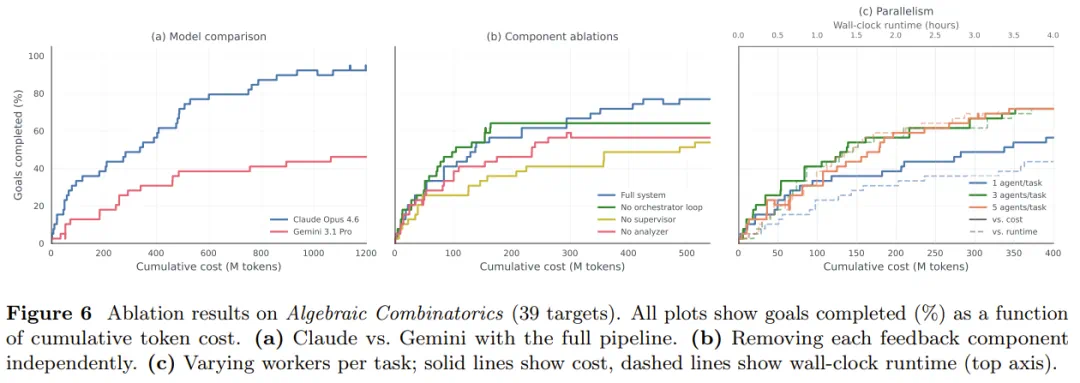
The article frames Step 3.7 Flash around a practical problem: agent work is getting stronger and more expensive.
这篇文章把 Step 3.7 Flash 放在一个很现实的背景里:Agent 任务正在变强,也正在变贵。
The opening examples point to token cost as a deployment bottleneck for complex agent workflows.
文章开头用开发者和厂商的讨论说明,复杂 Agent 工作流的 token 成本已经成为部署门槛。
The product framing is not a flagship replacement, but a model that can run frequent agent tasks more affordably.
发布语境里,Step 3.7 Flash 的卖点不是替代旗舰模型,而是让高频 Agent 任务更容易跑起来。
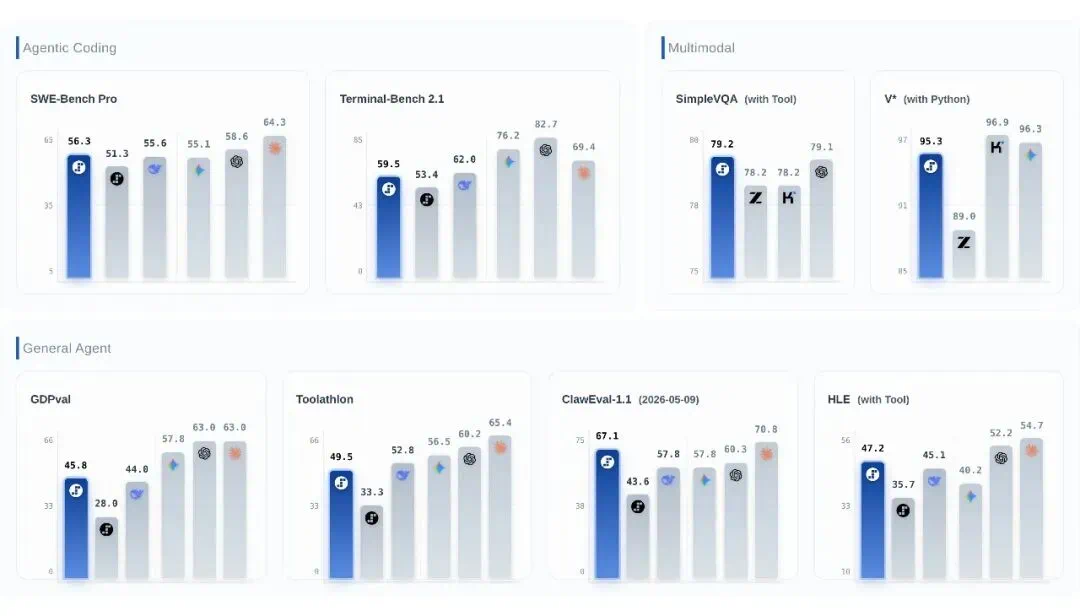
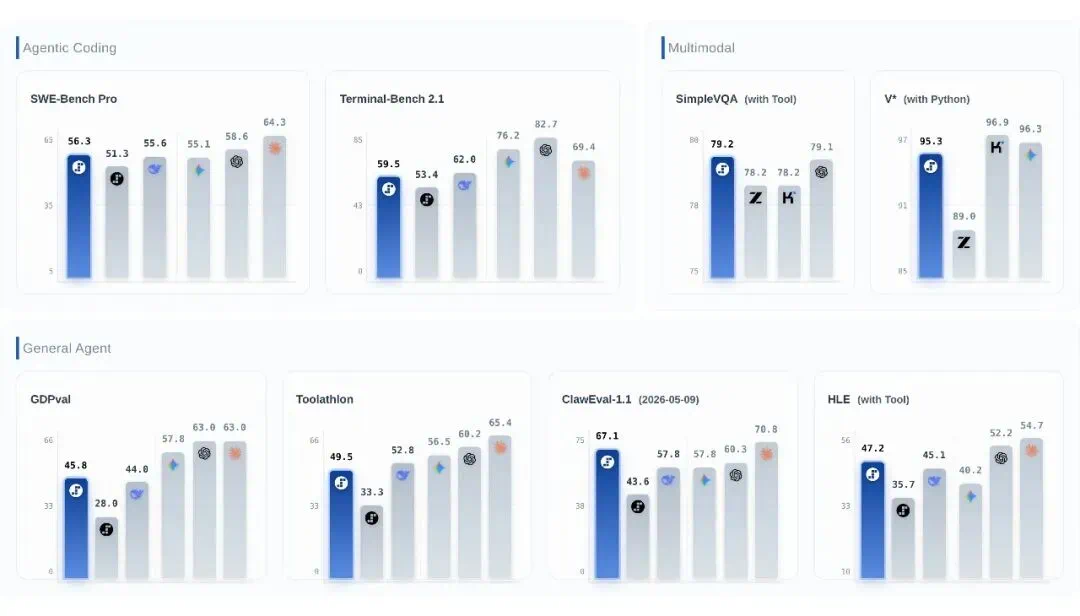
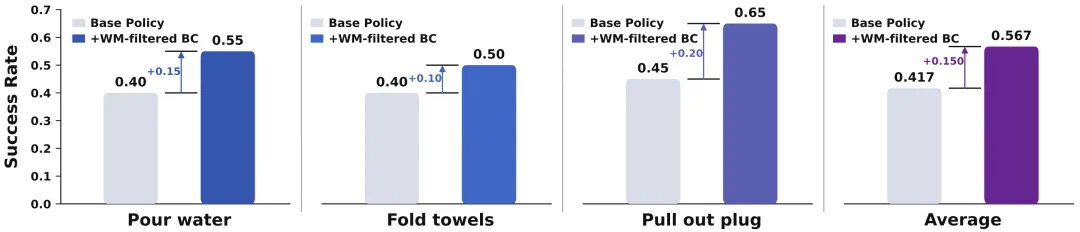
In benchmarks, the article reports 67.1 percent on ClawEval-1.1 and leading results on tool-use tests.
在 benchmark 部分,文章称它在 ClawEval-1.1 得到 67.1%,工具相关测试也进入领先梯队。
Multimodal understanding is one major update, shown through a Pinterest interface analysis task.
多模态能力是这次更新的第一组重点,文章展示它分析 Pinterest 页面结构和视觉设计。
Another example is a cockpit interface, where the model must connect visual elements with operating steps.
另一个例子是驾驶舱界面,模型需要识别仪表、按钮和操作流程,而不是只描述画面。
The Deep Research section says search enters the reasoning loop and produces structured answers.
Deep Research 部分强调,检索不是外挂,而是进入推理循环,模型会整合资料后结构化交付。
In the multi-agent demo, virtual personas evaluate options in parallel and produce a voting distribution.
在多 Agent 演示里,文章把重点放到并发协作:多个虚拟角色同时评估方案,最后形成投票分布。
The article also shows graph-like outputs, suggesting the model organizes relationships rather than only returning text.
文章还给出知识图谱式输出,说明模型不只返回文本,也在组织关系和结构。
The multi-agent section focuses on throughput: 400 TPS matters for concurrent workflows.
多 Agent 并行部分则把重点放在吞吐上:400 TPS 决定了并发工作流能跑多快。
The final capability cluster is GUI control, starting with information summarization on a phone interface.
最后一组能力是 GUI 操控,第一关让模型在手机页面中完成信息汇总。
The second mobile task is travel planning, combining weather, maps, routes, and constraints.
第二关是出行规划,任务需要同时处理天气、地图、路线和约束条件。
The third task is more complex, switching between social and shopping apps for a cross-platform workflow.
第三关更复杂,要在社媒和电商页面之间切换,完成跨平台任务。
The conclusion is that Flash models are not flagship substitutes, but cost and speed tradeoffs for frequent agent calls.
文章的结论是,Flash 模型不是旗舰版平替,而是面向大量 Agent 调用的成本和速度折中。
These are still launch claims and demos; real stability depends on independent tests and deployment details.
但所有这些仍是发布文章和演示素材,真实稳定性还要看独立评测和具体部署链路。
The larger signal is an engineering shift from stronger agents to agents that can run at scale.
所以这条新闻真正值得看的,是 Agent 模型从“更强”转向“更能规模化运行”的工程趋势。
The article also frames the 11B active scale as a design choice: keep core reasoning in weights and handle more perception during the task.
文章还把 11B 激活规模作为背景:模型不靠无限堆大,而是把核心推理能力留在权重里,把更多感知边界放到任务过程中解决。
That is why the article emphasizes tools: agent competition is moving from one-shot answers to planning, searching, calling, and checking.
这也是为什么文章反复强调工具调用:Agent 模型的竞争点,已经从单轮回答变成持续规划、搜索、调用和校验。
For companies, the issue is not one impressive demo, but whether hundreds of concurrent tasks can finish within budget.
对企业来说,真正的问题不是能不能做一次漂亮演示,而是每分钟几百个并发任务能否在预算内完成。
The GUI tasks show dynamic interfaces: buttons, states, app switches, and long textual feedback appear together.
GUI 三关也说明,模型要处理的是动态界面:按钮、页面状态、跨应用切换和长文本反馈会同时出现。
The story is not just a new model name; it puts multimodality, tools, and GUI automation onto the same cost curve.
因此,Step 3.7 Flash 的报道价值,不只是一个新模型名,而是把多模态、工具和 GUI 自动化放进同一条成本曲线。
The next question is whether these abilities remain stable outside demos, with long context and many tools.
