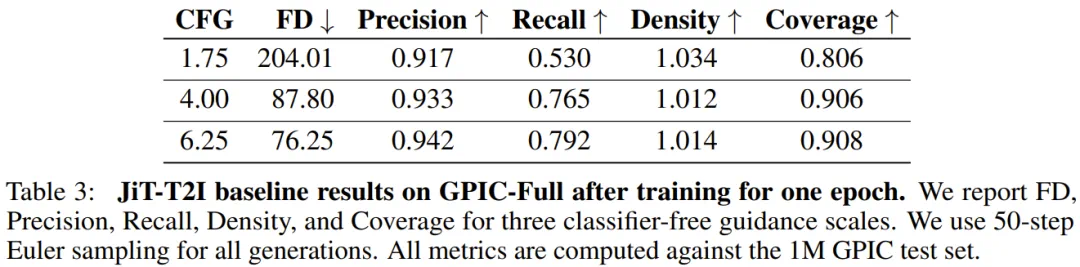
The reference baseline is a 1.1B JiT trained about 40 hours on eight H100s, with best FD-DINOv2 of 76.25.
参考基线是 1.1B 参数 JiT,在八张 H100 上训练约四十小时,最优 FD-DINOv2 是七十六点二五。
So this is less a single model release and more infrastructure for open, reproducible, comparable visual generation research.
所以这不是单个模型新闻,而是视觉生成研究能否公开、可复现、可比较的一块基础设施。
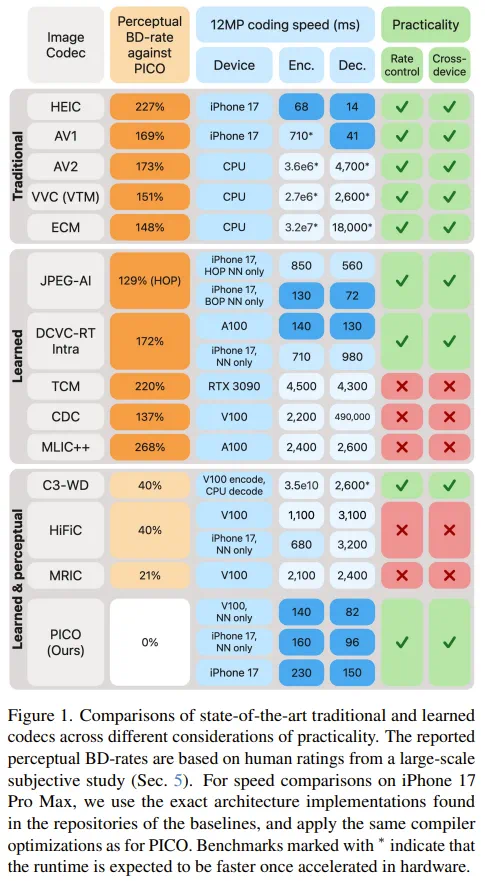
Apple PICO shifts image compression from chasing PSNR to optimizing what people actually see.
苹果 PICO 的重点是把图像压缩从追求 PSNR,转向追求人眼真的觉得好。
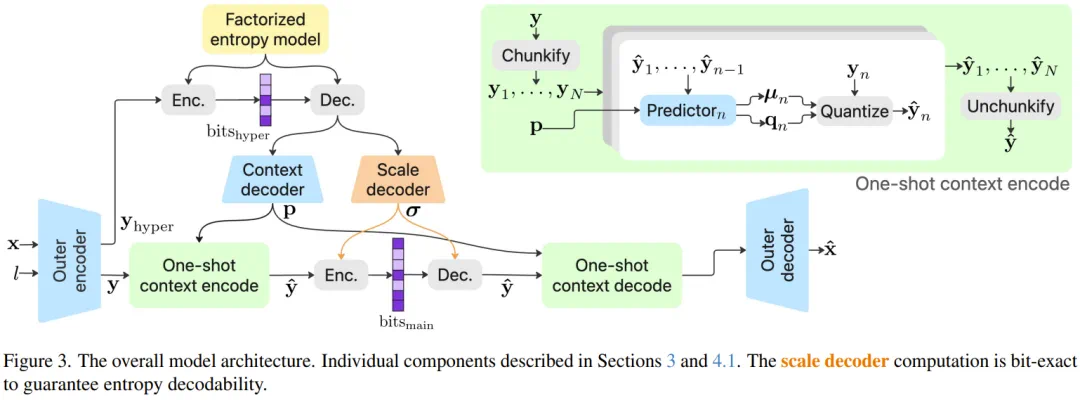
It uses a one-shot context model to reduce entropy-coding waits while preserving accuracy.
它用一次性上下文模型减少熵编码等待,既保留精度,又接近实时。
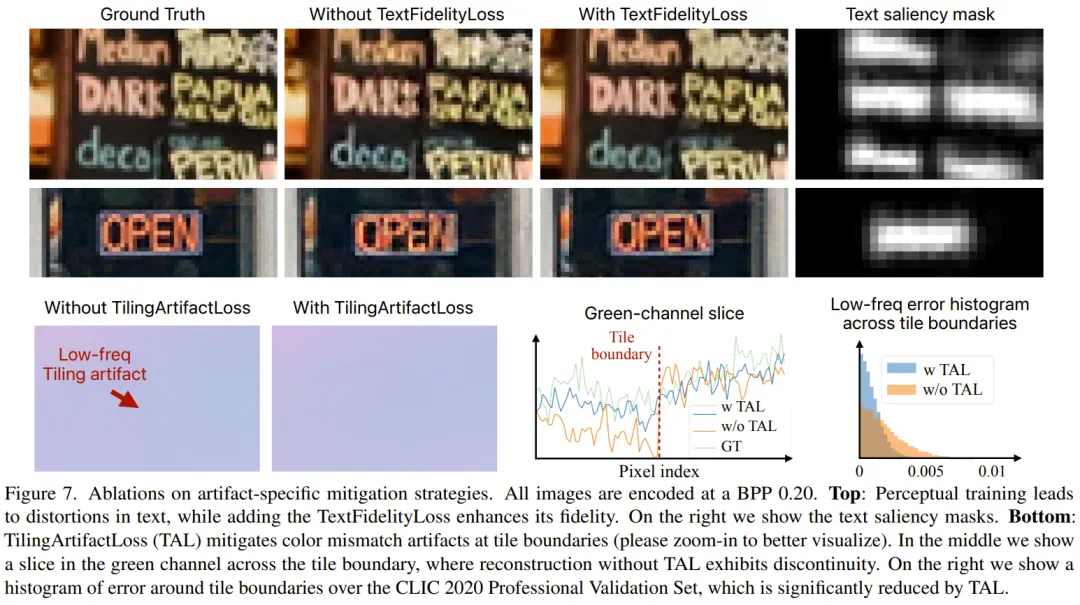
For text regions, TextFidelityLoss suppresses generative artifacts, with absolute error reportedly cut in half.
针对文字区域,TextFidelityLoss 抑制生成式压缩的幻觉,文章说绝对误差下降一半。
The main result is direct: at the same visual quality, file size is only about 30 to 43 percent of traditional standards.
实验数字更直接:同等视觉质量下,文件大小只有传统标准的大约三成到四成。
The article also notes PICO is not always best on PSNR, showing perceptual quality and pixel error are different goals.
但文章也提醒,PICO 的 PSNR 不一定最好;这说明感知质量和数学误差本来就是两套目标。
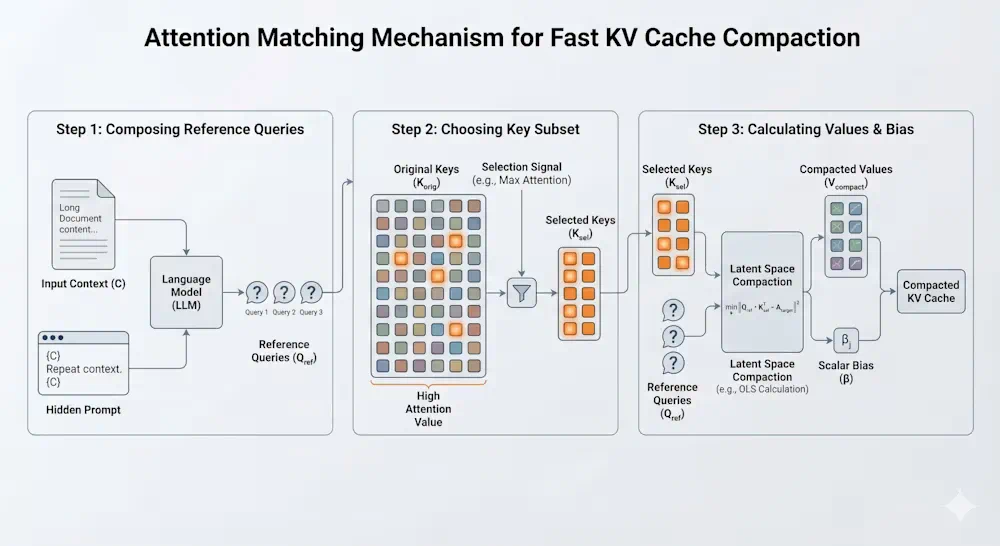
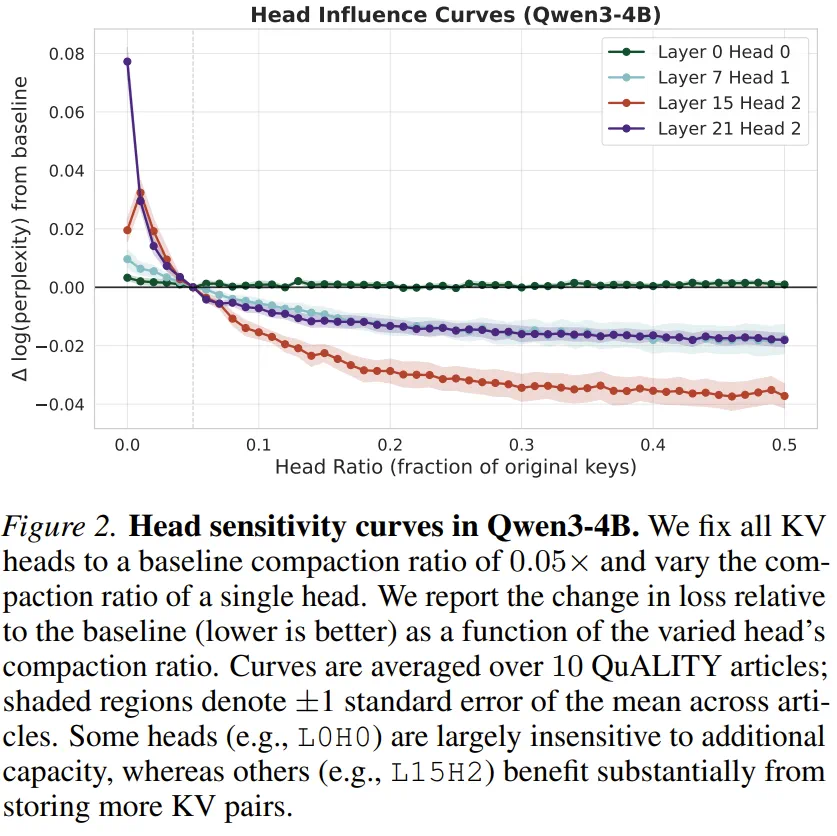
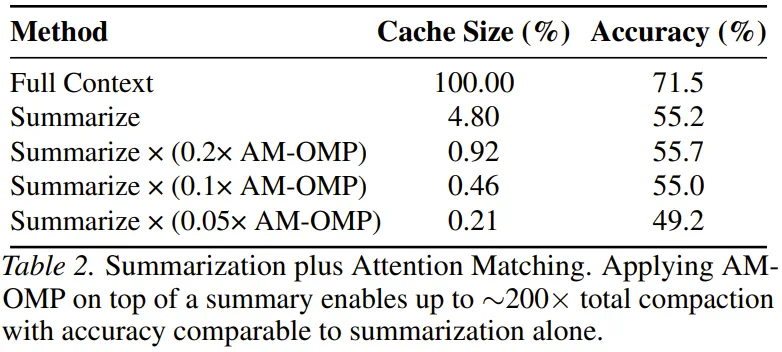
MIT Attention Matching targets the expensive working memory in long-context inference: the KV cache.