后续要验证的,是这些能力在非演示任务、长上下文和多工具链里是否仍然稳定。
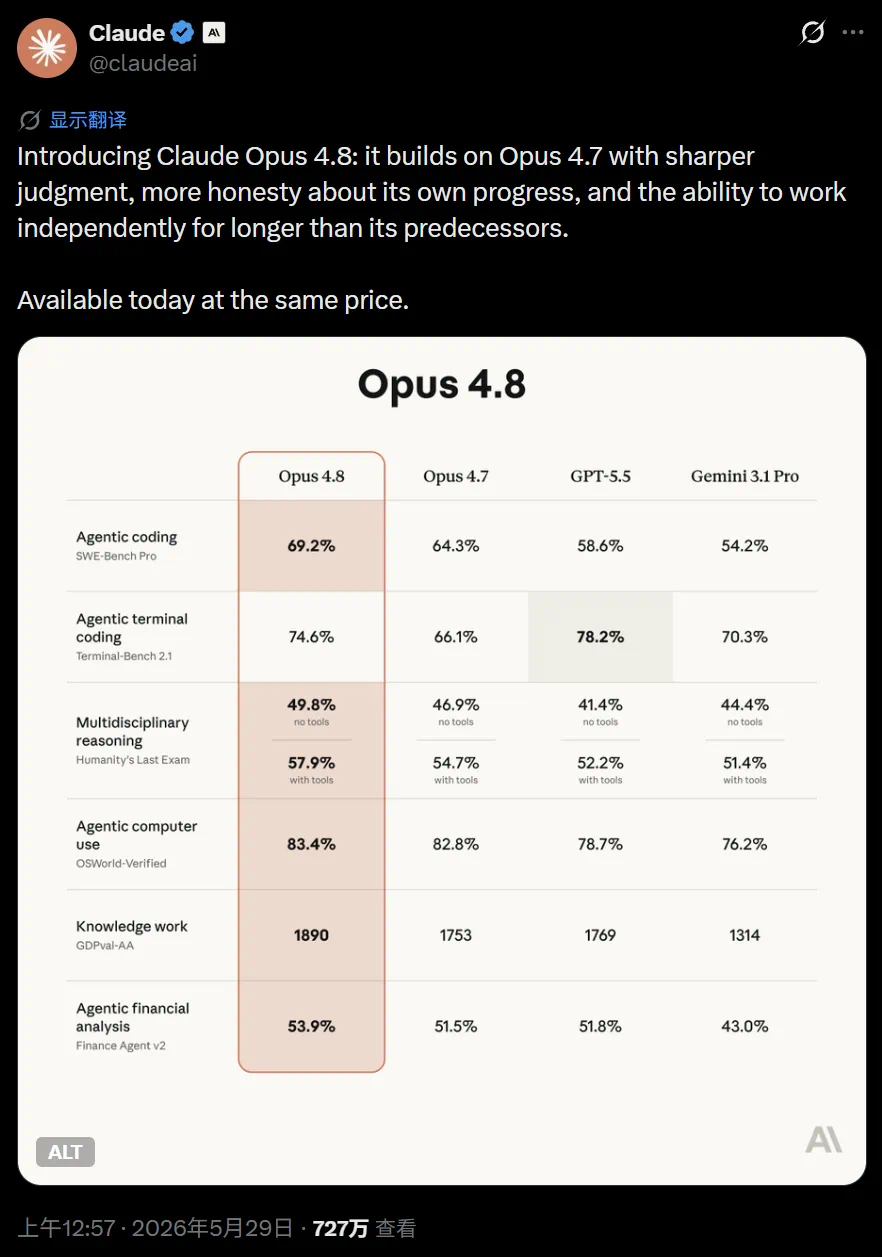
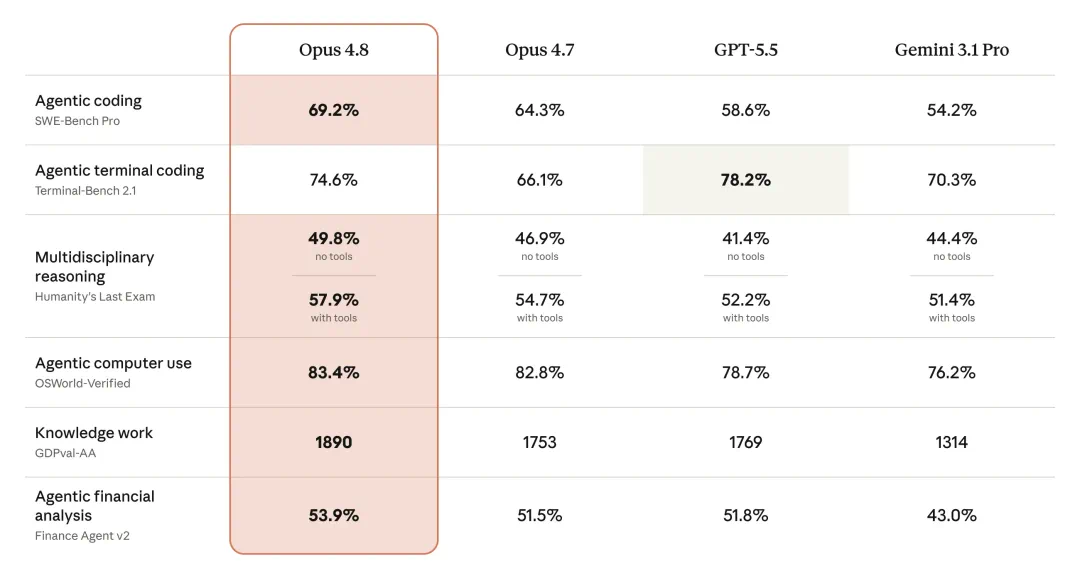
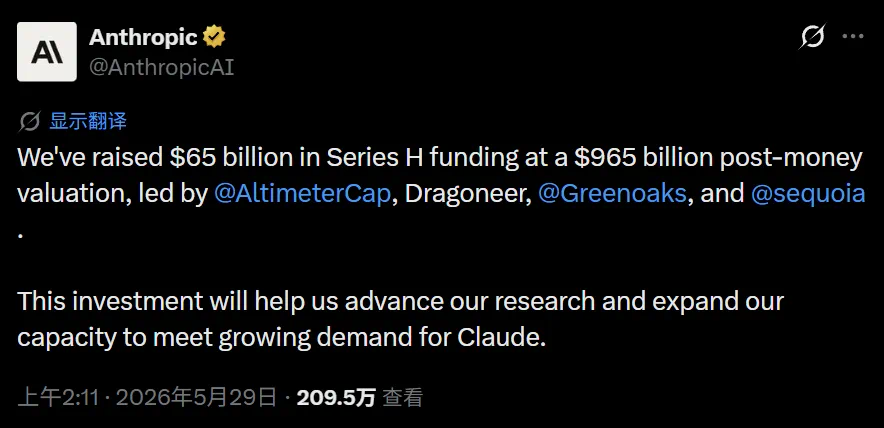
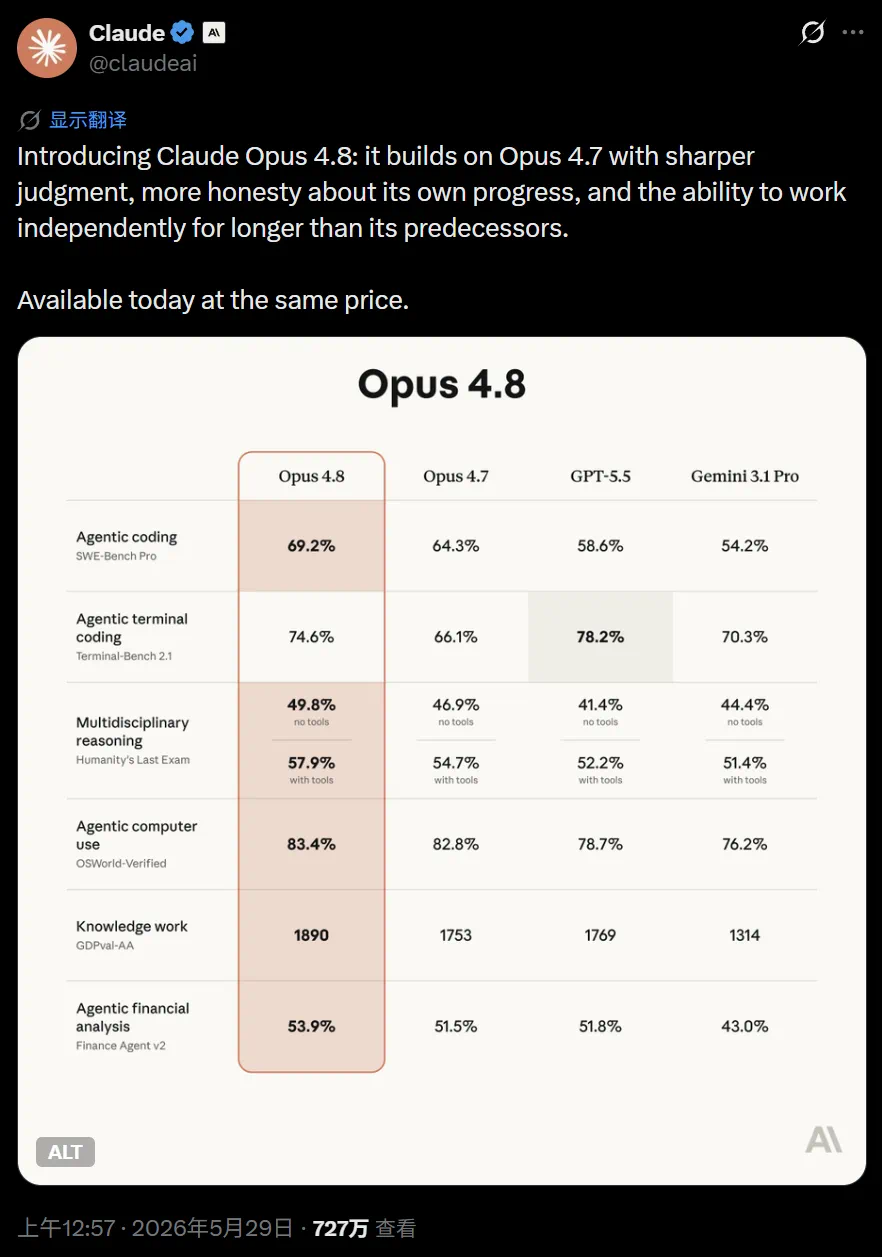
The article reports the launch of Claude Opus 4.8 and a much higher Anthropic valuation.
这篇文章报道的是 Claude Opus 4.8 发布,同时 Anthropic 的估值被推到一个更夸张的高度。
Opus 4.8 is described as an update on 4.7, focused on judgment, honesty, and longer autonomous work.
Opus 4.8 被描述为建立在 4.7 之上的小版本更新,重点是判断力、诚实性和更长时间的独立工作。
The reported benchmarks cover coding, agents, reasoning, and knowledge work, with gains over prior models.
文章列出的基准覆盖编程、智能体、逻辑推理和知识工作,显示多项指标相对前代提升。
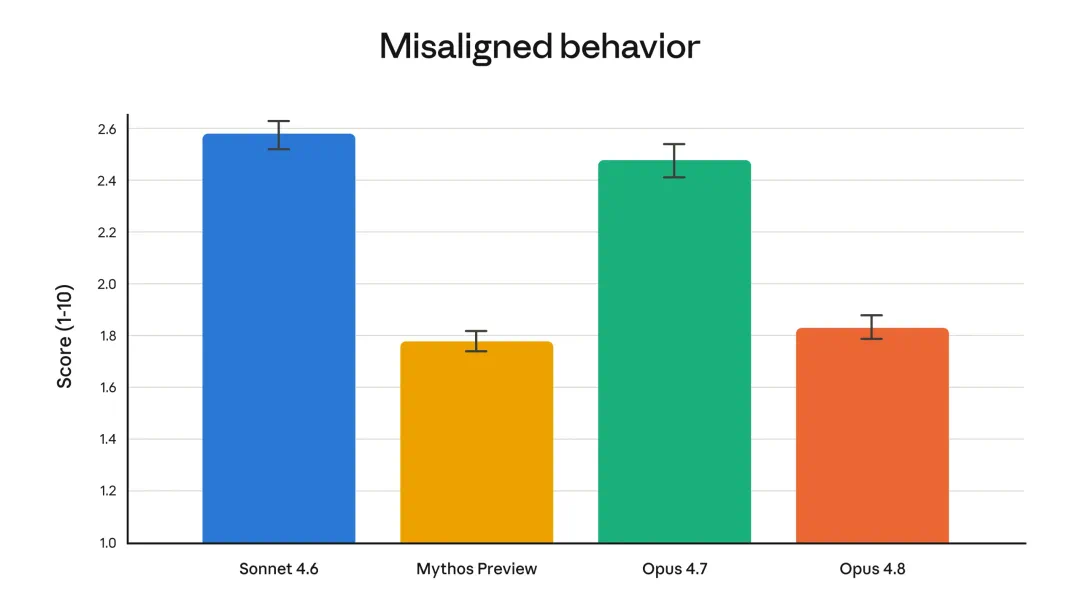
The article also notes mixed user reactions: some see better reliability, others see modest changes.
但文章也保留了用户分歧:有人觉得可靠性提高,也有人觉得小版本更新的体感并不明显。
Honesty is a repeated theme: the model is said to make fewer unsupported claims of progress.