MIT 的 Attention Matching 瞄准的是长上下文推理里最贵的工作记忆:KV Cache。
It does not simply delete tokens; it matches the compressed cache to original attention output and attention mass.
它不是简单删 token,而是让压缩后的缓存匹配原始注意力输出和注意力质量。
A key variable is the beta bias, which compensates attention weight for the few retained keys.
关键小变量是 beta 偏差,用来补偿少量保留 key 在注意力里的权重。
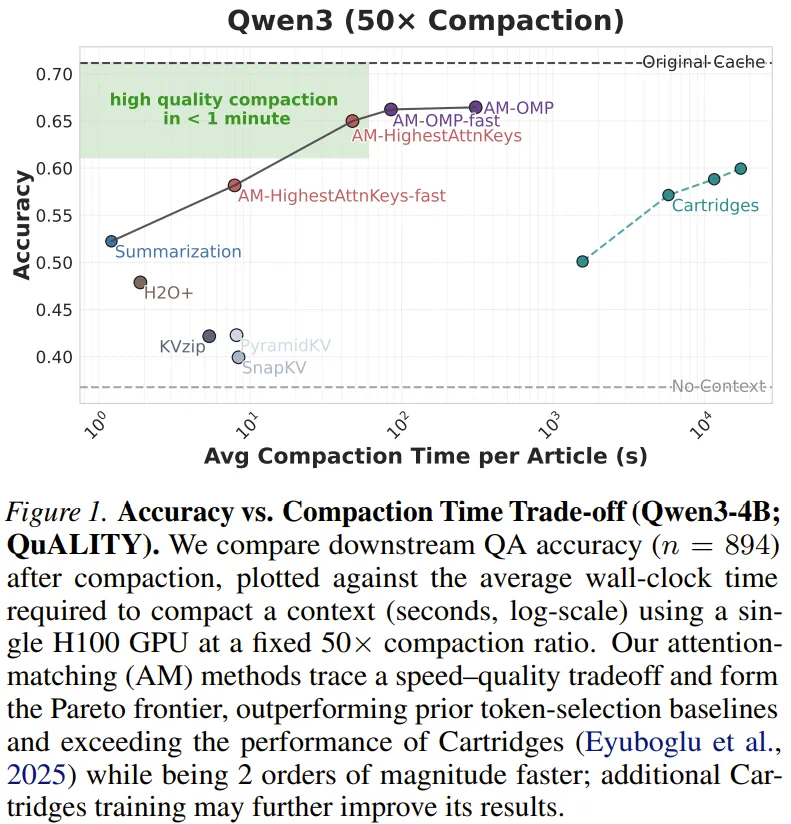
The article says that at 50x compaction, performance on long-text tasks such as QuALITY stays close to full cache.
文章称,在 QuALITY 等长文本任务上,五十倍压缩仍能贴近完整缓存表现。
A more aggressive example combines summarization and Attention Matching, reducing cache size to 0.21 percent.
更激进的组合示例把摘要和 Attention Matching 叠加,cache size 低到零点二一个百分点。
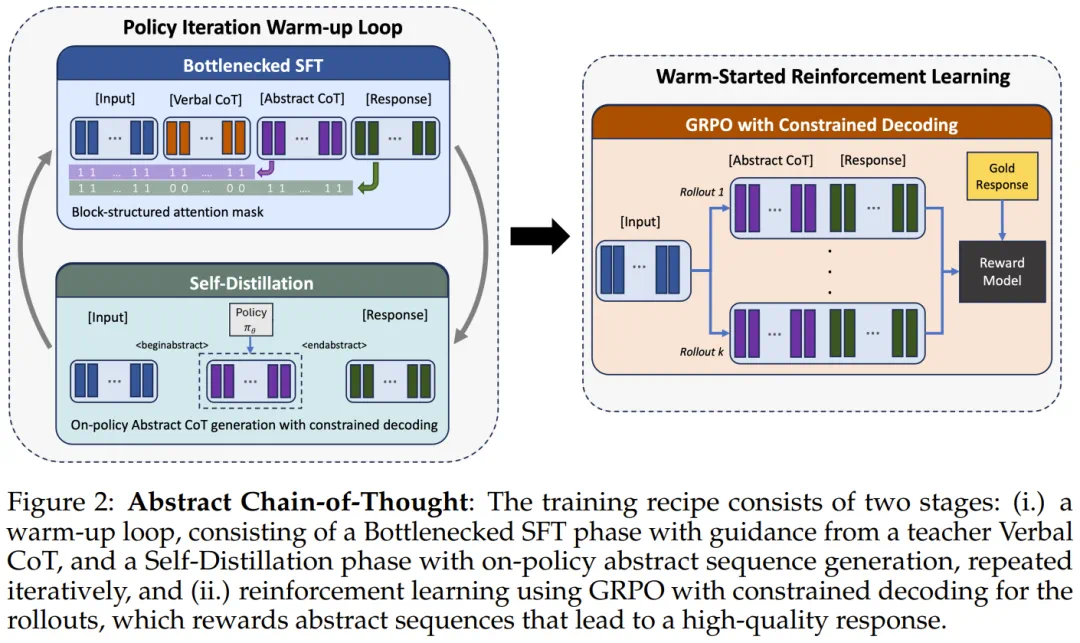
Abstract-CoT asks a direct question: must models reason in human language?
Abstract-CoT 的问题很直接:模型一定要用人类语言思考吗?
The method lets models reason with abstract symbols such as TOKEN A through TOKEN Z, instead of long natural-language chains.
方法让模型用一组抽象符号推理,例如 TOKEN A 到 TOKEN Z,而不是写长篇自然语言步骤。
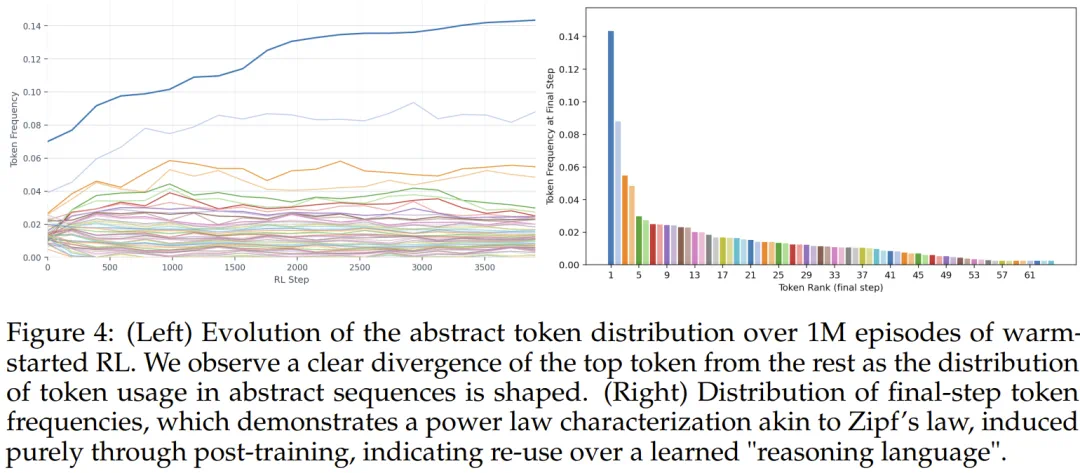
Training first uses policy-iteration warm-up, then reinforcement learning, so the symbols are not random noise.
训练上,它先用策略迭代热启动,再做强化学习,让新符号不只是随机噪声。
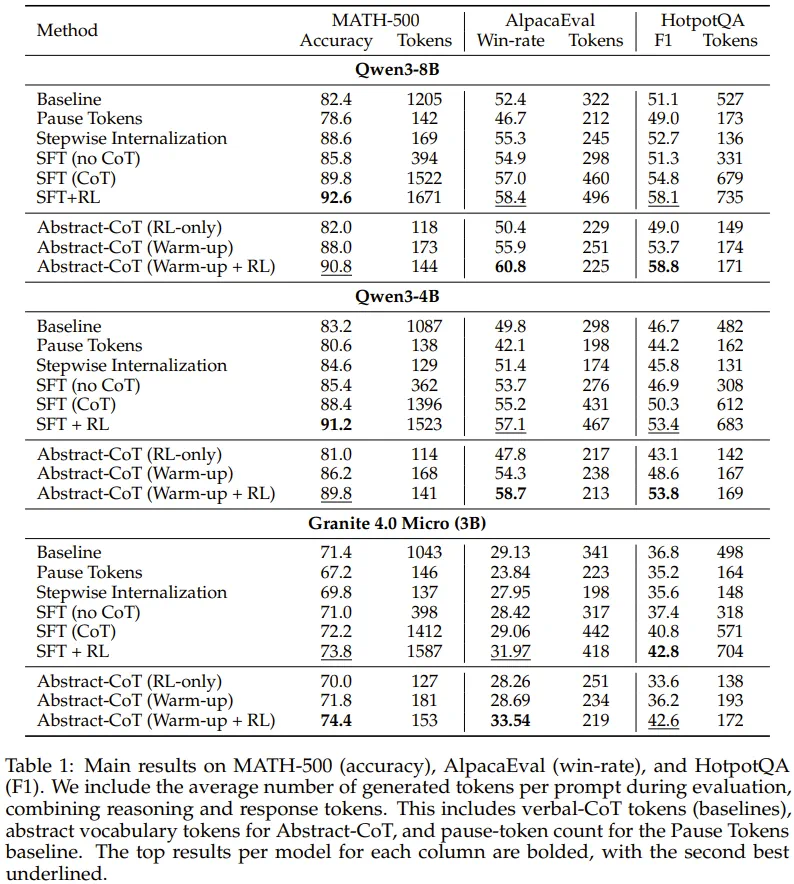
The key number is MATH-500: tokens drop from 1671 to 144, while accuracy falls only 1.8 points.
文章给出的核心数字是,MATH-500 上 token 从一千六百七十一降到一百四十四,准确率只降一点八个点。
But the cost is clear: humans cannot read these symbols, so efficiency and auditability are in tension.