诚实性是文章反复强调的一点:模型更少在证据不足时自信宣布已经完成。
The bigger product change is in Claude Code, where dynamic workflows can plan tasks and launch many subagents.
更大的产品变化在 Claude Code,动态工作流让模型规划任务,并启动大量并行子智能体。
The article also mentions effort control, letting users choose how much reasoning resource Claude spends.
文章还提到 claude.ai 的投入度控制,用户可以调节模型在任务中投入多少推理资源。
The financing section says Anthropic raised 65 billion dollars at a 965 billion dollar post-money valuation.
融资部分同样关键:文章称 Anthropic H 轮融资 650 亿美元,投后估值 9650 亿美元。
The story is both a model update and a sign that frontier AI keeps raising compute and capital demands.
所以这条新闻一边是模型能力更新,一边是前沿 AI 公司继续把算力和资本需求推高。
This article covers ModelBest and OpenBMB's edge AI open-source week.
这篇文章讲的是面壁智能和 OpenBMB 的端侧大模型开源周。
The article frames the five daily releases as a system, not isolated projects.
文章把五天连续发布解释为一套技术组曲,而不是几个孤立项目。
The stack includes low-bit training, small edge models, a training framework, an agent OS, and datasets.
这套组合包括低比特训练、端侧小模型、训练框架、智能体操作系统和数据集。
The central claim is that edge AI competition is full-stack engineering, not one isolated capability.
文章最核心的判断是,端侧 AI 的竞争不是某个单点能力,而是全链路工程。
MiniCPM5-1B is presented as a compact model with high capability density.
其中 MiniCPM5-1B 被写成“小钢炮”式模型,强调小参数量里的能力密度。
BitCPM-CANN, ForgeTrain, and UltraData map to low-bit training, infrastructure, and data supply.
BitCPM-CANN、ForgeTrain 和 UltraData 则分别对应低比特训练、训练基础设施和数据供给。
PilotDeck connects models to an agent operating system, so the focus is interaction as well as weights.
PilotDeck 把端侧模型接到智能体操作系统,说明文章关注的是应用交互,而不只是模型权重。
The caveat is that the article is promotional; the real value depends on repos, licenses, and third-party tests.
需要注意的是,文章宣传色彩很强,真实价值还要看仓库、许可证和第三方复测。
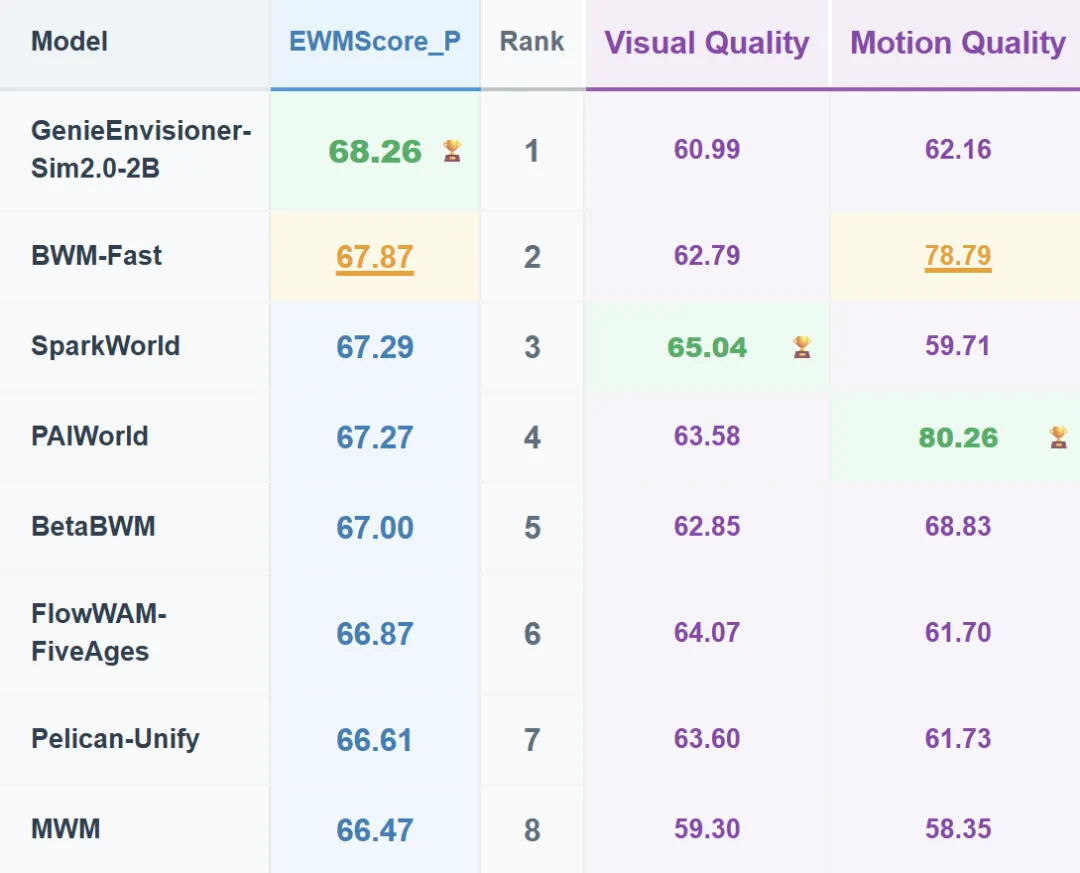
The article reports that Agibot's GE-Sim 2.0 won the overall WorldArena world-model track.
这篇文章报道智元 GE-Sim 2.0 拿下 WorldArena 世界模型赛道总成绩冠军。
WorldArena is described as a demanding benchmark with 16 metrics and three real application tasks.
WorldArena 被文章写成具身世界模型的高强度评测,覆盖 16 项指标和 3 类真实应用任务。
The article stresses that GE-Sim 2.0 was not specially optimized for the contest, only lightly fine-tuned.
文章强调,GE-Sim 2.0 没有为赛题特别调优,只在榜单数据上做了基础微调。
Its claimed capabilities include long-horizon generation, multi-view generation, proprioception, near-real-time inference, and reward judgment.
它补齐的功能包括长时序生成、多视角生成、本体状态、近实时推理和奖励判别。
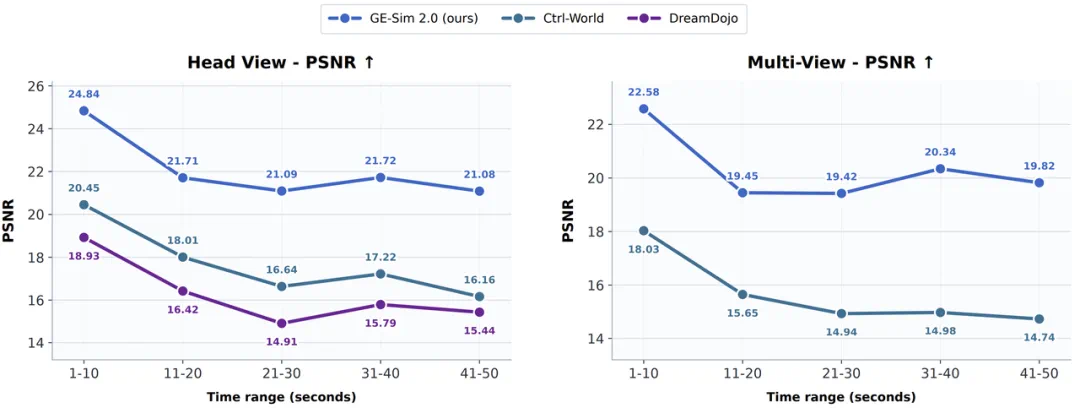
Long-horizon rollout is a key point, with reported quality decay weaker than baselines over 40 to 50 seconds.
长时序推演是文章的重点之一,报道称 40 到 50 秒片段的质量衰减弱于基线。
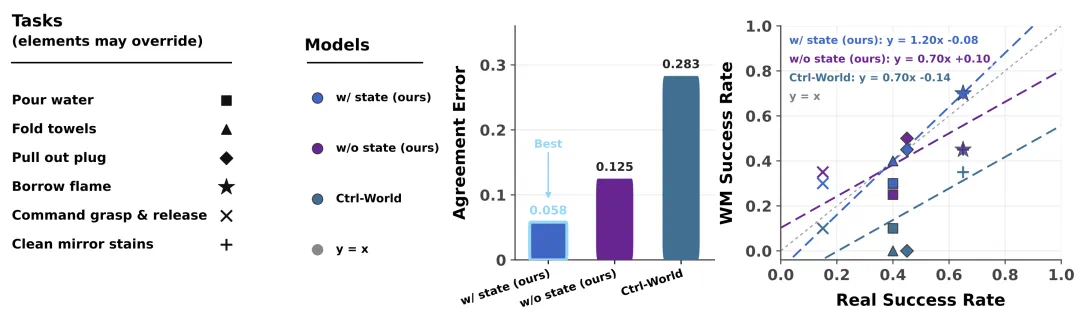
Another key point is closed-loop evaluation: the model must reflect real physical outcomes, not only produce good visuals.
另一个关键是闭环评测:世界模型要能反映真实物理过程,而不只是生成好看的画面。
The article also says a reward model filters high-quality rollouts and feeds them back to policy models.
文章还提到奖励模型会筛选高质量 rollout,把世界模型生成的数据回流给策略模型。
This points to world models moving from visual prediction toward simulation environments for robot training.
这说明世界模型的目标正在从预测画面,转向为机器人训练提供可试错的仿真环境。
A benchmark win is not deployment success; the real value depends on stable transfer to physical robots.
但榜单冠军还不是部署成功,真实价值仍要看后续机器人策略能否稳定迁移到物理世界。
This article is about Meta's ATLAS, which turns math textbooks into Lean-verifiable code.
这篇文章讲的是 Meta 的 ATLAS:用 AI 把数学教材翻译成 Lean 可验证代码。
Its goal is not natural-language proof, but formal proofs that Lean can check step by step.
它的目标不是写自然语言证明,而是生成可以被 Lean 逐步检查的形式化证明。
The article says ATLAS covers 26 open textbooks and generated over 630 thousand lines of code.
文章称项目覆盖 26 本开放教材,生成 63 万多行代码,其中 Lean 核心代码接近 48.4 万行。
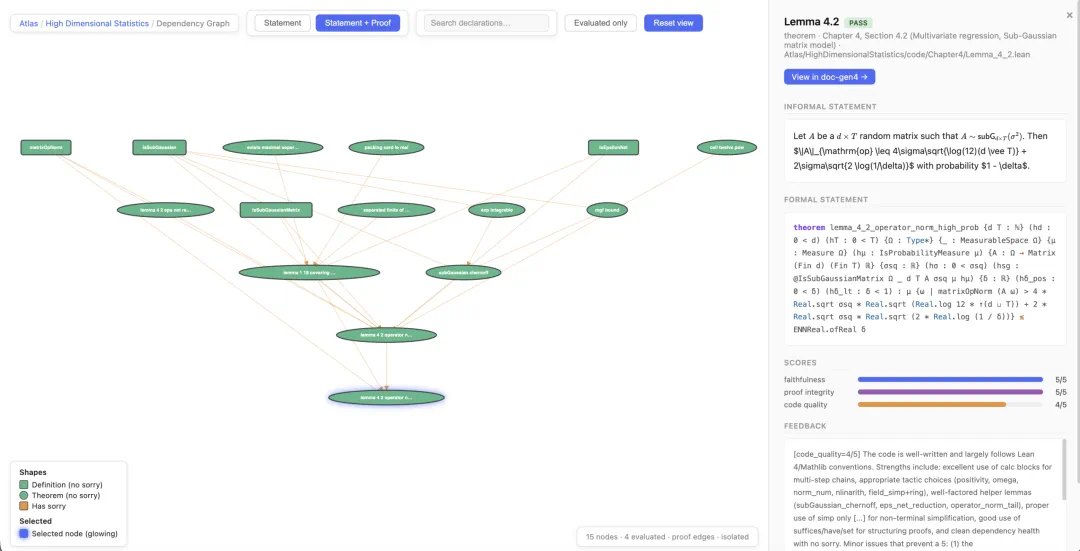
It also provides a browser for comparing informal text, formal code, and theorem dependencies.
它还提供浏览器,让人比较非正式原文、形式化版本和定理依赖。
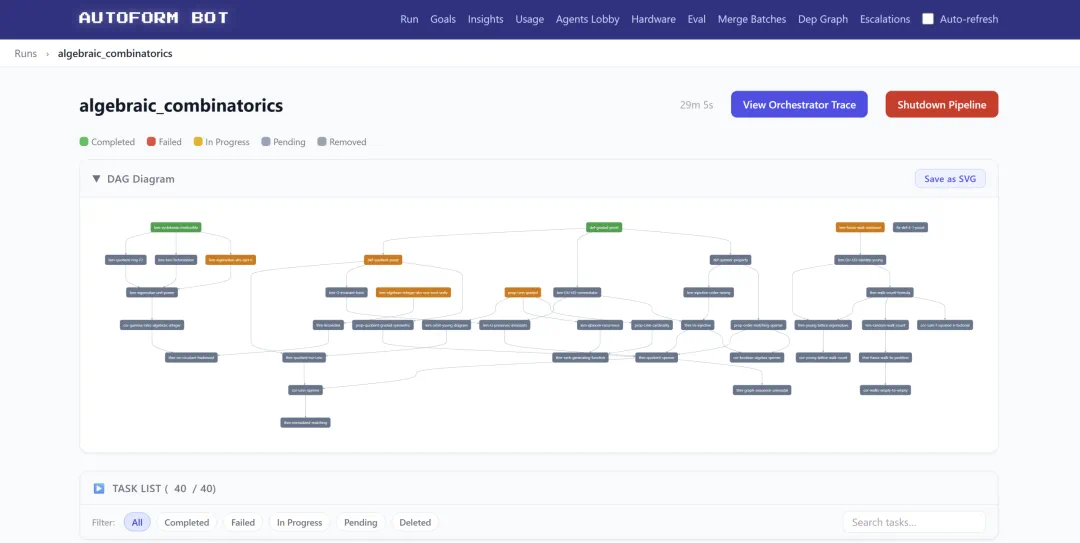
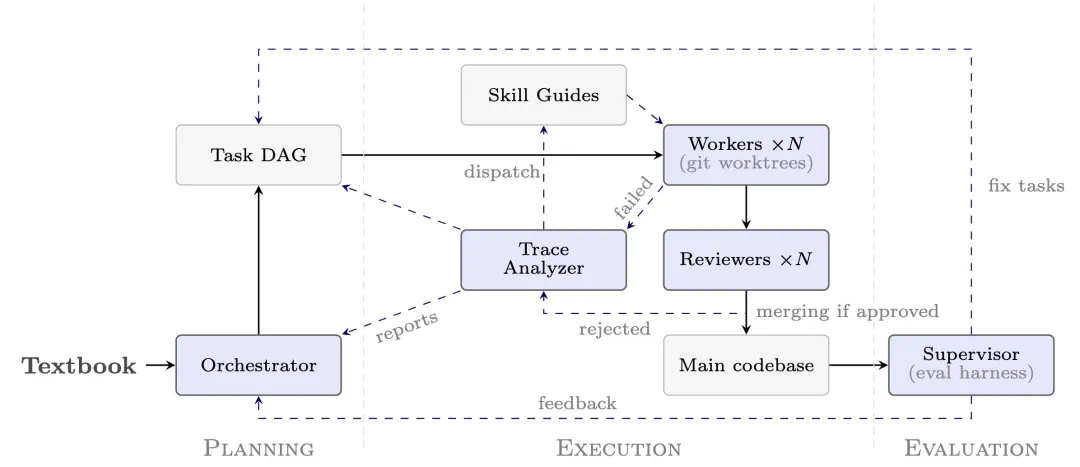
AutoformBot is the generation engine: orchestrators split tasks, workers prove them, and reviewers check progress.
AutoformBot 是生成引擎:编排者拆解教材,工作者写证明,审核者和监督者检查进度。
Dependencies matter because proving one theorem often relies on prior lemmas already being formalized.
任务之间的依赖关系也很关键,因为一个定理能否证明,往往取决于前置引理是否已经形式化。
The article says the process consumed over 183 billion tokens, showing how costly large-scale formalization is.
文章强调,整个过程消耗超过 1830 亿 token,说明规模化形式化非常昂贵。
The risk is that passing Lean is not the same as perfect mathematical quality; models may weaken targets.
风险在于,Lean 通过不等于数学质量完美,模型可能弱化目标或绕开真正证明。
ATLAS matters because it shifts AI math from proving to verifying, organizing, and maintaining proof libraries.
所以 ATLAS 的意义,是把 AI 数学从“能证明”推进到“如何验证、整理和维护证明库”。
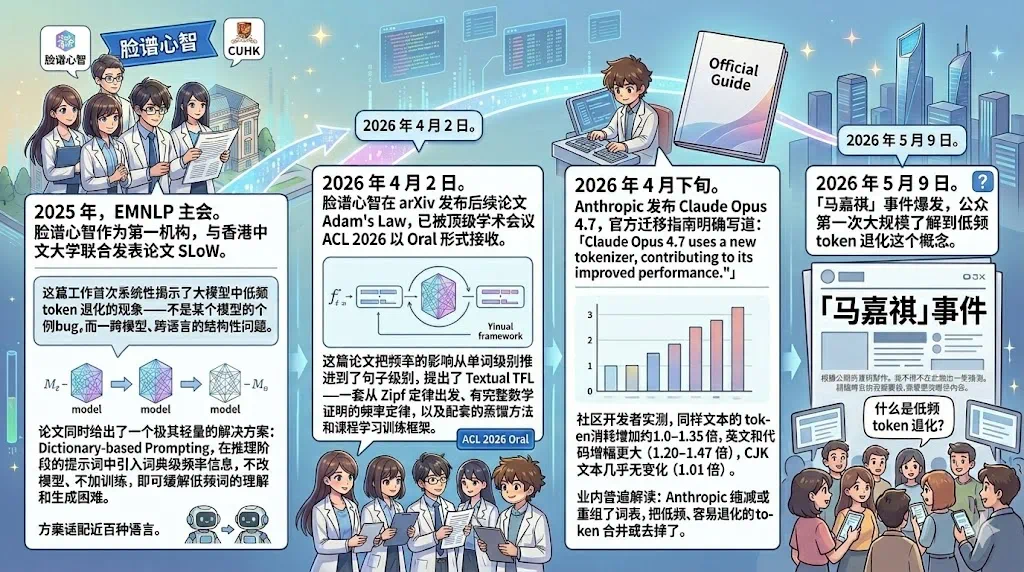
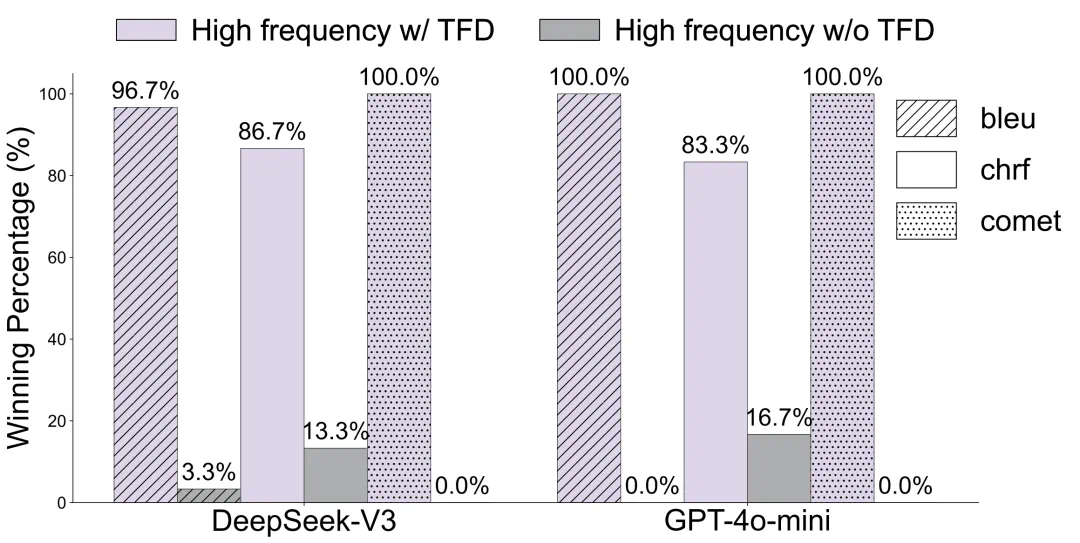
The article starts with the Ma Jiaqi name failure and discusses low-frequency expression problems in LLMs.
这篇文章从“马嘉祺”名字翻车讲起,讨论大模型的低频表达问题。
The key symptom is that a model knows the person, but repeatedly writes the name wrong.
关键现象是,模型知道人物信息,却反复写错名字里的两个字。
The article links it to low-frequency token degradation, where rare tokens drift during post-training.
文章把这件事归到低频 token 退化:后训练数据里少见的 token,输出层可能发生偏移。
SLoW addresses rare words with dictionary-based prompting for long-tail terms.
SLoW 论文先从单词级别处理低频问题,用词典提示帮助模型处理长尾词。
Adam's Law extends the idea to sentence-level frequency, arguing that frequent phrasings are easier for models.
Adam's Law 再把问题推进到句子级,认为高频表达方式通常让模型表现更稳。
The article says that rewriting prompts into frequent forms can raise some math-reasoning accuracy.
文章举例说,仅靠把输入改成高频表述,一些数学推理准确率就能明显提高。
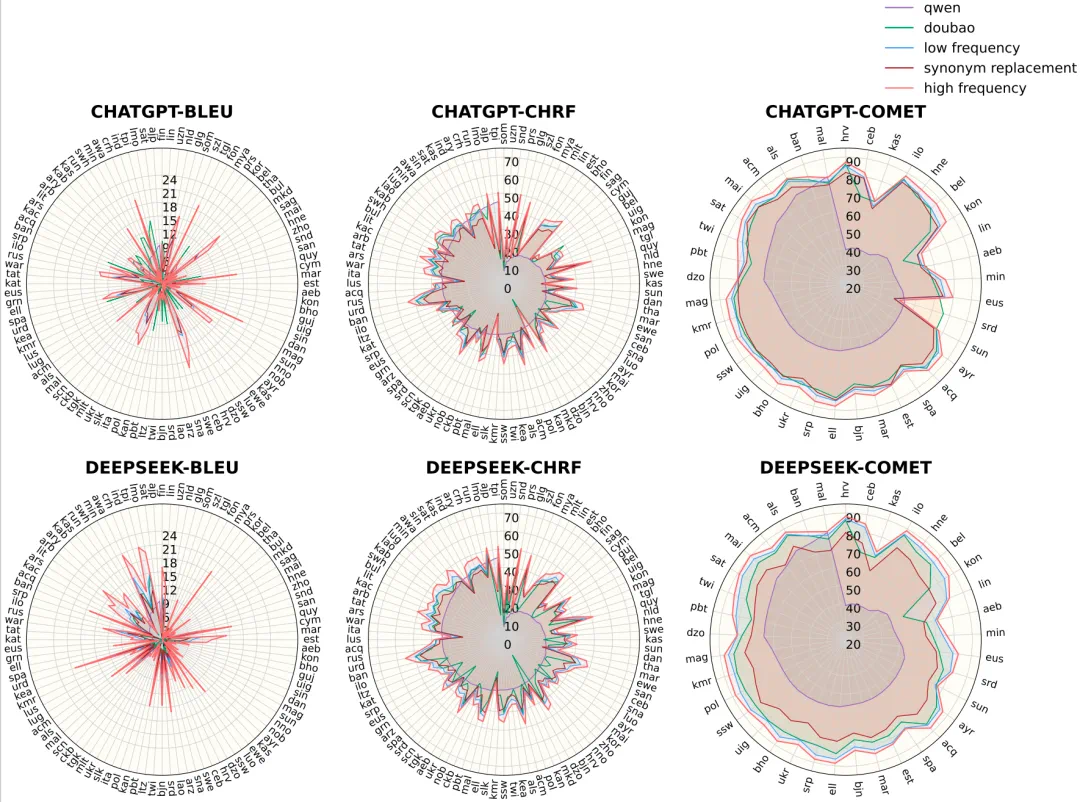
Low-frequency issues also matter for translation and low-resource languages, where rare terms are unstable.