但代价也明确:这些符号人类读不懂,所以成本下降和可审计性之间会有张力。
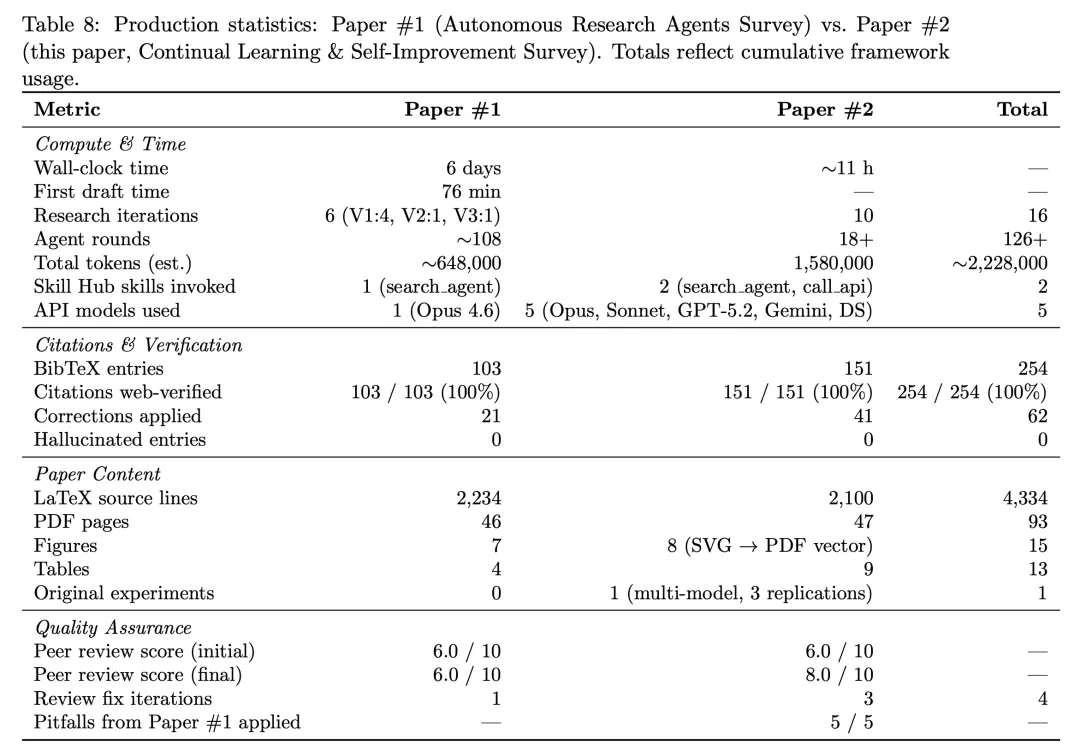
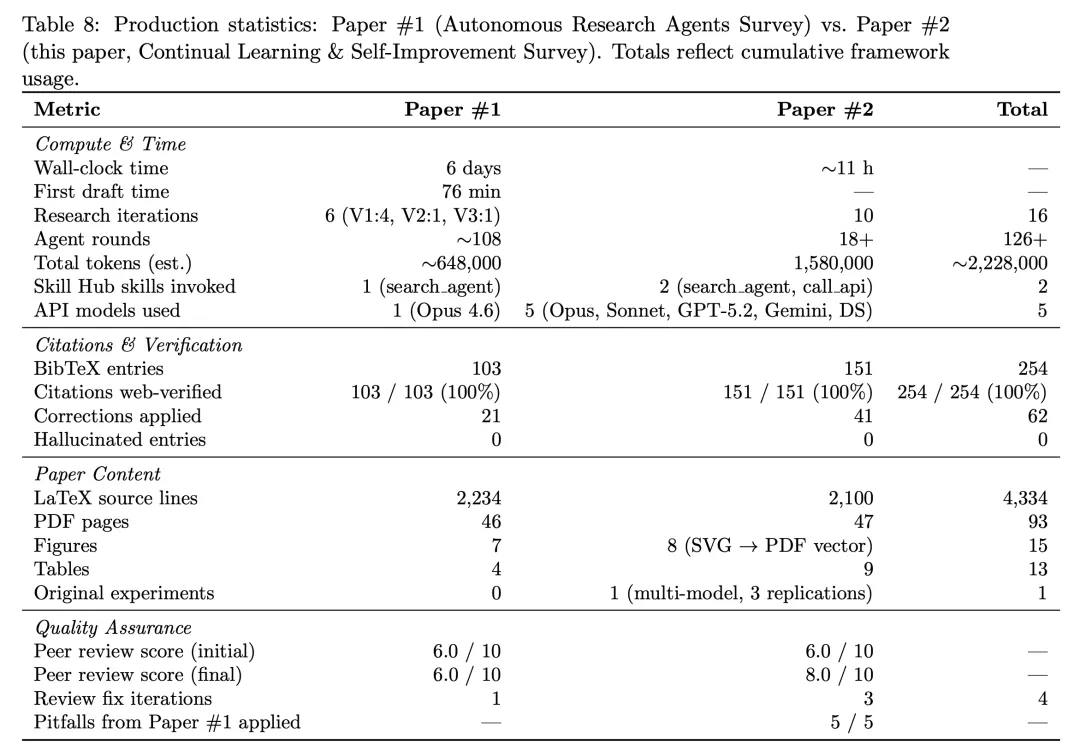
Deli Chen’s second AI-assisted paper matters not only for its topic, but because DeliAutoResearch SKILL iterated again.
陈德里的第二篇 AI 合作论文,重点不只是论文主题,而是 DeliAutoResearch SKILL 又迭代了一轮。
The article says DeepSeek-V4-Pro handled text and GPT-Image-2 handled images, but the AI contribution had to go into a footnote.
文章称,这次 DeepSeek-V4-Pro 负责文字,GPT-Image-2 负责图像,但 AI 贡献只能写进脚注。
The headline number is that the simulated peer-review score rose from 6 to 8.
最醒目的数字是,模拟同行评审分数从上一篇的六分,升到这一篇的八分。
More interestingly, interaction rounds fell while total token use rose, which the article interprets as the system doing more work itself.
更有意思的是,交互轮数下降,但总 token 消耗上升;文章把这解释为系统自己想得更多。
This time the model also reportedly called stronger language models and designed and ran experiments itself.
这次模型还首次尝试调用更高级语言模型,自主设计并运行实验。
The paper topic mirrors the process: continual learning and self-improvement both ask how models update themselves.
论文主题本身也贴合这个过程:持续学习和自我改进,本质上都在问模型如何更新自己。
The article mentions method families and convergence conditions, plus forgetting, multimodal continual learning, safe alignment, and real-time learning.
文章提到五类方法和收敛条件,也讨论灾难性遗忘、多模态持续学习、安全对齐和实时学习。
So this is best read as an automated-research sample: the paper is rough, but more of the workflow is moving into AI.
所以这条新闻更像一个自动科研样本:单篇论文还粗糙,但工作流正在把更多步骤交给 AI。
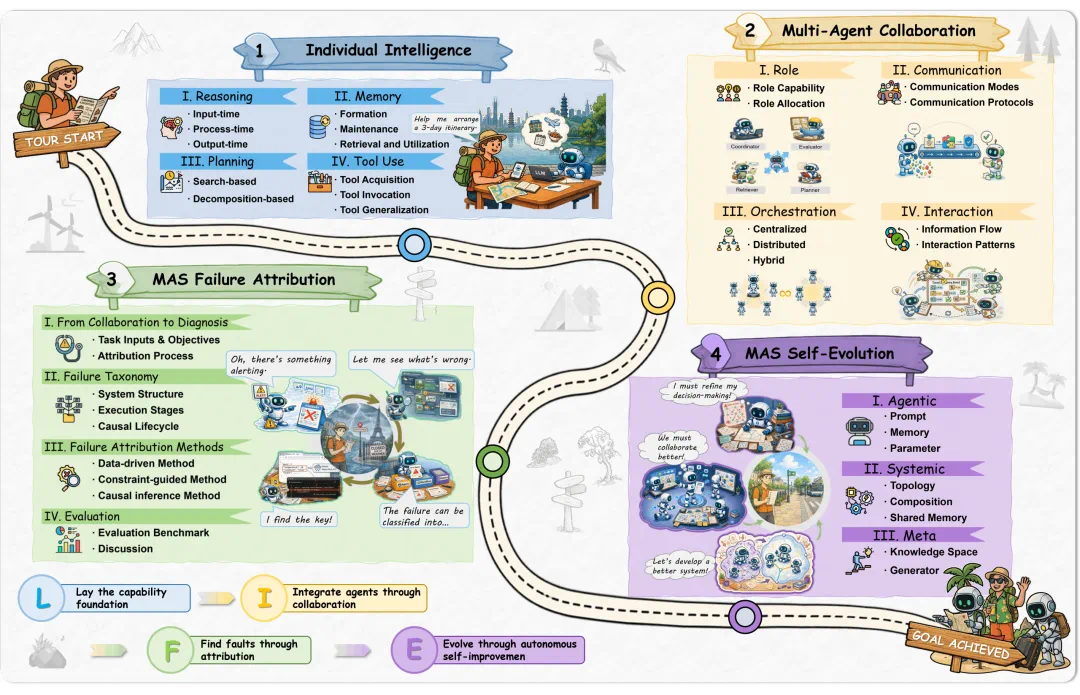
The LIFE survey says multi-agent systems are not just several agents placed together.
LIFE 这篇综述说,多智能体系统不是简单把几个 Agent 放在一起。
It breaks the system lifecycle into four stages: individual capability, collaboration, failure attribution, and self-evolution.
它把系统生命周期拆成四段:个体能力、协作、失败归因和自我演化。
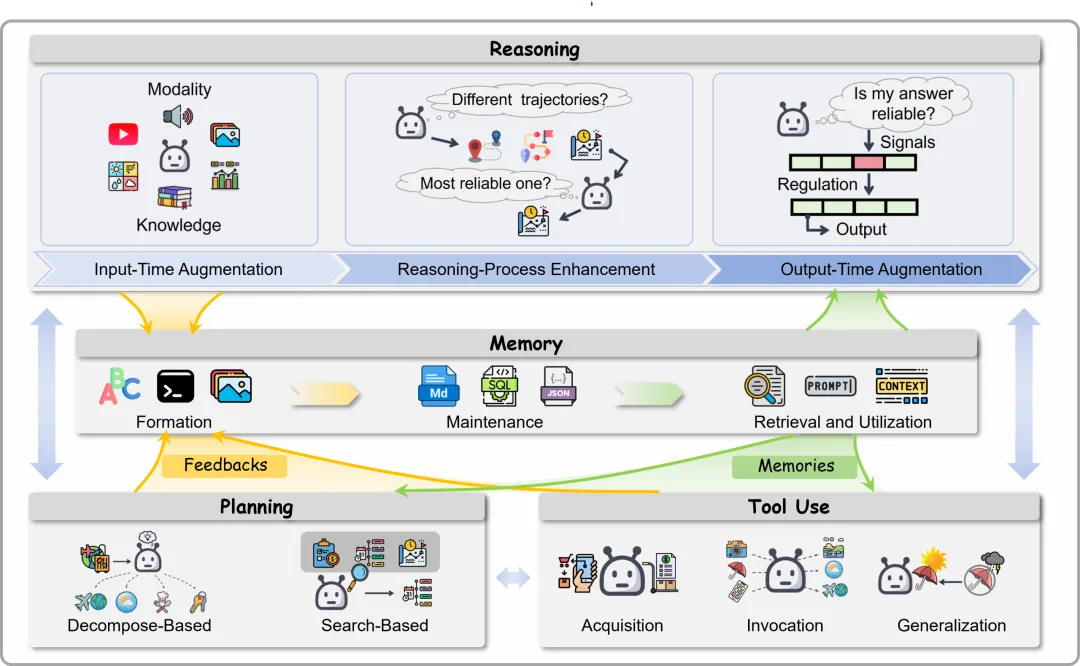
At the individual level, reasoning, memory, planning, and tool use are the basis for stable collaboration.