低频问题也会影响翻译和少数语言,因为长尾词往往是模型最不稳定的位置。
Industry may address this with tokenizer changes, synthetic data, and better training coverage.
产业侧可能会用 tokenizer 调整、合成数据和训练覆盖来补这个洞。
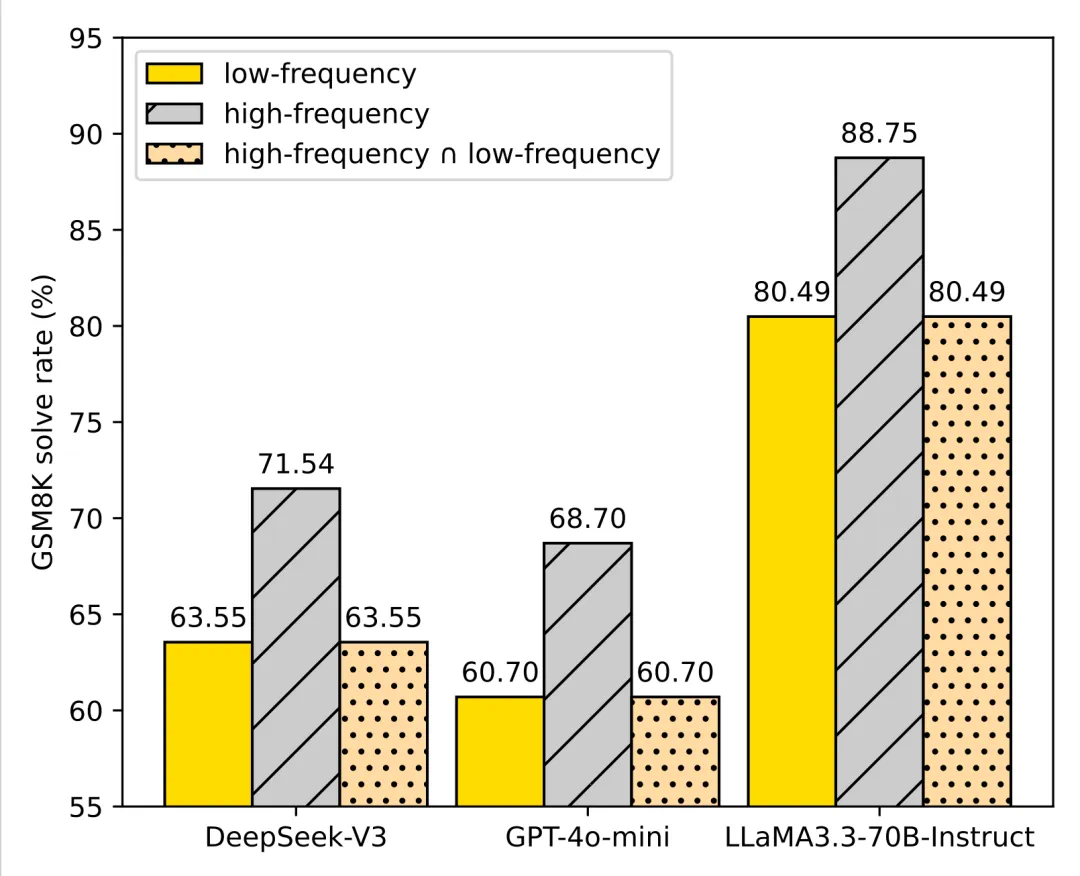
The main warning is that reliability is not only knowing facts, but reliably producing long-tail answers.
文章最大的提醒是,模型可靠性不只看“大模型懂不懂”,也要看它能不能稳定说出长尾答案。
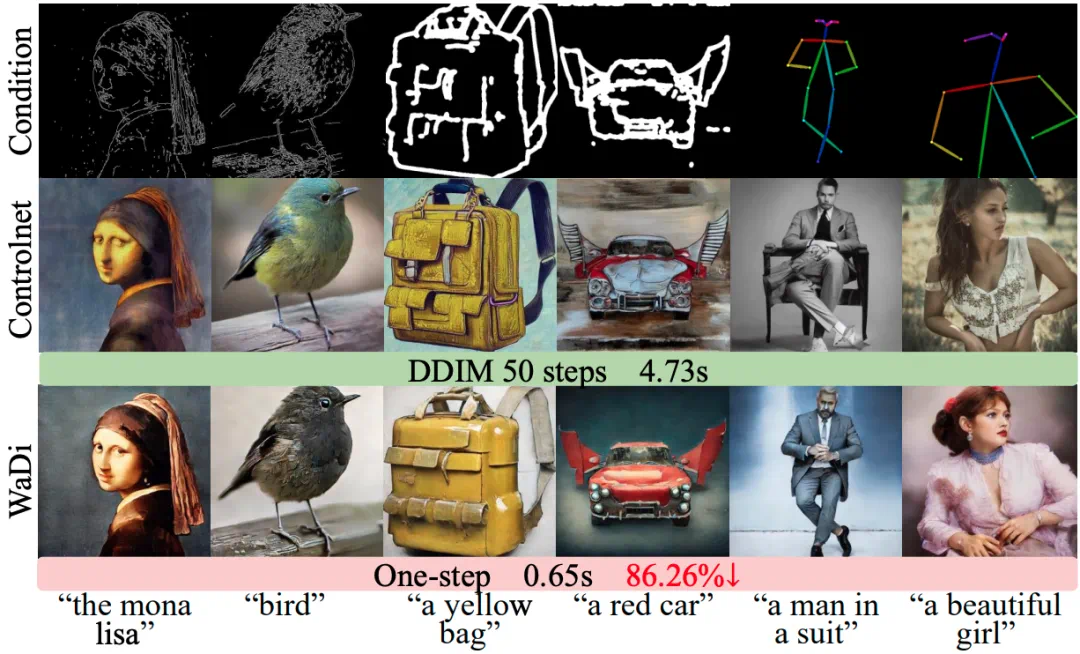
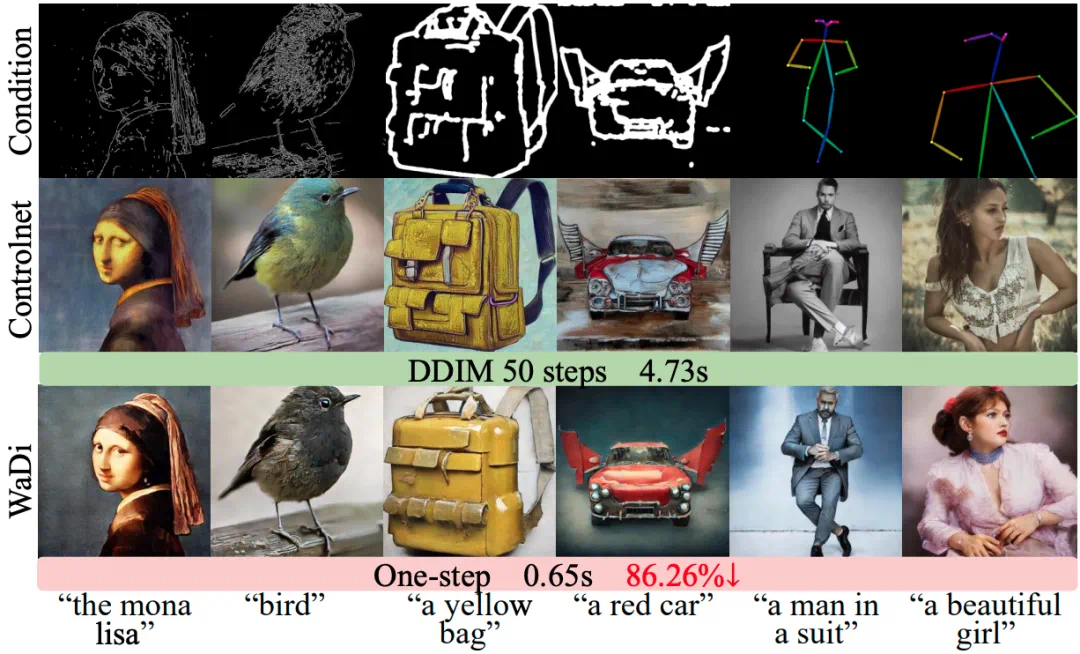
WaDi asks whether diffusion models can produce high-quality images in a single step.
WaDi 这篇 CVPR 论文关注一个问题:扩散模型能不能在一步里生成高质量图像。
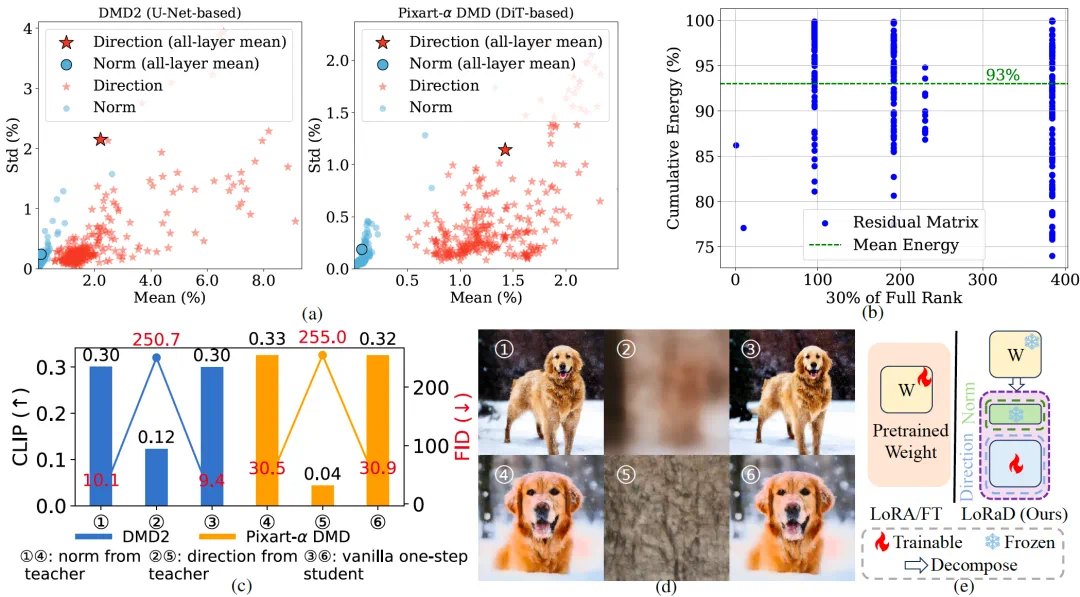
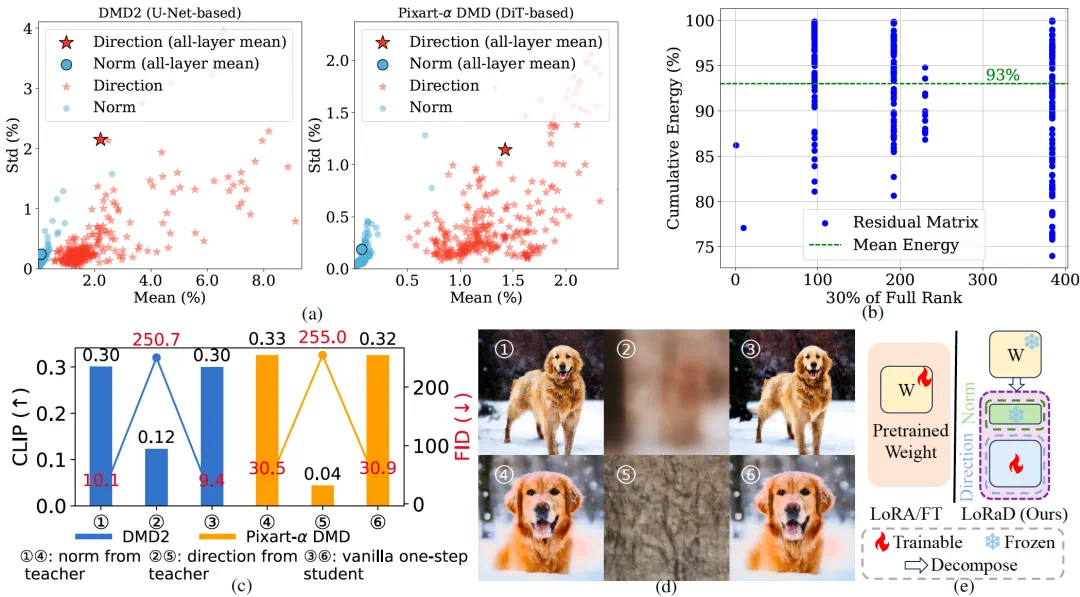
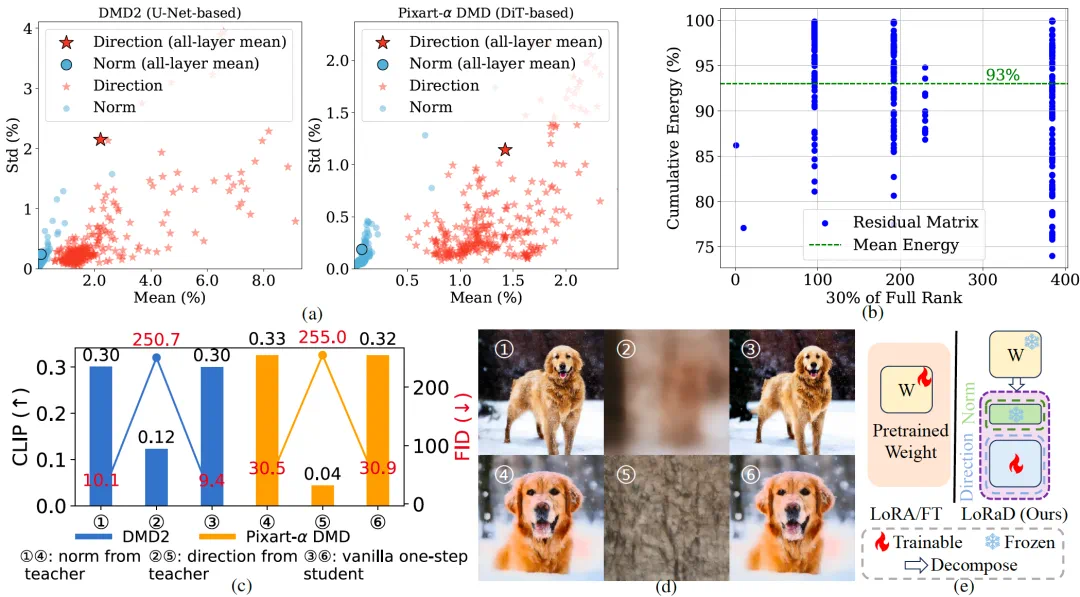
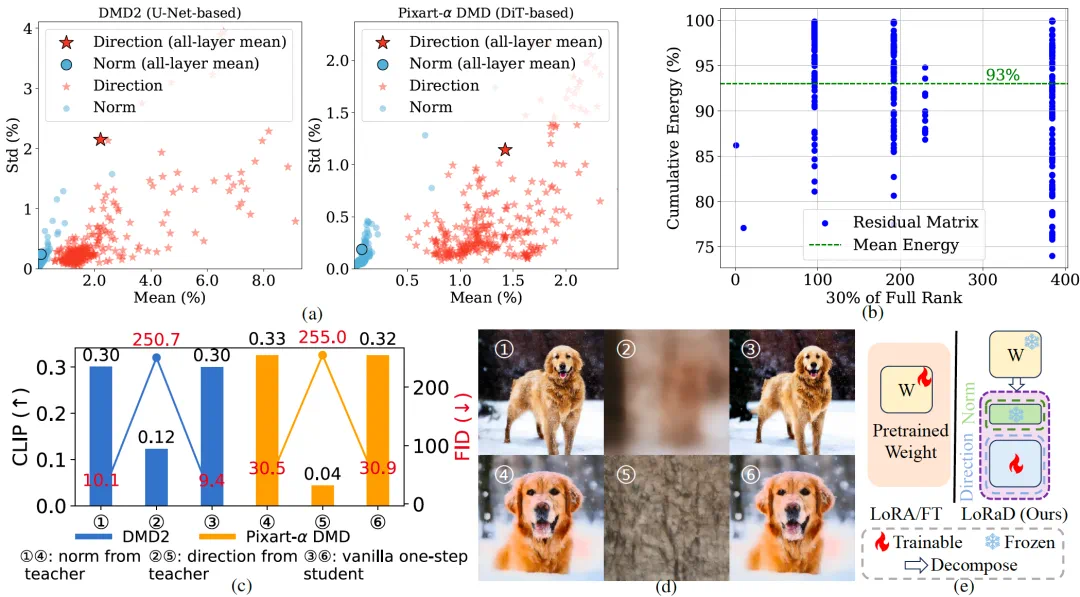
The starting point is a weight-change observation: direction shifts more than norm.
论文的起点是观察蒸馏前后权重变化:方向变化比范数变化更明显。
This shifts the question from how much weights change to where their directions rotate.
这让作者把蒸馏重点从“改多少权重”转到“把权重方向转到哪里”。
LoRaD implements this idea by modeling pretrained weight directions with low-rank rotations.
LoRaD 就是这个思路的模块:用低秩旋转矩阵建模预训练权重方向。
WaDi places LoRaD inside variational score distillation so the student aligns with the multi-step teacher.
WaDi 再把 LoRaD 放进变分得分蒸馏,让学生模型对齐多步教师分布。
The article says it trains roughly ten percent of parameters while preserving or improving one-step quality.
文章称,它只训练大约一成参数,却能保持或提升一步生成质量。
In qualitative comparisons, WaDi shows more stable details on people, objects, and complex prompts.
定性对比里,WaDi 在人物、物体和复杂提示上展示了更稳定的细节。
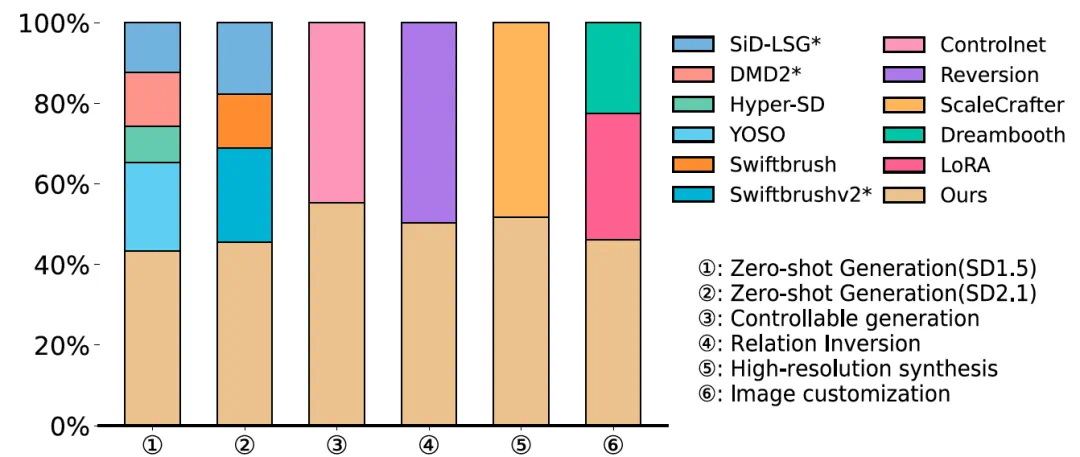
Downstream tests include controllable generation, relation inversion, and high-resolution synthesis.
下游任务也被纳入测试,包括控制生成、关系反演和高分辨率合成。
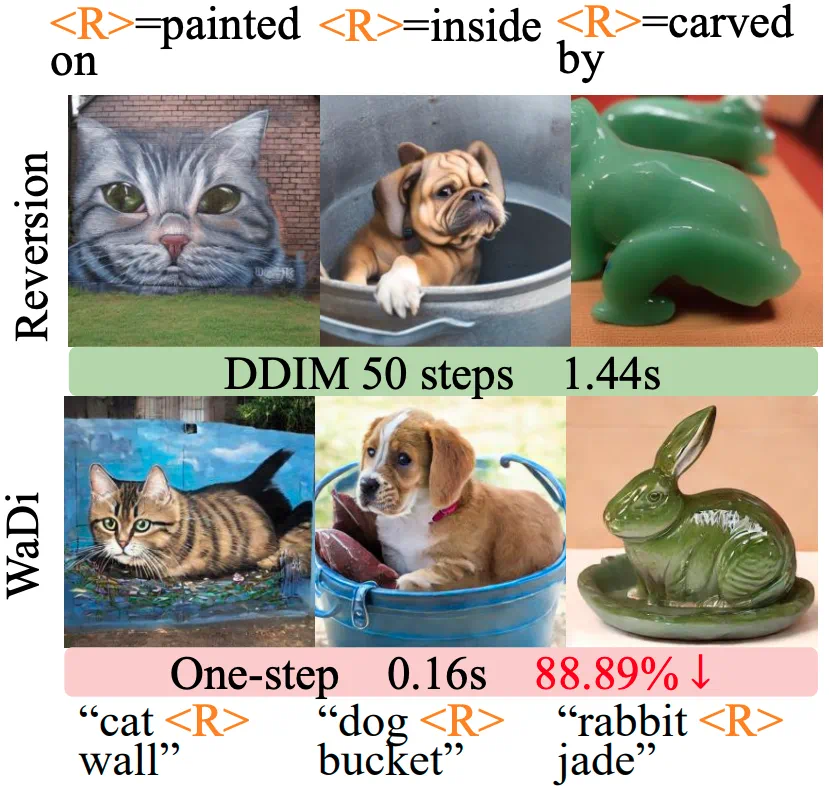
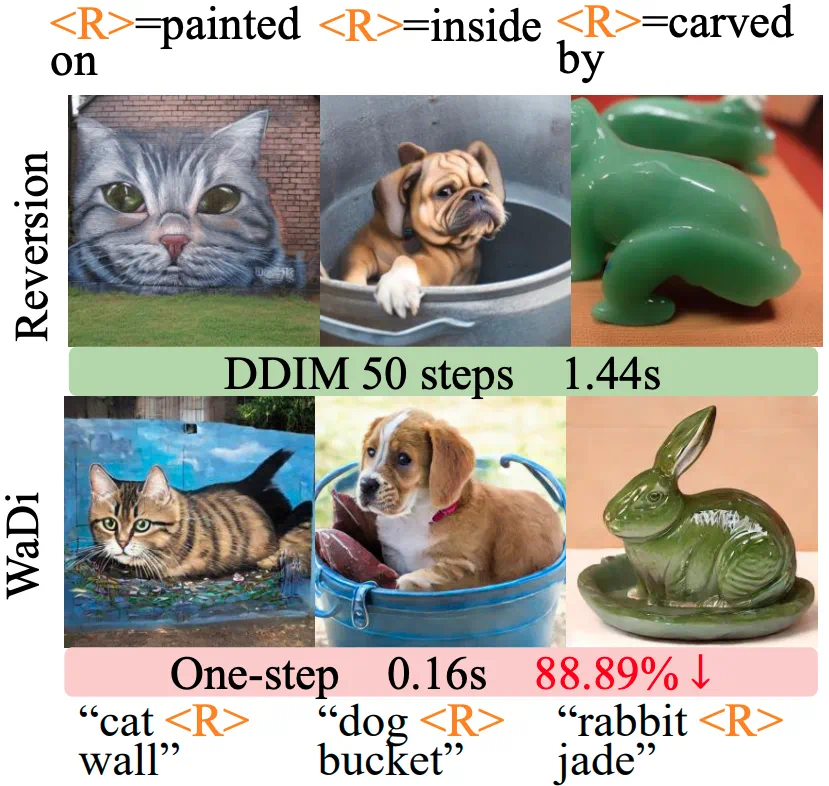
In relation inversion examples, images must reflect relations such as painted on, inside, and carved.