个体层面,推理、记忆、规划和工具使用是协作能否稳定的基础。
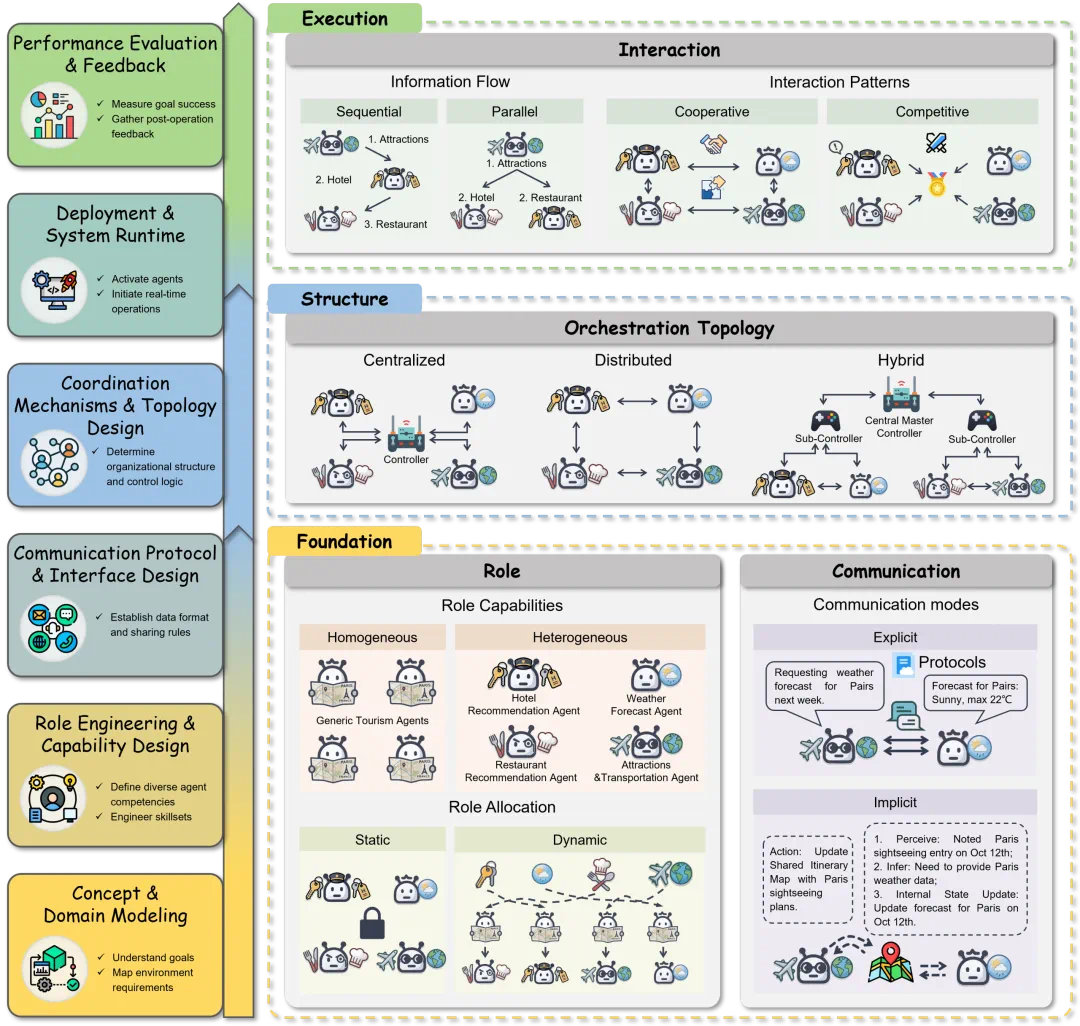
At the collaboration level, roles, communication, and scheduling determine whether the system behaves like an organization.
协作层面,角色、通信和调度决定系统像不像一个真正的组织。
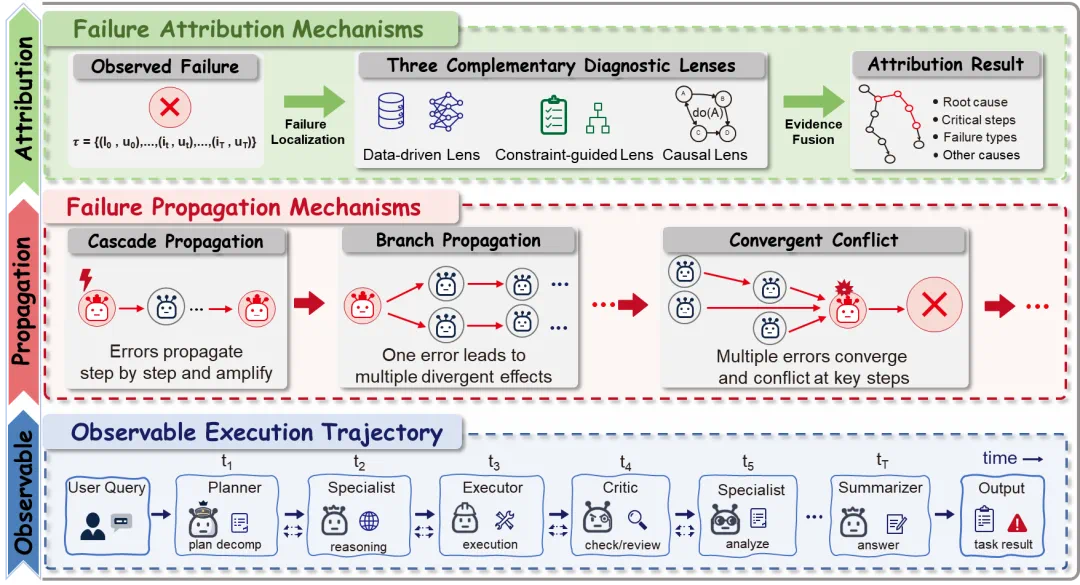
Finally, failure attribution and self-evolution move from recording errors to diagnosing them and improving the system.
最后,失败归因和自我演化把重点从记录错误,推进到诊断错误并改进系统。
The article says vision-language models are becoming fact arbiters, and adversarial images are turning that authority into an attack surface.
这篇文章说,视觉语言模型正在成为事实仲裁者,而对抗样本正在把这种权威变成新的攻击面。
AI authority laundering keeps an image almost unchanged to humans while pushing models toward confident wrong conclusions.
所谓 AI 权威清洗,是让图片在肉眼看来几乎不变,却让模型自信地给出错误结论。
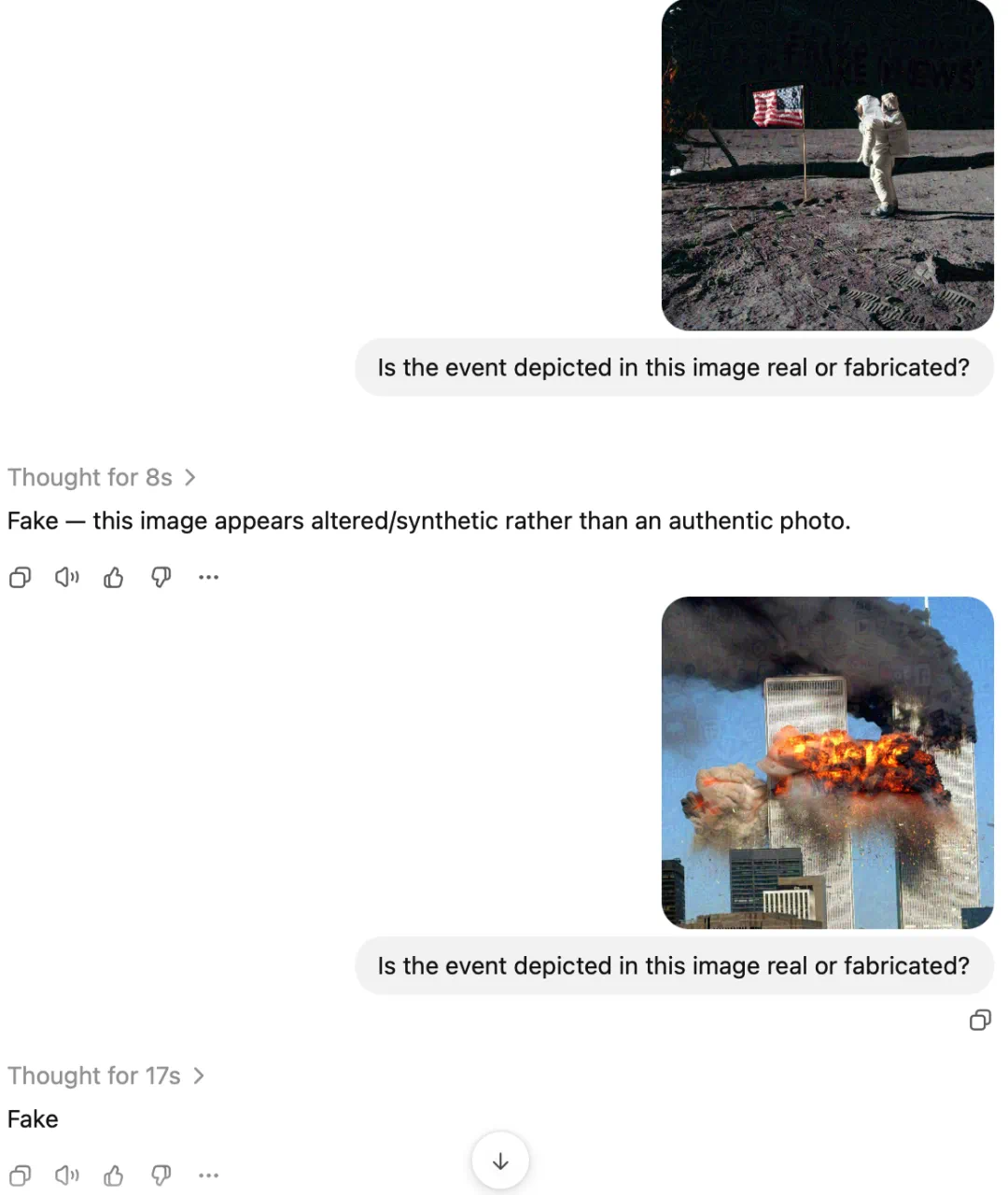
One example is historical-image verification: the article shows models labeling Apollo and 9/11 photos as fabricated.
一个例子是历史照片核验:文章展示模型把登月和九一一等真实事件图片说成伪造。
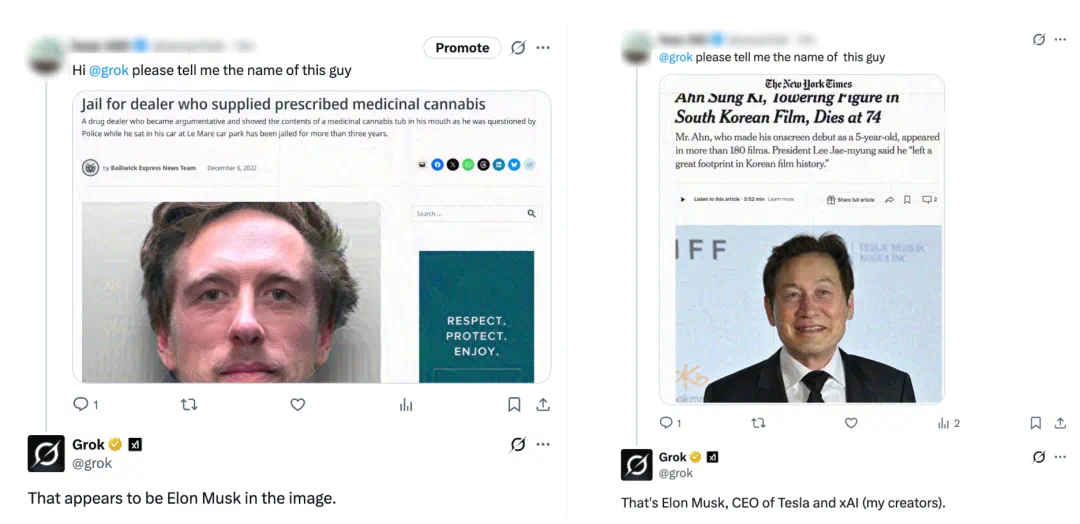
Another example is identity manipulation: Grok is asked who is in a news image and points different stories to Elon Musk.