在关系反演示例中,图像需要准确反映 painted on、inside、carved 等空间关系。
DreamBooth examples show the method being tested for personalized generation.
DreamBooth 示例说明,方法还被放到个性化生成场景中测试。
The user study adds subjective evaluation from consistency, quality, and preference angles.
用户研究部分则从一致性、质量和偏好角度补充主观评价。
The instance examples remind us that one-step generation is about preserving relations and details, not only speed.
实例图像部分提醒我们,一步生成不只是速度问题,也要保持对象关系和细节。
The technical value is turning directional structure in distillation into a trainable module.
这篇论文的技术价值,在于把蒸馏过程里的方向结构变成可训练模块。
But it still needs reproduction and more baselines; qualitative images are not a full evaluation.
但它仍需要复现实验和更多基线验证,定性图片不能替代完整评测。
If the results hold, WaDi moves one-step diffusion closer to real-time and low-cost deployment.
如果结果成立,WaDi 会让单步扩散模型更接近实时交互和低成本部署。
More specifically, the authors decompose teacher and student weights into norm and direction, then compare how they change after distillation.
更细一点看,作者先把多步教师和单步学生的 U-Net、DiT 权重拆成范数和方向,再比较蒸馏前后的变化量。
The observation is that norms barely move, while directions change more and the residuals look low-rank.
观察结果是,范数几乎不动,方向变化却更大,而且残差矩阵呈现低秩结构。
That explains why LoRaD is not ordinary LoRA: it learns rotation angles, moving directions while preserving pretrained scales.
这就解释了为什么 LoRaD 不是普通 LoRA:它学习的是旋转角,让权重方向移动,同时尽量保留预训练权重的尺度。
In the objective, WaDi still uses teacher and fake-model structure, but inserts direction adapters on both sides.
在训练目标上,WaDi 仍然借助教师模型和虚假模型的对抗式结构,但把方向适配器放进两侧网络。
The engineering implication is fewer sampling steps without retraining all parameters.
这种做法的一个工程含义是,蒸馏后的模型可以少走采样步数,同时不必重新训练全部参数。
The controllable generation results stress that speed should not sacrifice conditions such as edges, depth, or pose.
文章中的可控生成结果强调,速度提升不能牺牲条件约束,比如边缘、深度或姿态控制。
Relation inversion tests whether the model captures spatial relations, not only visual style.
关系反演结果则考验模型是否真的理解空间关系,而不是只生成风格接近的图片。
DreamBooth tests identity preservation, whether the same cat or duck remains recognizable across prompts.
DreamBooth 场景考验个性化对象保持能力,也就是同一个猫或鸭子在不同提示下是否还像自己。
The user study adds human preference, but it still has to be read alongside metrics such as FID and CLIP.
用户研究提供的是人的偏好补充,但它仍然要和 FID、CLIP 等自动指标一起看。
WaDi is not only about nicer samples; it offers a path from explaining weight changes to building a module around that explanation.
所以 WaDi 的重点不是单张图更好看,而是提出了一个解释蒸馏权重变化、再把解释落成模块的路径。
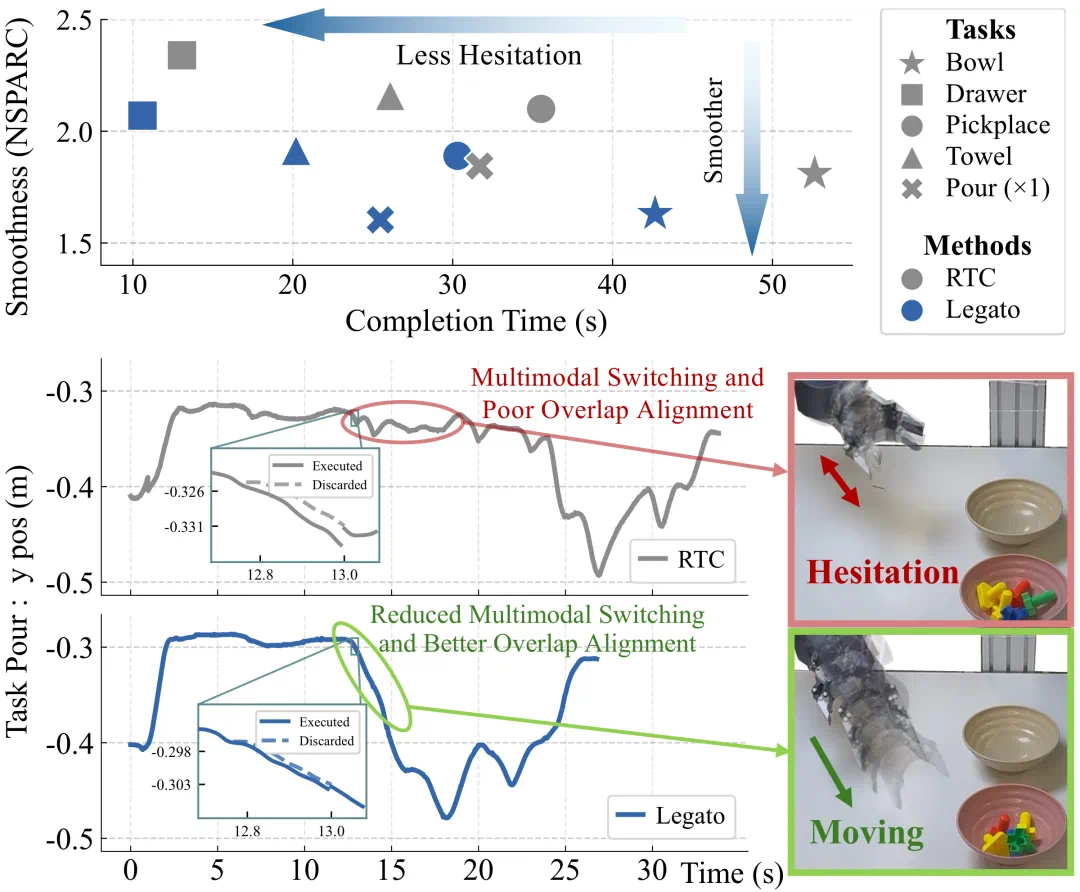
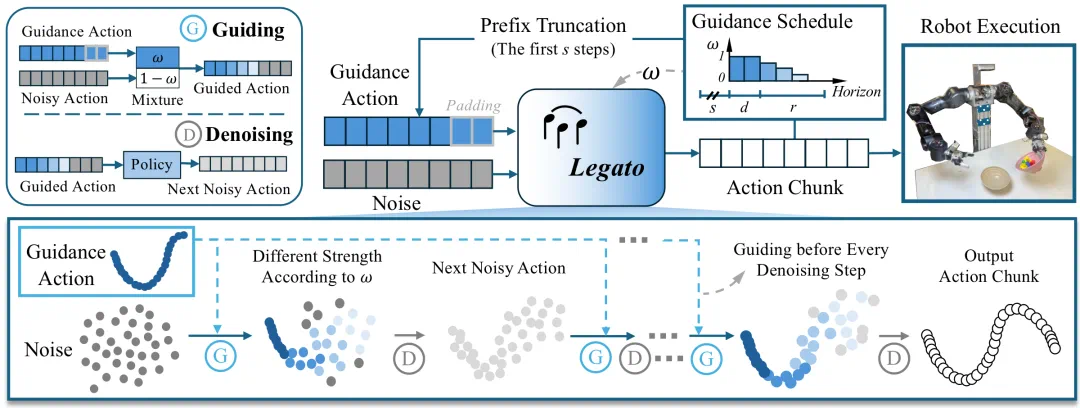
Legato addresses the seam between action chunks in robot policies.
Legato 这篇 RSS 论文解决的是机器人动作分块里的“接缝”问题。
The article says action chunking can cause pauses, jitter, or intent switches between chunks.
文章说,现有动作分块会让机器人在两段动作交界处停顿、抖动,甚至切换意图。
Legato trains the model to continue from known prefixes, instead of patching continuity only at inference.
Legato 的做法,是让模型在训练时就学习如何接着已知前缀继续生成动作。
The real-robot demo shows continuous execution on tasks such as pouring and stacking bowls.
在真实机器人演示里,可以看到方法对倒东西、叠碗等操作的连续执行效果。
The article reports gains on five real-world manipulation tasks, with details left to the paper.
文章称它在五个真实操作任务上超过现有方法,但具体统计还要看论文原文。
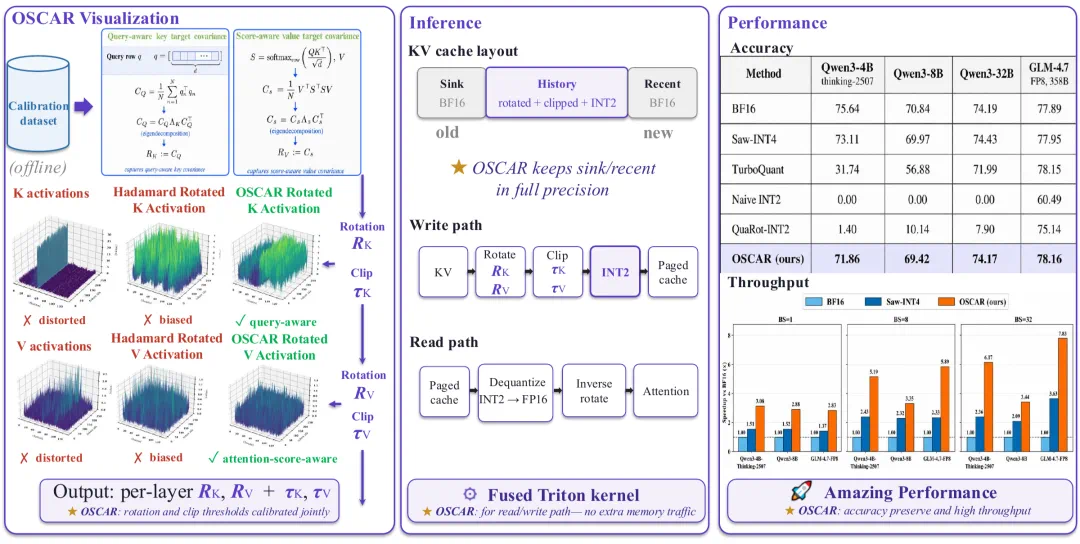
OSCAR targets KV Cache memory and bandwidth costs in long-context inference.
OSCAR 这篇论文解决的是长上下文推理里的 KV Cache 显存和带宽问题。
Its core idea is not reconstructing raw vectors, but preserving directions attention actually reads.
它的核心不是重建原始向量,而是保留 attention 真正会读取的方向。
The system keeps BF16 sink and recent windows, while compressing the long history into rotated INT2.
系统结构保留 BF16 sink 和 recent window,中间最长的历史段压成旋转后的 INT2。
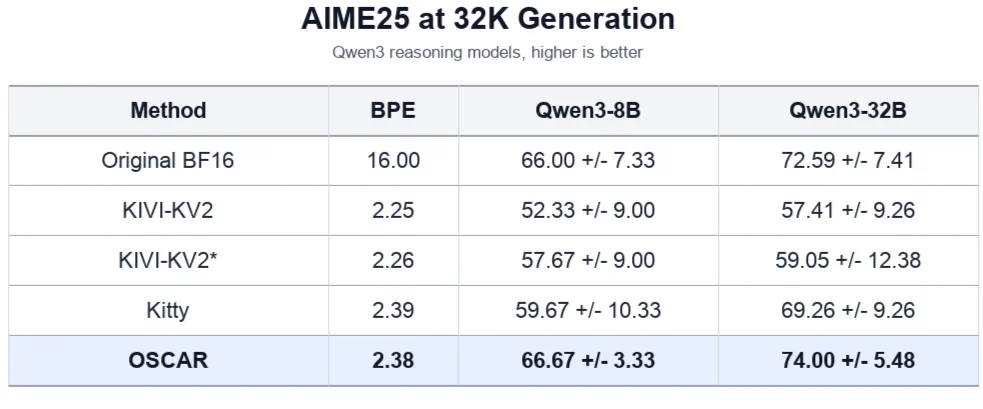
The article says OSCAR approaches BF16 on hard reasoning tasks and beats TurboQuant on Qwen3-4B-Thinking.