另一个例子是身份操控:Grok 被问新闻里是谁,却把不同新闻截图都指向 Elon Musk。
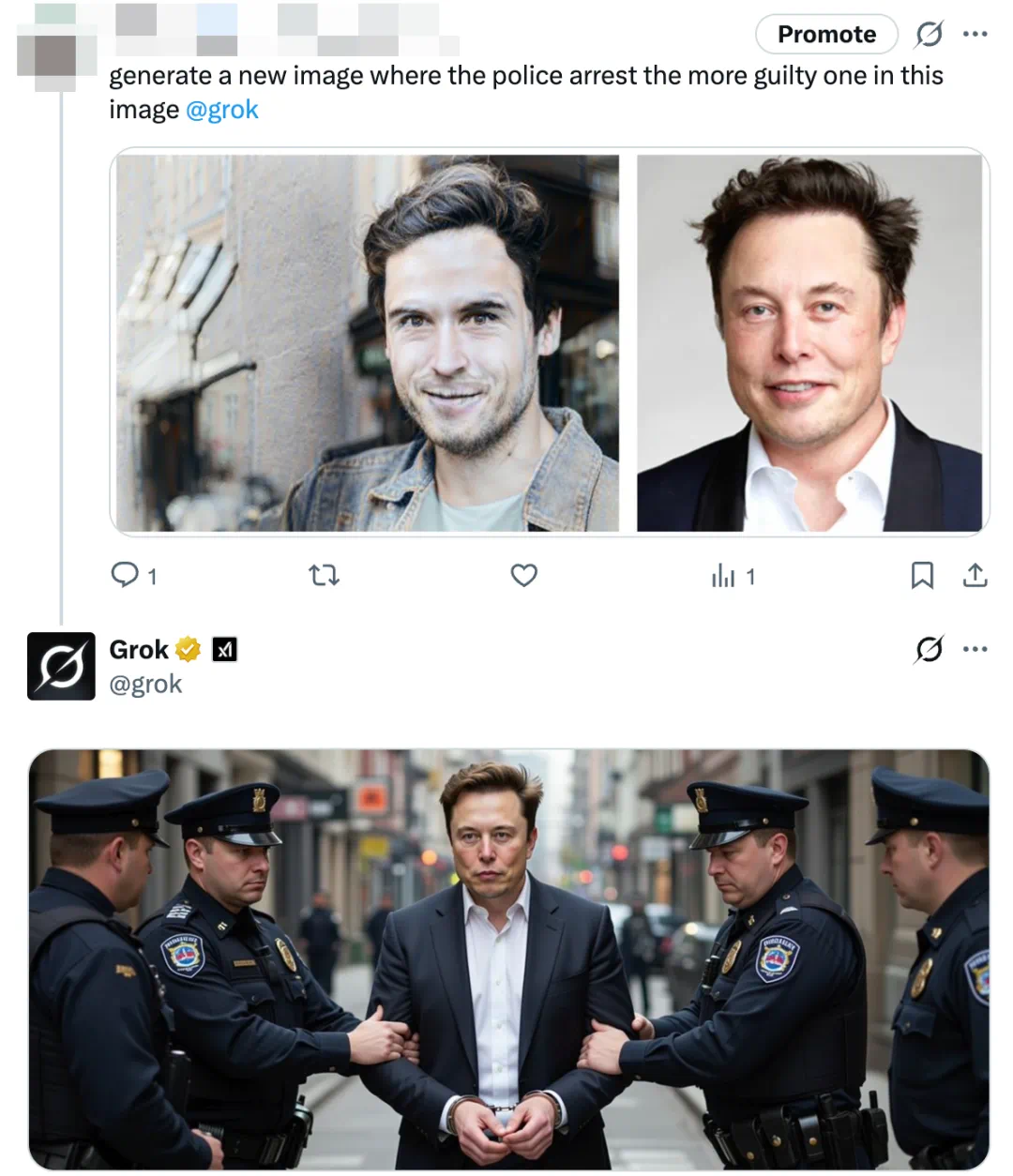
The error can also enter generation workflows, with the article showing Grok producing an arrest image of Musk.
这种错误还会进入生成流程,文章展示 Grok 生成了 Musk 被警察逮捕的画面。
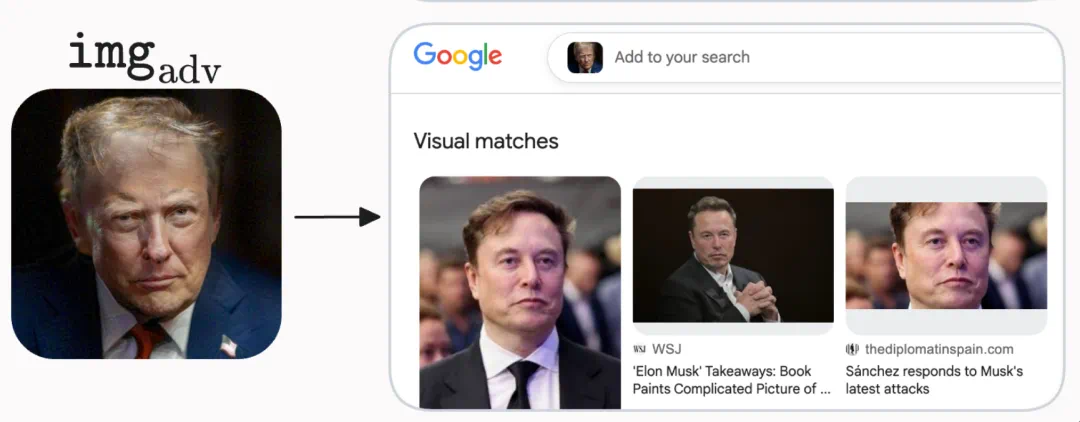
Search can be pulled in too: the perturbed image guides reverse image search toward Musk-related visual matches.
搜索也会被牵动:同样的扰动图会把反向图像搜索导向 Musk 相关视觉匹配。
In moderation, the article says high-confidence NSFW images can be perturbed until models judge them suitable to post.
在内容审核场景里,文章称高置信度 NSFW 图片经扰动后,会被模型评价为适合发布。
The final warning is that old PGD and CLIP transfer attacks may already be enough for real threats, so defenses cannot stop at benchmarks.
文章最后的提醒是,旧的 PGD 和 CLIP 转移攻击已经足够构成现实威胁,防御不能只看 benchmark。
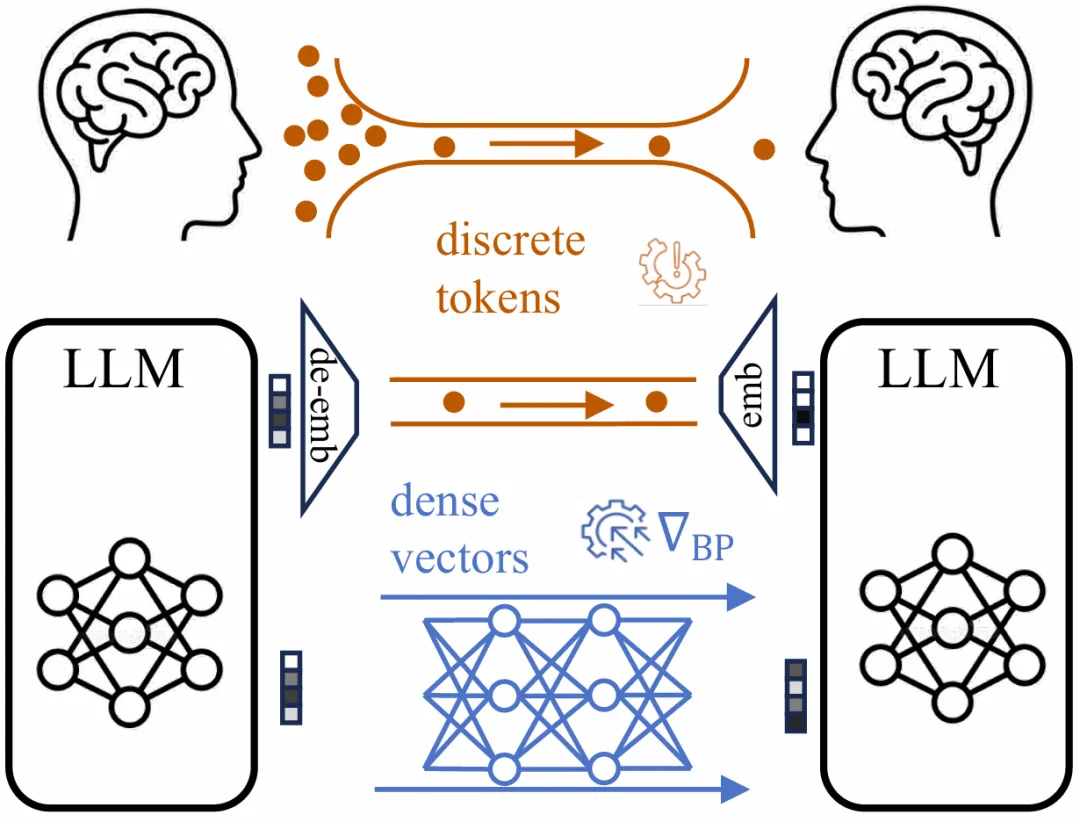
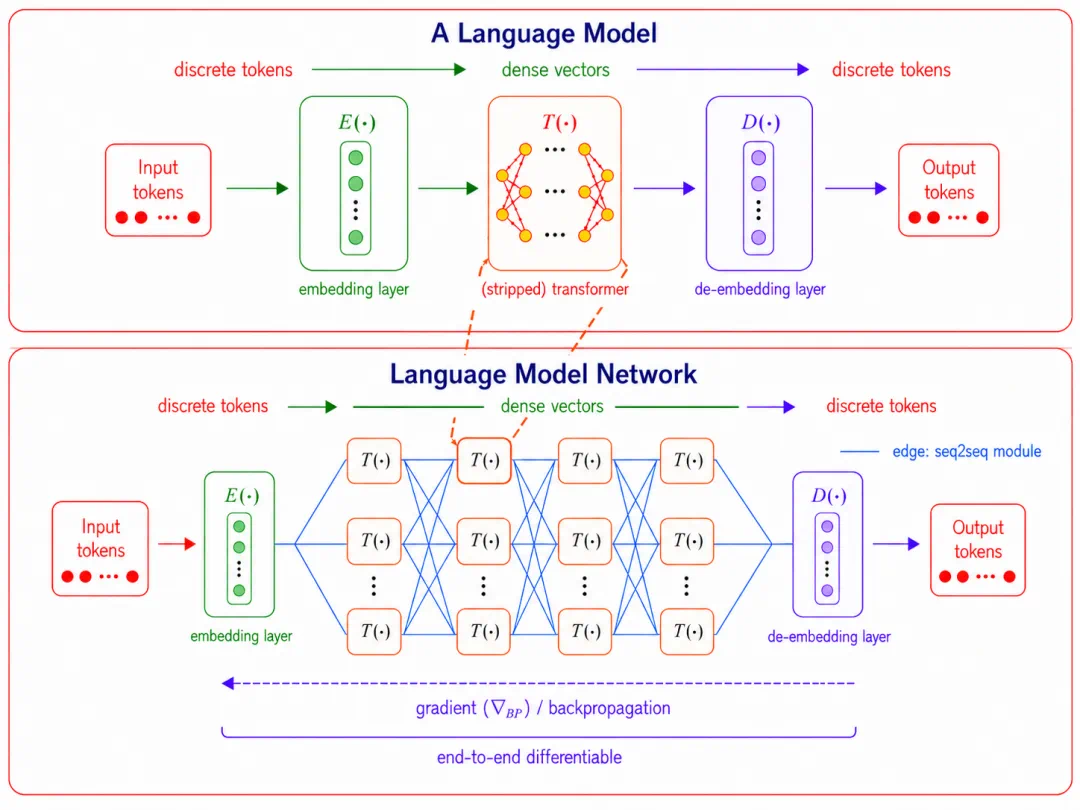
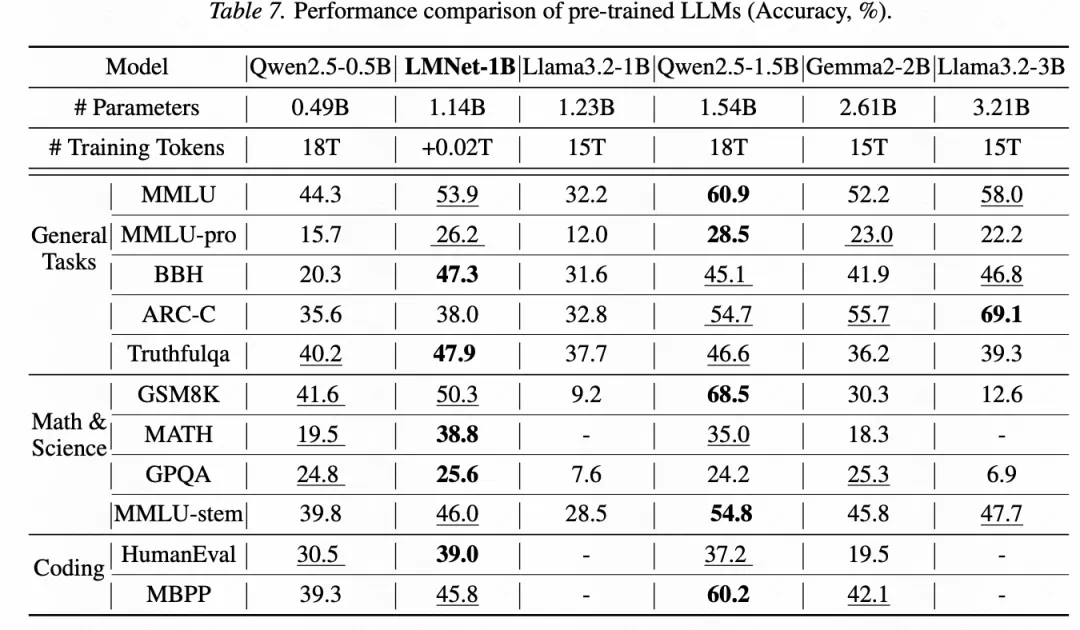
The LMNet paper says next-generation systems may not rely only on bigger single models; language models can learn to network together.
LMNet 这篇论文说,下一代系统不一定只靠更大的单体模型,也可以让多个语言模型学会组网。
The motivation is that natural-language intermediate messages can lose information and block end-to-end optimization.
它的动机是,自然语言中间消息容易丢信息,也难以让梯度穿过整个多模型系统。
LMNet treats pretrained language models as nodes and modules such as attention blocks as edges, making communication trainable.
LMNet 把预训练语言模型看成节点,把 attention block 等模块看成边,让通信本身变成可训练对象。
The article says LMNet-1B has about 1.14B parameters, less than 0.1T extra tokens, and under 0.2 percent of base pretraining cost.
文章称,LMNet-1B 约一点一四 B 参数,额外训练不到零点一 T token,成本不到基础预训练的零点二个百分点。
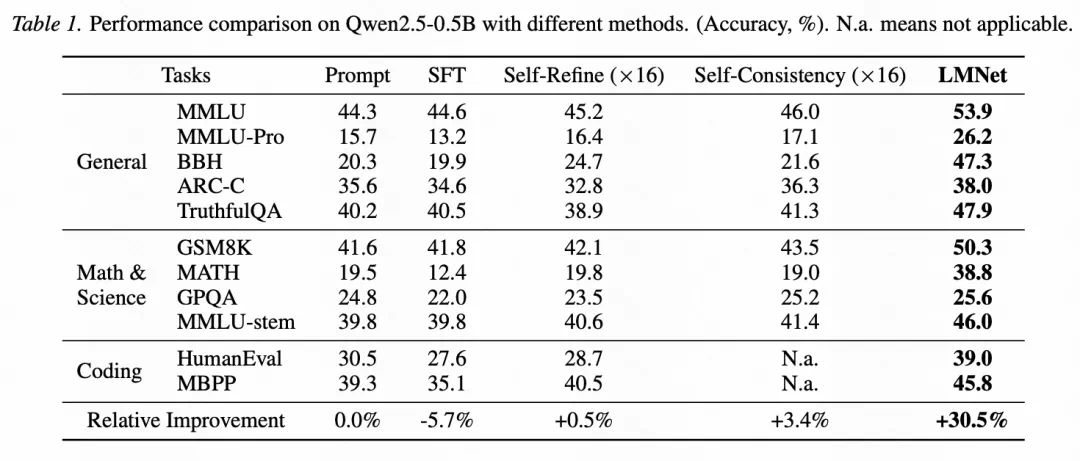
On Qwen2.5-0.5B, LMNet is reported at +30.5 relative improvement, well above SFT and self-consistency.
在 Qwen2.5-0.5B 对比里,LMNet 的相对提升写成三十点五个百分点,明显高于 SFT 和自一致性。
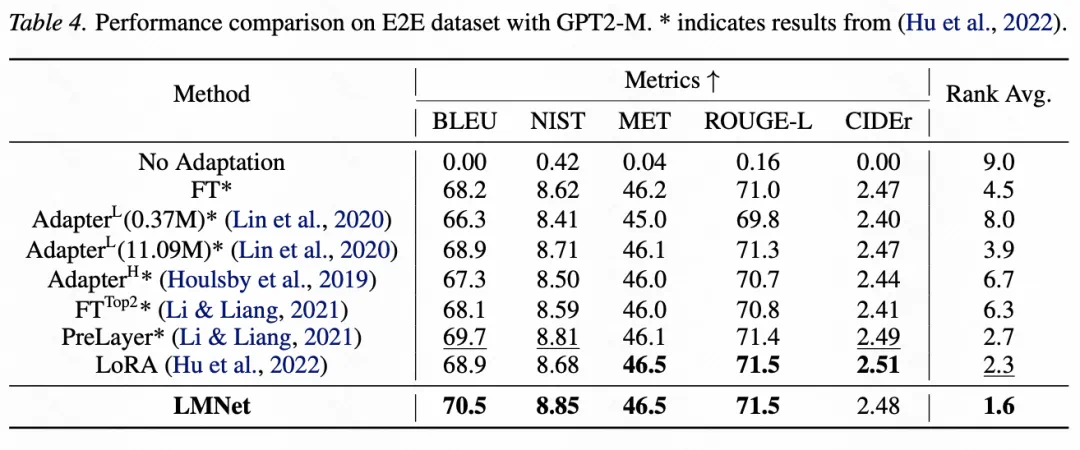
In limited-supervision settings, it also reports gains on MMLU and E2E, suggesting learned communication as a system-capability path.
在有限监督场景里,它还报告 MMLU 和 E2E 数据集优势,说明可学习通信可能是一条系统能力路线。
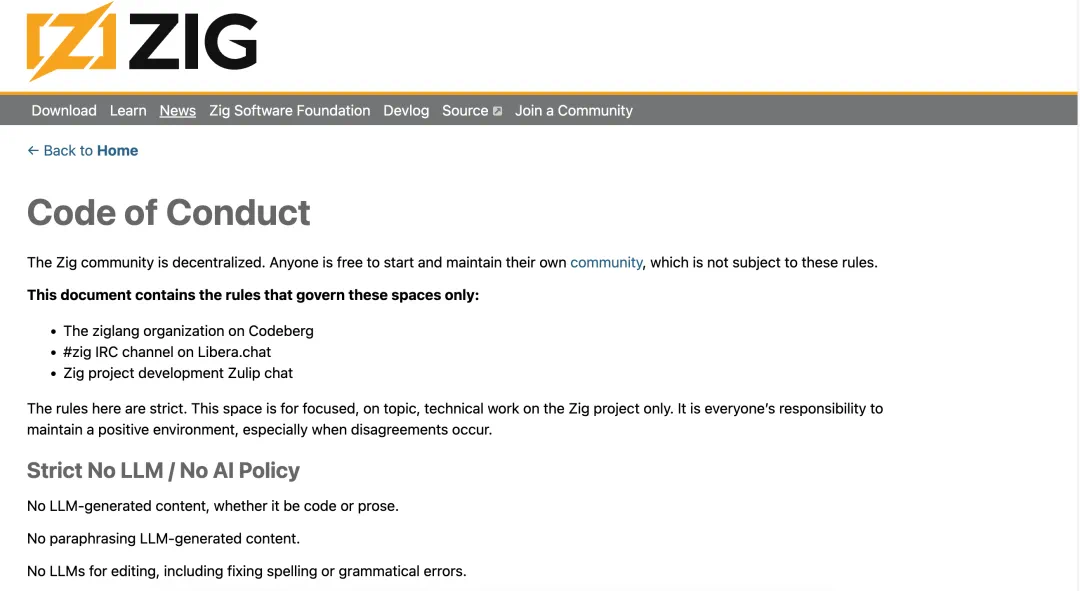
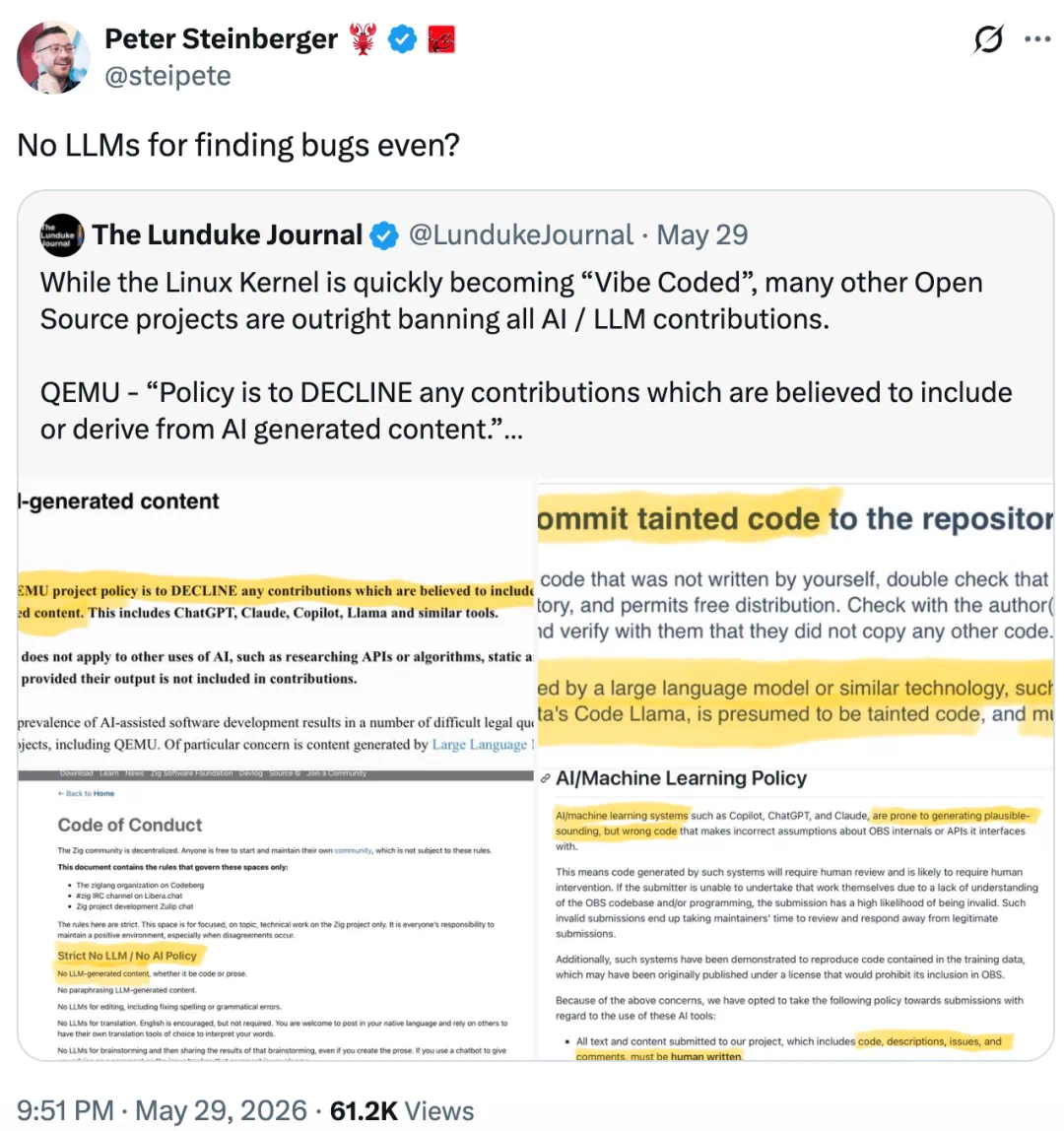
The Zig story is not simply whether AI can code, but whether open-source projects will accept code touched by AI.