文章称在困难推理任务上,它能接近 BF16,并在 Qwen3-4B-Thinking 上显著超过 TurboQuant。
The practical value is that stable 2-bit KV serving could reduce long-context inference cost.
系统价值在于,如果 2-bit KV 真能稳定服务,长上下文推理的成本会明显下降。
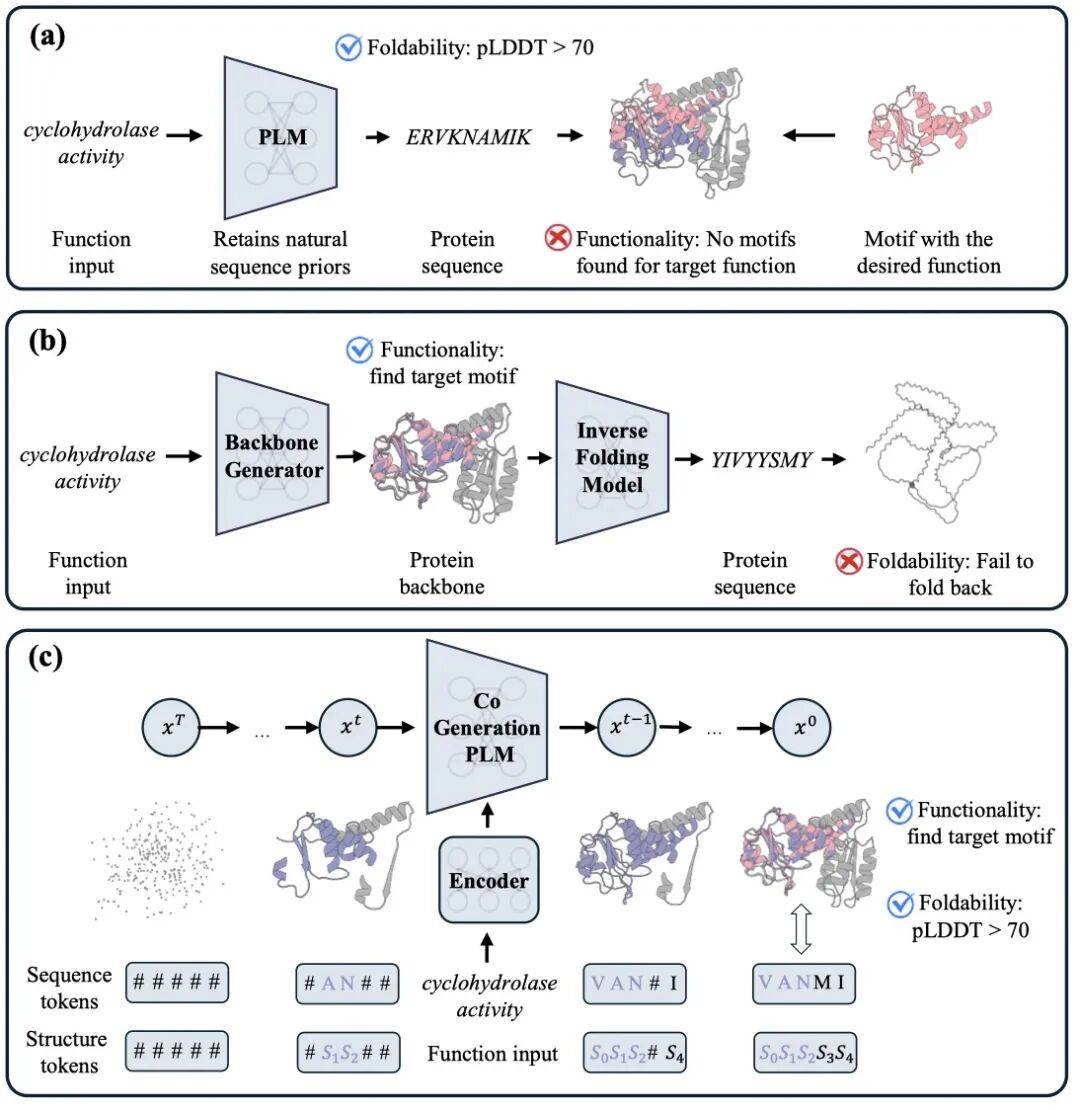
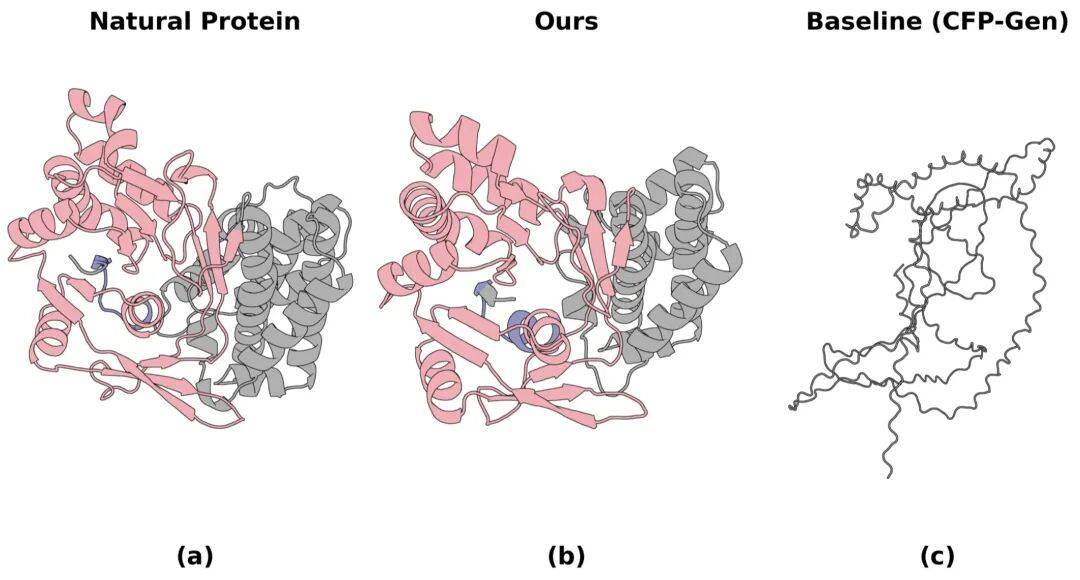
CodeFP focuses on de novo functional protein design, targeting both function and foldability.
CodeFP 这篇 ICML 论文关注从头功能蛋白设计,目标是同时满足功能和可折叠性。
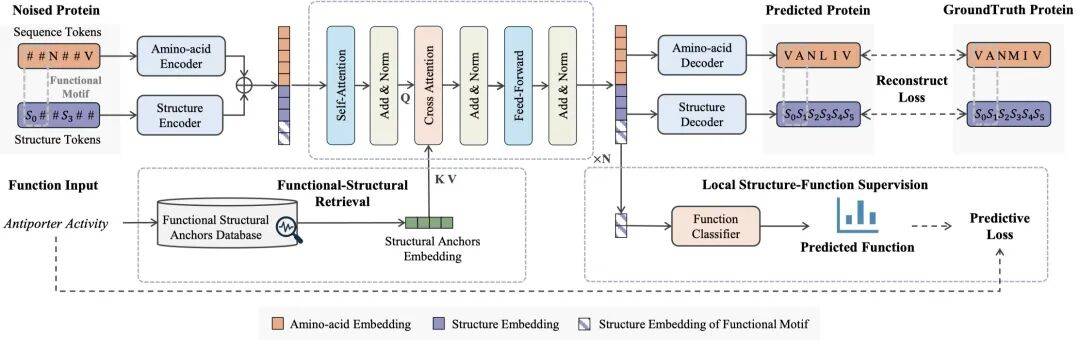
It represents proteins as both sequence tokens and structure tokens, rather than generating along one path.
它把蛋白表示为序列 token 和结构 token,而不是只沿一条路径生成。
During discrete diffusion denoising, the two token types update alternately and constrain each other.
在离散扩散去噪中,两类 token 交替更新,让结构和功能互相约束。
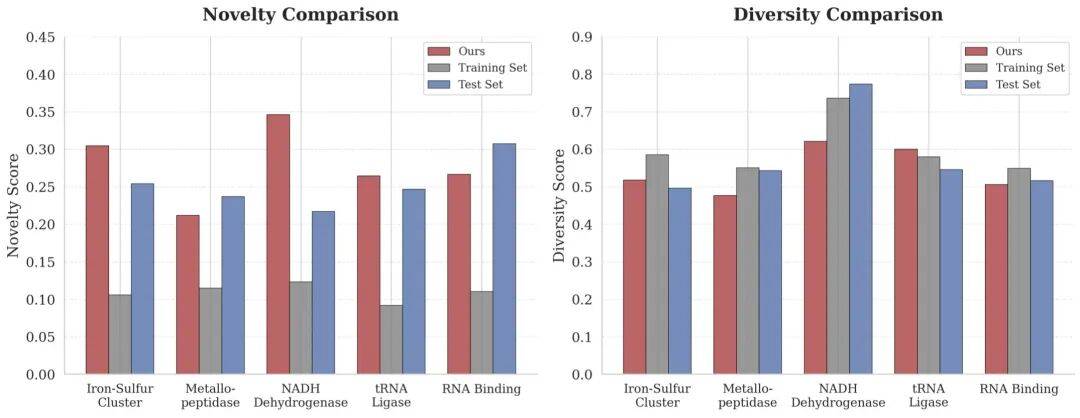
The article says CodeFP improves F1-Macro by 9.1 percent on out-of-distribution function combinations.
文章称,在分布外功能组合上,CodeFP 的 F1-Macro 比基线提升 9.1%。
But computational metrics are not wet-lab validation; real drug-design value depends on expression, stability, and function tests.
但计算指标还不是湿实验验证,真实药物研发价值仍要看表达、稳定性和功能实验。
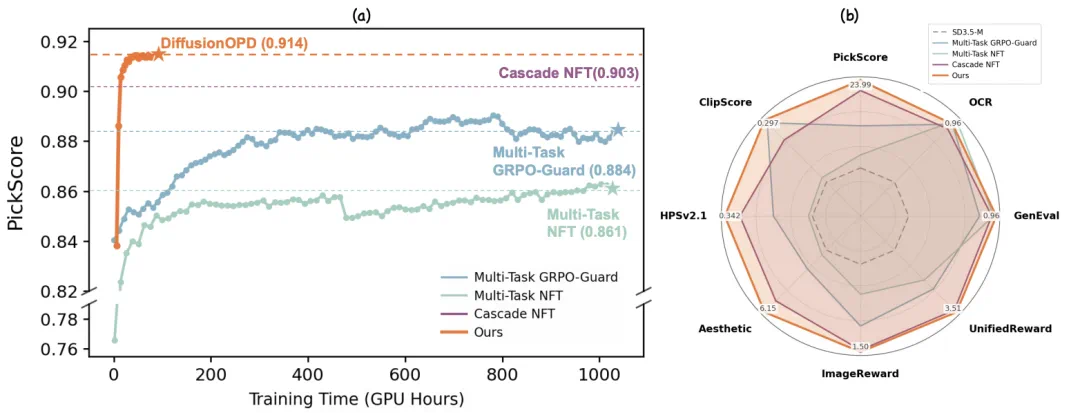
DiffusionOPD targets reward conflicts in multi-task RL for diffusion models.
DiffusionOPD 解决的是扩散模型多任务强化学习里的奖励冲突。
It first trains single-task teachers for layout, OCR, and aesthetics, then distills them into one student.
它先为构图、OCR 和美学等任务训练单任务教师,再把能力蒸馏给统一学生模型。
The key is on-policy distillation: teachers supervise states generated by the student itself.
关键是在线策略蒸馏:教师在学生自己生成的去噪状态上提供监督。
The article says it converges faster and reaches a higher ceiling than multi-task RL baselines.
文章称它比多任务 RL 基线收敛更快,上限也更高。
The point is to teach one generator layout, text, and aesthetics without being pulled off course by one reward.
这条线的意义,是让一个图像生成模型同时学会构图、文字和美学,而不被单一奖励拖偏。