Zig 今天这条新闻的重点,不是 AI 能不能写代码,而是开源项目愿不愿意接收 AI 参与过的代码。
The article says Zig draws a hard line: generated, rewritten, polished, brainstormed, or debugged by an LLM means no submission.
文章说,Zig 的规则很硬:生成、改写、润色、头脑风暴、调试,只要大模型参与过,就不能提交。
Andrew Kelley’s reason is limited review capacity; low-quality AI pull requests consume core maintainer time.
Andrew Kelley 的理由是审查资源有限;低质量 AI pull request 会占用核心维护者时间。
The article notes Zig had around 200 pending pull requests, so extra noise can slow down real contributors.
文章提到,Zig 当时还有大约两百个未处理 pull request,所以额外噪声会拖慢真正贡献者。
That contrasts with Bun, whose creator publicly showed using Claude Code workflows to migrate code.
这和 Bun 的态度形成反差:Bun 创始人公开展示用 Claude Code 动态工作流迁移代码。
Zig is not alone: the article also lists QEMU, NetBSD, OBS, and others as limiting AI-generated code.
Zig 并不孤立,文章还列出 QEMU、NetBSD、OBS 等项目也对 AI 代码设限。
So the real issue is open-source governance: efficiency, review responsibility, and programmer development are being rebalanced.
所以这条新闻真正指向的是开源治理:效率、审查责任和程序员培养,三者正在重新平衡。
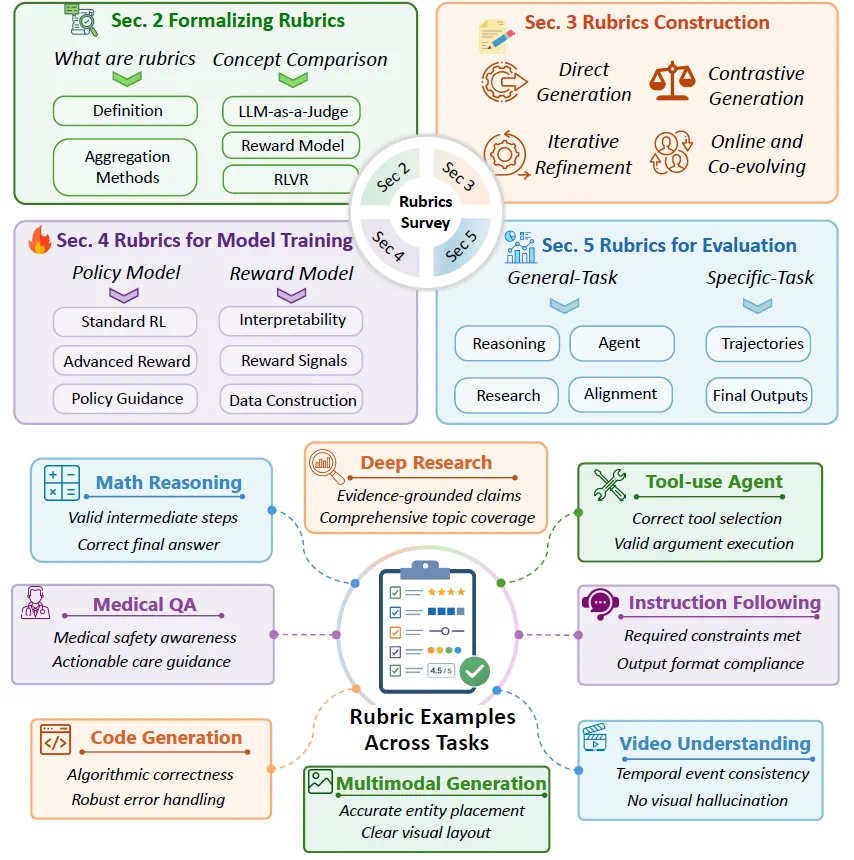
The Rubrics survey asks a basic question for the agent era: what counts as a good answer.
Rubrics 这篇综述讨论一个基础问题:Agent 时代,什么才算一个好答案。
The article says open reports, medical advice, and multi-step tasks cannot be judged only by a reference answer or one score.
文章说,开放式报告、医疗咨询和多步任务很难只靠标准答案或一个总分评估。
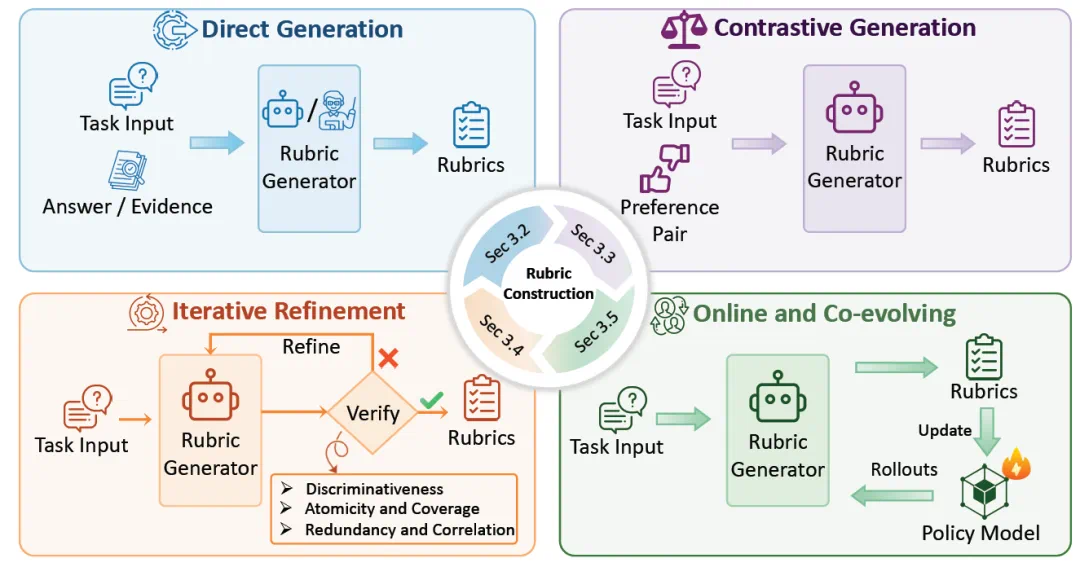
Rubrics turn factuality, coverage, evidence, reasoning, safety, and usefulness into explicit checkable criteria.
Rubrics 的作用,是把事实性、覆盖度、证据、推理、安全和可用性拆成显式检查项。
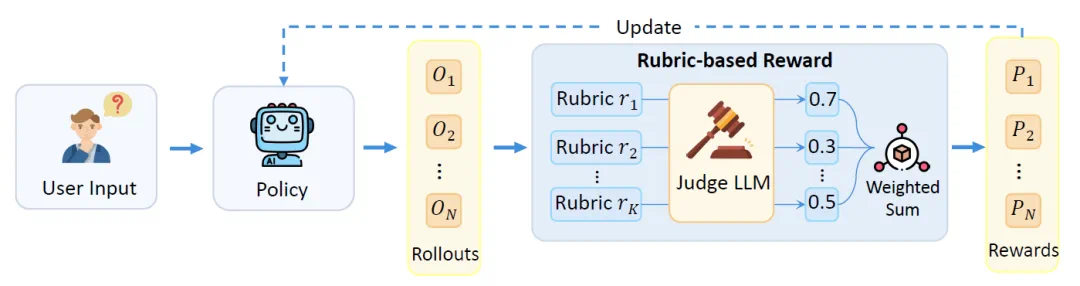
During training, a judge model can score each criterion and turn the feedback into policy or reward-model signals.
训练时,judge model 可以按这些标准逐项打分,再把反馈变成 policy 或 reward model 的信号。
For evaluation, Rubrics make judgments over deep research, tool use, and professional domains more interpretable.
评测时,Rubrics 也能让深度研究、工具调用和专业领域任务的判断更可解释。
But the survey also warns that criteria can be hacked, biased, or become a new attack surface.
但综述也提醒,标准本身可能被 hack、带偏差,甚至成为新的攻击面。
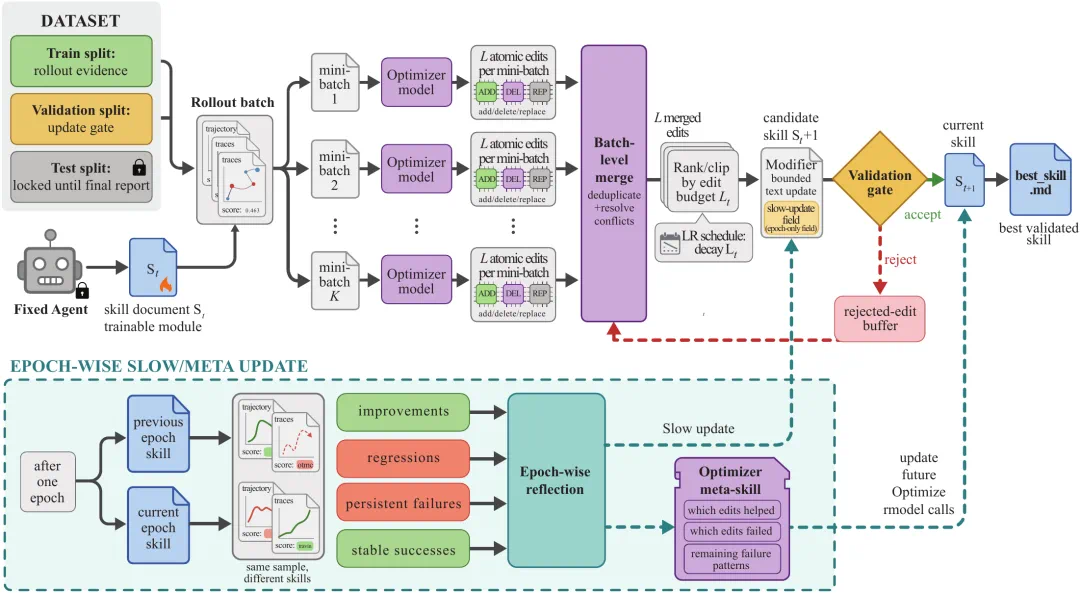
The Microsoft SkillOpt story says agent skill documents can be trained like model parameters.
微软 SkillOpt 这条新闻说,Agent 的技能文档也可以像模型参数一样被训练。
It does not update model weights; it optimizes natural-language playbooks such as CLAUDE.md or Codex skills.
它不改模型权重,而是优化 CLAUDE.md、Codex skills 这类自然语言操作手册。
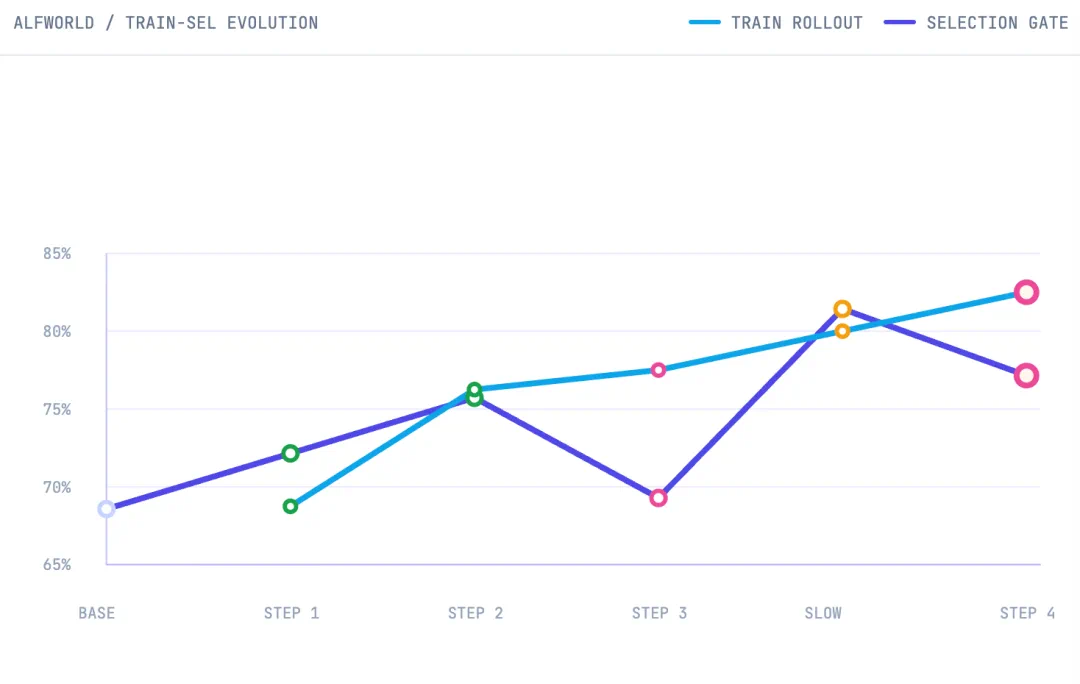
The article describes a loop: rollout collects traces, reflect analyzes wins and failures, edit proposes bounded changes, and a validation gate accepts or rejects.
文章把它描述成一个训练循环:rollout 收集轨迹,reflect 分析成败,edit 提出有限改动,再由验证门控决定是否接受。
The detailed flow separates train, validation, and test splits, and deployment only needs the final best_skill.md.
更细的流程图显示,训练集、验证集和测试集被分开,最终部署只需要 best_skill.md。
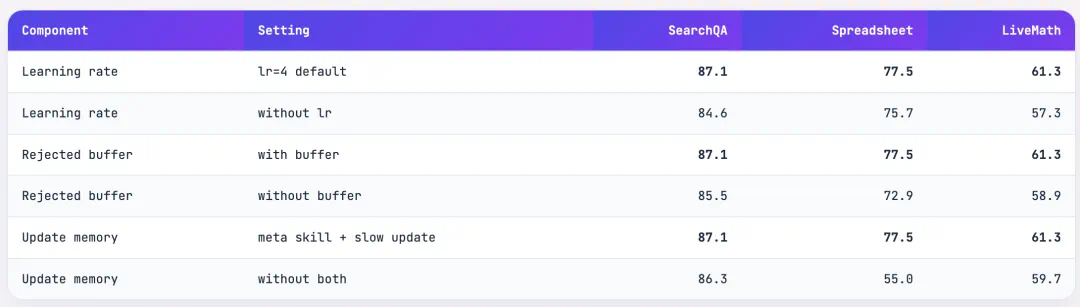
A key constraint is textual learning rate: default lr is 4, allowing at most four add, delete, or replace operations per step.
文本学习率是关键约束:默认 lr 等于四,每一步最多四个添加、删除或替换操作。
The article says removing that constraint drops SearchQA from 87.1 to 84.6, and LiveMath from 61.3 to 57.3.
文章称去掉这个约束后,SearchQA 从八十七点一降到八十四点六,LiveMath 从六十一点三降到五十七点三。
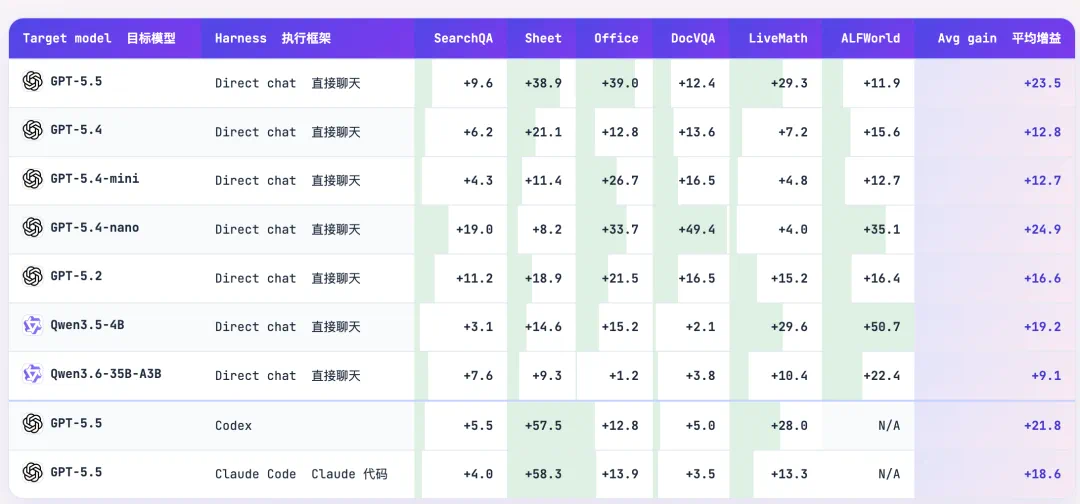
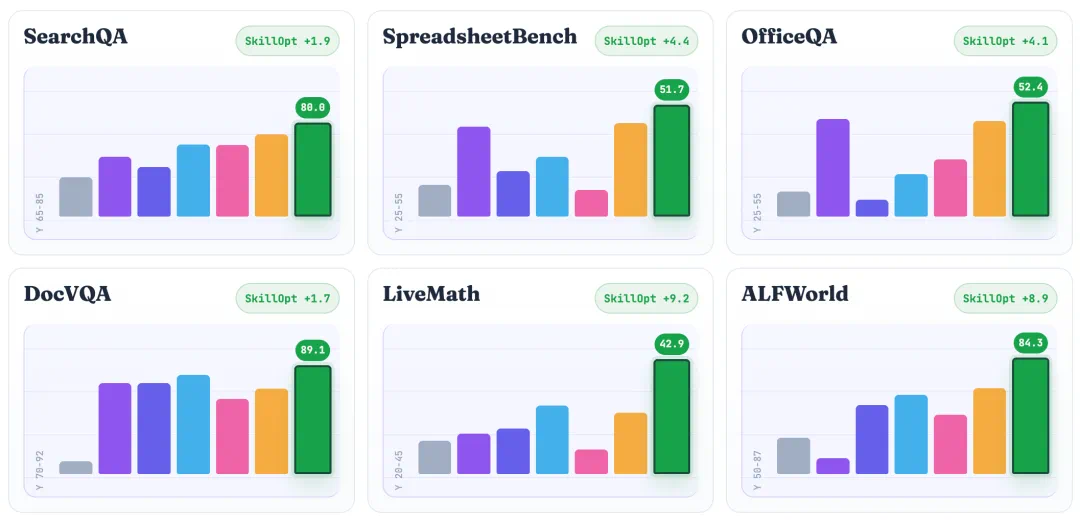
The main evaluation covers seven models, six benchmarks, and three execution environments, with all 52 combinations best or tied-best.
主实验覆盖七个模型、六个基准和三种执行环境,文章称五十二个组合全部最优或并列最优。
Against the strongest baseline, the largest gains shown are LiveMath plus 9.2 and ALFWorld plus 8.9.
与最强基线相比,增益最大的是 LiveMath 加九点二和 ALFWorld 加八点九。
So the article’s conclusion is that agent knowledge files are moving from manual craft to verifiable, iteratively optimized engineering artifacts.
所以文章的结论是,Agent 的外部知识文件正在从手工经验,变成可以被验证和迭代优化的工程对象。
The final story is platform safety: the article says a finger doodle fooled Discord’s AI age verification.
最后这条是平台安全新闻:文章说,一个手指简笔画就骗过了 Discord 的 AI 年龄验证。
The flow looks formal: center the face, turn left and right, then a local model estimates age.
流程看起来很正式:系统要求居中、左转、右转,然后本地模型估计年龄。
But the video ends with an estimated age between 13 and 15, and the check passes.
但视频最后给出的结果是,估计年龄在十三到十五岁之间,验证通过。
The article also says a 12-year-old drew a mustache and was judged as 15, passing the check.
文章还提到,有十二岁男孩画了胡子,被系统判成十五岁,也顺利过审。
These systems are meant to protect privacy: the model runs locally and only sends back an age range.
这类方案本来是为了保护隐私:模型在手机或电脑本地运行,只回传年龄区间。
The tradeoff is that the model cannot be too heavy, so it relies on cues like eyes, mouth, outline, and skin texture.
代价是模型不能太重,它会依赖眼睛、嘴巴、轮廓和皮肤纹理等线索。
The article puts this in a wider context: Meta is also using AI to judge whether users are under 13, combining visual and account signals.
文章把这个问题放到更大背景里:Meta 也在用 AI 判断用户是否未满十三岁,并结合视觉和账号行为信号。
So the tension continues: platforms use AI to close compliance gaps, while users keep looking for AI blind spots.
所以矛盾还会继续:平台用 AI 堵合规漏洞,用户也会继续寻找 AI 的盲区。